






文本匹配模型实验报告-text2vec
尽管基于BERT的模型在NLP诸多下游任务中取得了成功,直接从BERT导出的句向量表示往往被约束在一个很小的区域内,表现出很高的相似度,因而难以直接用于文本语义匹配。为解决BERT原生句子表示这种“坍缩”现象,Su[21]提出了一种排序Loss的句向量表示模型——CoSENT,
通过在目标领域的监督语料上Fine-tune,使模型生成的句子表示与下游任务的数据分布更加适配。
在句子语义匹配(STS)任务的实验结果显示,同等设置下CoSENT相比此前的Sentence-BERT大幅提升了5%。
1. 背景
句向量表示学习在自然语言处理(NLP)领域占据重要地位,许多NLP任务的成功离不开训练优质的句子表示向量。特别是在文本语义匹配(Semantic Textual Similarity)、文本向量检索(Dense Text Retrieval)等任务上,
模型通过计算两个句子编码后的Embedding在表示空间的相似度来衡量这两个句子语义上的相关程度,从而决定其匹配分数。
尽管基于BERT的模型在诸多NLP任务上取得了不错的性能(通过有监督的Fine-tune),但其自身导出的句向量(不经过Fine-tune,对所有词向量求平均)质量较低,甚至比不上Glove的结果,因而难以反映出两个句子的语义相似度[1][2][3][4]。
我们在研究的过程中进一步分析了BERT导出的句向量所具有的特性,证实了以下两点:
- BERT对所有的句子都倾向于编码到一个较小的空间区域内,这使得大多数的句子对都具有较高的相似度分数,即使是那些语义上完全无关的句子对(如下图所示),我们将此称为BERT句子表示的“坍缩(Collapse)”现象。
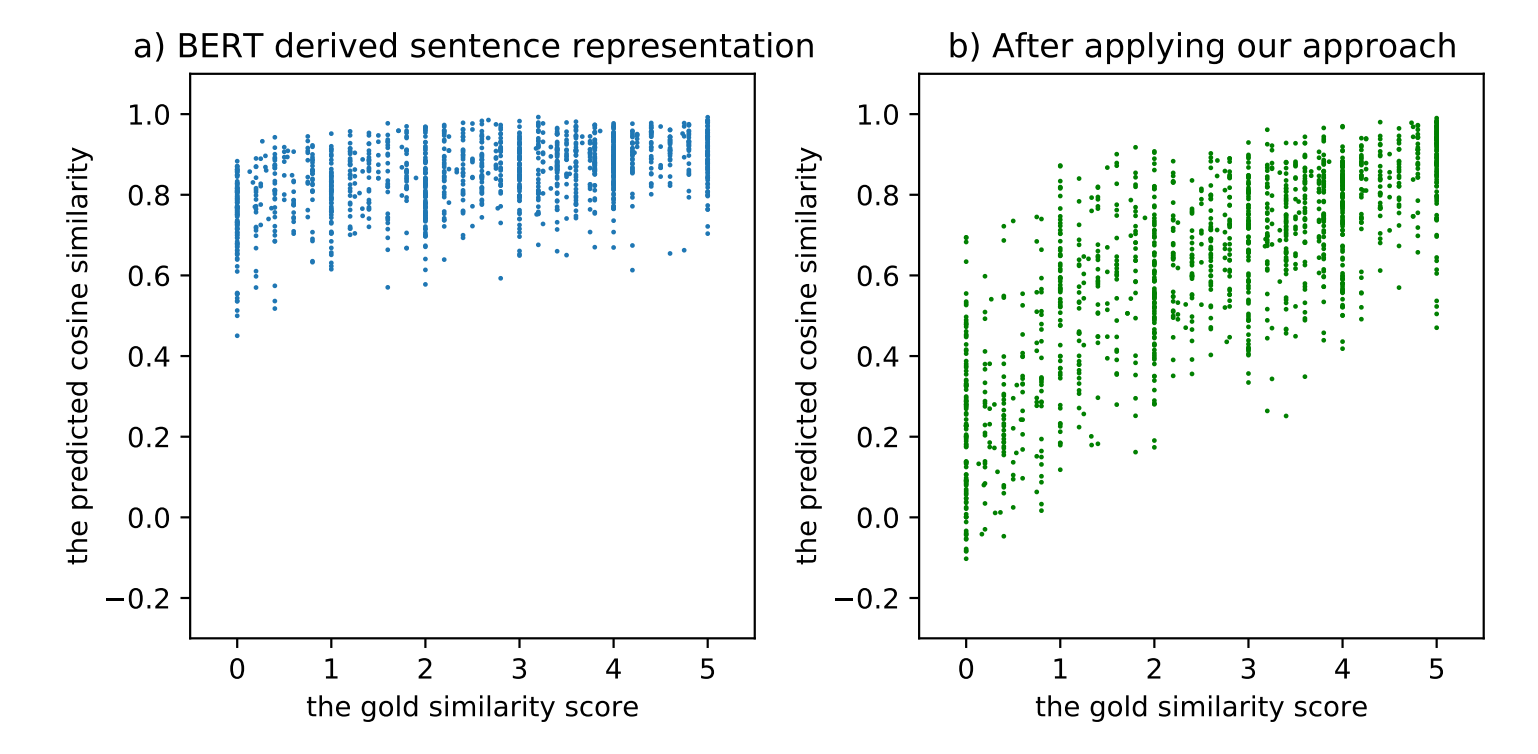
左:BERT表示空间的坍缩问题(横坐标是人工标注的相似度分数,纵坐标是模型预测的余弦相似度);右:经过CoSENT方法Fine-tune之后
- BERT句向量表示的坍缩和句子中的高频词有关。具体来说,当通过平均词向量的方式计算句向量时,那些高频词的词向量将会主导句向量,使之难以体现其原本的语义。当计算句向量时去除若干高频词时,坍缩现象可以在一定程度上得到缓解(如下图蓝色曲线所示)。
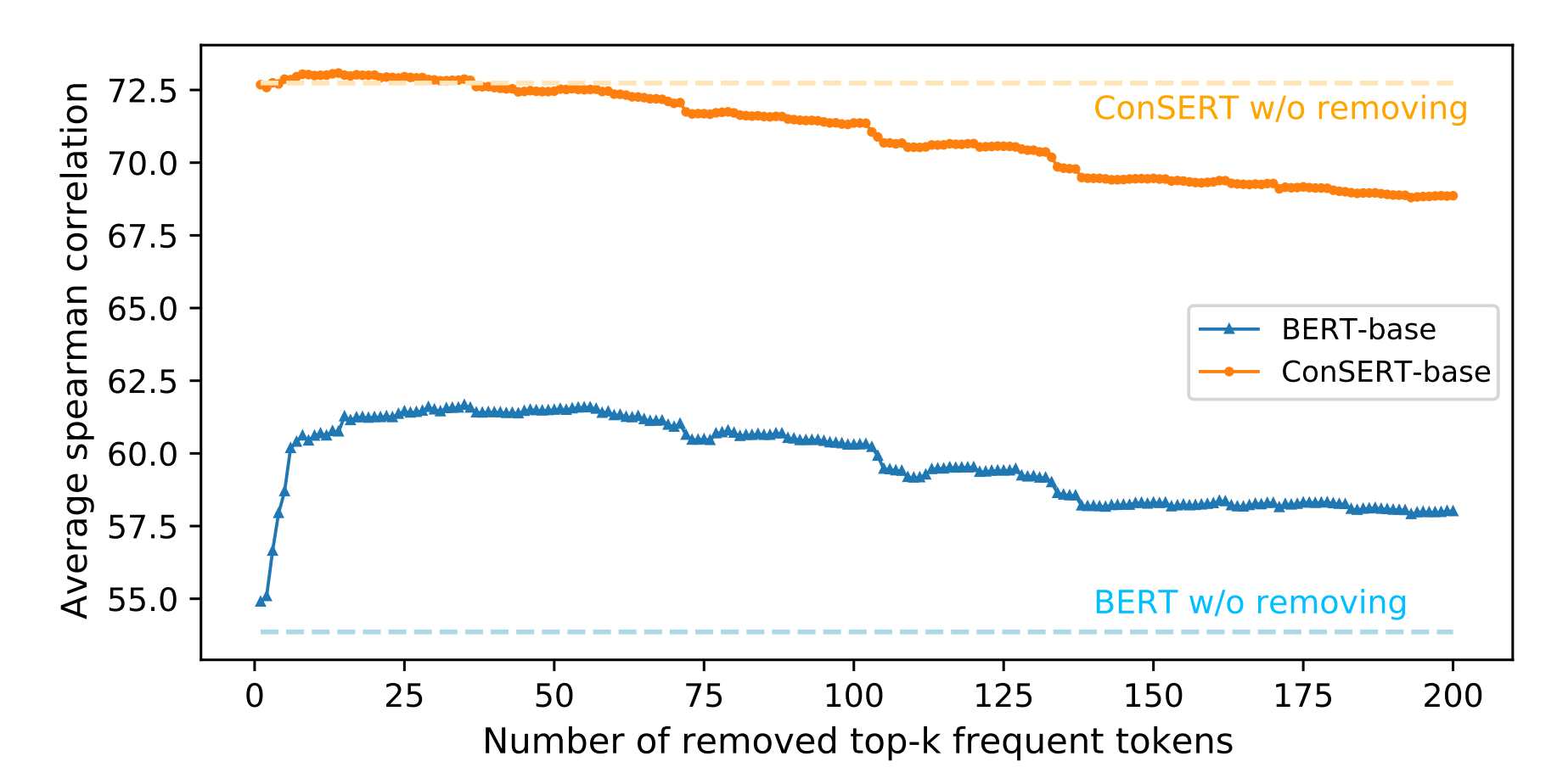
计算句向量时移除Top-K高频词后的性能变化
学习句向量的方案大致上可以分为无监督和有监督两大类,其中有监督句向量比较主流的方案是Facebook提出的InferSent,
而后的Sentence-BERT进一步在BERT上肯定了它的有效性。然而,不管是InferSent还是Sentence-BERT,它们都存在训练和预测不一致的问题,而如果直接优化预测目标cos值,效果往往特别差。
为了解决句向量方案这种训练与预测不一致的问题,分析了直接优化cos值无效的原因,并参考SimCSE的监督方法,分析了CoSENT的rank loss,该loss可以直接优化两个文本比较的cos值。实验显示,CoSENT在第一轮的收敛效果比Sentence-BERT高35%,最终效果上比Sentence-BERT高5%。
2. 研究现状和相关工作
2.1 句子表征学习
句子表征学习是一个很经典的任务,分为以下三类方法:
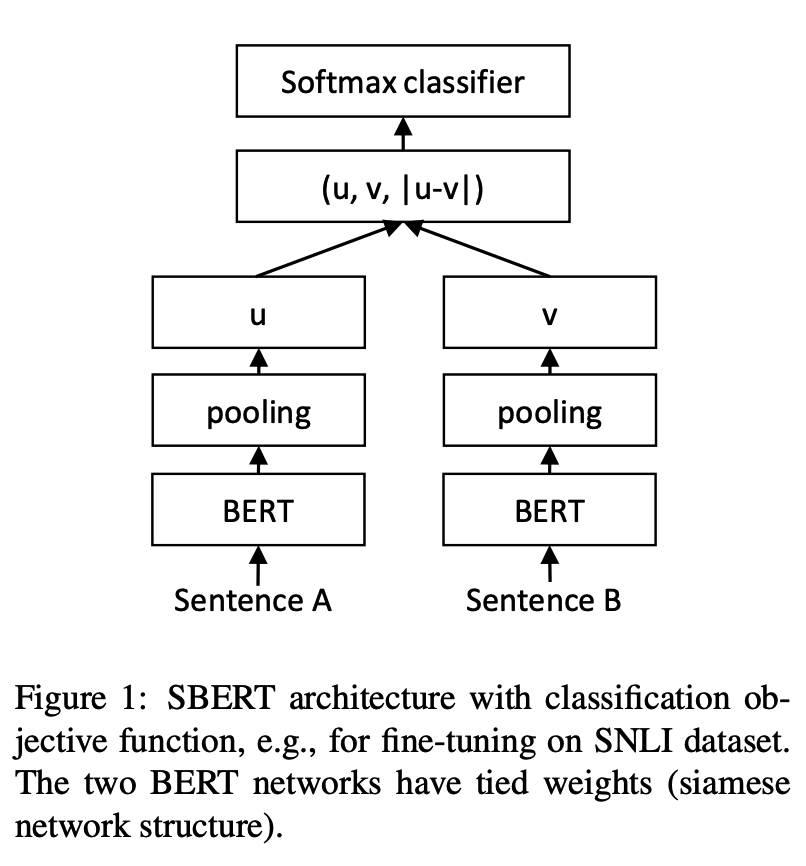
- 有监督的句子表征学习方法:早期的工作[5]发现自然语言推理(Natural Language Inference,NLI)任务对语义匹配任务有较大的帮助,训练过程常常融合了两个NLI的数据集SNLI和MNLI,文本表征使用BiLSTM编码器。InferSent模型用了siamese结构,两个句子共用一个encoder,分别得到u和v的文本向量表达,然后用3种计算方式,向量拼接([u,v]),相乘(u * v),相减(|u-v|)(为了保证对称性取绝对值),来帮助后面的全连接层提取向量间的交互信息,最后跟一个3分类的分类器。Sentence-BERT[1]借鉴了InferSent的框架,只是encoder部分替换成了BERT模型。
- 自监督的Sentence-level预训练:有监督数据标注成本高,研究者们开始寻找无监督的训练方式。BERT提出了NSP的任务,可以算作是一种自监督的句子级预训练目标。尽管之后的工作指出NSP相比于MLM其实没有太大帮助。Cross-Thought[7]、CMLM[8]是两种思想类似的预训练目标,他们把一段文章切成多个短句,然后通过相邻句子的编码去恢复当前句子中被Mask的Token。相比于MLM,额外添加了上下文其他句子的编码对Token恢复的帮助,因此更适合句子级别的训练。SLM[9]通过将原本连贯的若干个短句打乱顺序(通过改变Position Id实现),然后通过预测正确的句子顺序进行自监督预训练。
- 无监督的句子表示迁移:预训练模型现已被普遍使用,然而BERT的NSP任务得到的表示表现更不好,大多数同学也没有资源去进行自监督预训练,因此将预训练模型的表示迁移到任务才是更有效的方式。BERT-flow[2]:CMU&字节AI Lab的工作,通过在BERT之上学习一个可逆的Flow变换,可以将BERT表示空间映射到规范化的标准高斯空间,然后在高斯空间进行相似度匹配。BERT-whitening[10]:苏剑林提出对BERT表征进行白化操作(均值变为0,协方差变为单位矩阵)就能在STS上达到媲美BERT-flow的效果。SimCSE[11]:陈丹琦组在2021年4月份公开的工作,他们同样使用基于对比学习的训练框架,使用Dropout的数据增强方法,在维基百科语料上Fine-tune BERT。
2.2 Sentence-BERT模型
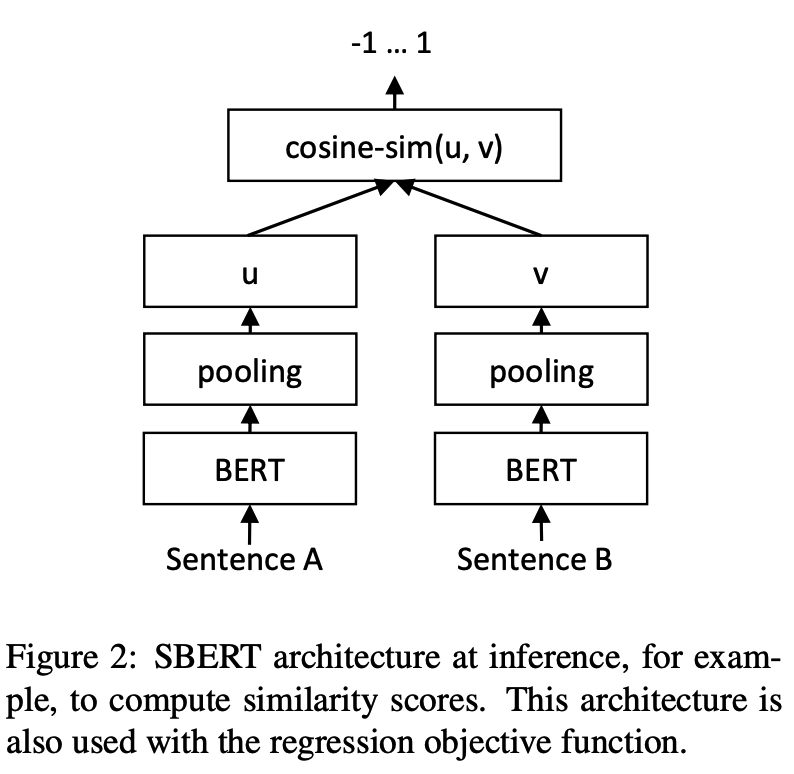
当前有监督的句子表征模型Sentence-BERT,表现出在句向量表示和文本匹配任务上SOTA的效果,证明了其有效性。Sentence-BERT的训练过程是把(u, v, |u - v|)拼接起来后接分类层,而预测过程,是跟普通的句向量模型一样,先计算mean pooling后的句向量,然后拿向量算cos得到相似度值。
Sentence-BERT的训练:
Sentence-BERT的预测:
Sentence-BERT模型为啥有效?
我们根据消融实验分析:
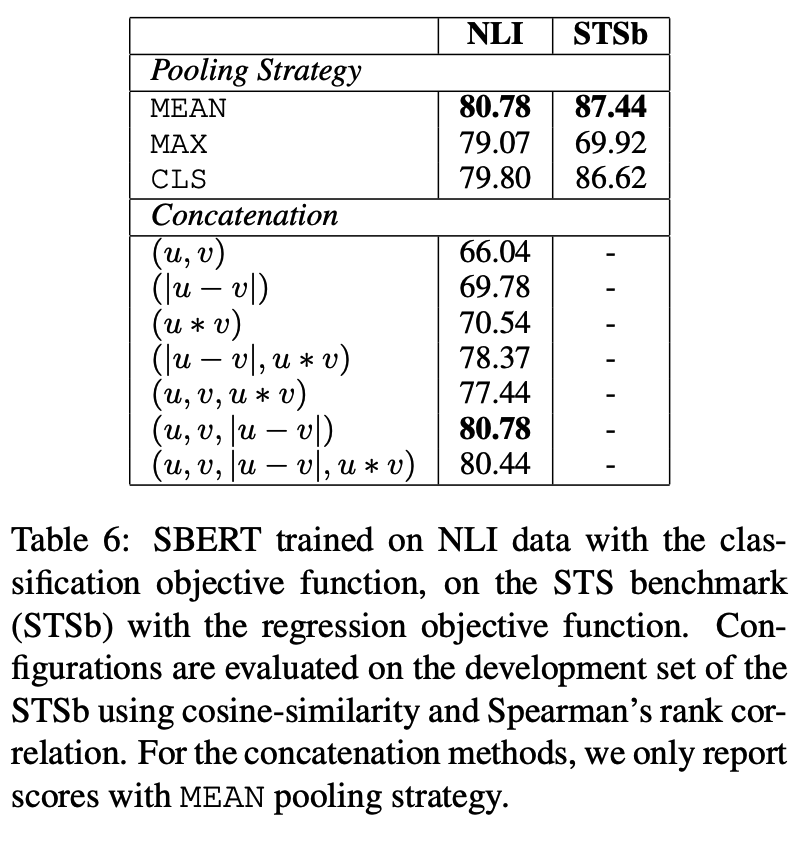
- |u - v|的作用,匹配数据集中,正样本对的文本相似度是远大于负样本对的,对于初始的BERT模型,其正样本对|u - v|差值也是小于负样本对|u - v|差值,可以看出正样本对的u - v分布是一个半径较小的球面附近,
而负样本对的u - v分布在一个较大的球面附近,也就是说,初始模型的u - v本身就有聚类倾向,我们只需要强化这种聚类倾向,使正样本对的u - v更小,负样本对的u - v更大。
BERT-flow和BERT-whitening这类BERT后处理模型,就是用无监督方法强化这种聚类倾向的方法。而监督方法的直接做法是u - v后面接一个全连接层的分类器,但交叉熵的分类器是基于内积计算的,它没法区分两个分布在不同球面的类别,所以这里加上绝对值变成|u - v|,将球面变成锥形,此时就可以用分类器来做分类了。 - u, v拼接的作用,从BERT-flow的工作可以知道,BERT句向量具备具备丰富的语义信息,但是句向量所在空间受到词频的影响,具备非平滑,各向异性的特点,这种特点导致未经过微调的“BERT+CLS”句向量模型直接应用在语义相似计算任务上的效果甚至不如简单的GloVe句向量,
而|u - v|只是向量的相对差距,无法明显改善这种各向异性。而在u, v拼接之后接全连接层,利用了全连接层的类别向量是随机初始化的,相当于给了u,v一个随机的优化方向,迫使他们各自“散开”,远离当前的各向异性状态。
3. CoSENT模型介绍
3.1 基本思路
目标:在一个类似BERT的预训练语言模型基础上,监督训练一个句向量表征模型,使模型能够在文本语义匹配任务上表现最好。
其中,可以利用的标注数据是常见的句子对形式,格式是“(句子1,句子2,标签)”,按照训练encoder的思路,两个句子经过encoder后分别得到向量u,v,由于预测阶段是计算的余弦相似度cos(u,v),所以思路是设计基于cos(u, v)的损失函数,让正样本对的相似度尽可能大、负样本对的相似度尽可能小。
如SimCSE的监督方法的损失函数:
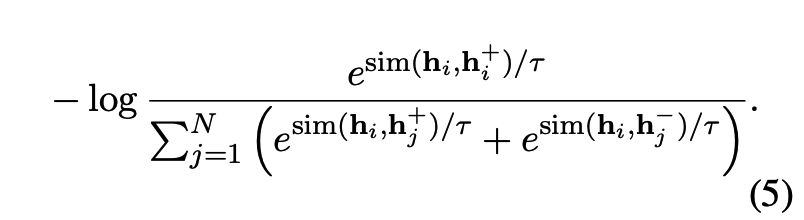
- 输入样本是 ( x i , x i + , x i − ) (x^{i}, x^{i+}, x^{i-}) (xi,xi+,xi−),其中 x i + x^{i+} xi+ 是与 x i x^{i} xi 蕴含关系,而 x i − x^{i-} xi− 是与 x i x^{i} xi 矛盾关系
- h i h^{i} hi 是 x i x^{i} xi 的句子embedding
- N N N 是 batch size
- s i m sim sim 是求余弦相似性(cosine similarity)
- t t t 是温度系数,作为超参数,取值为 0.05
3.2 基于cos的排序损失函数
我们记正样本对 ( x i , x i + ) (x^{i}, x^{i+}) (xi,xi+) ,负样本对 ( x i , x i − ) (x^{i}, x^{i-}) (xi,xi−),目标是希望对于任意的正样本对和负样本对都有如下关系:
cos ( h i , h i + ) > cos ( h i , h i − ) \cos(h^i, h^{i+}) > \cos(h^i, h^{i-}) cos(hi,hi+)>cos(hi,hi−)
至于正样本对的相似度比负样本对大多少,就是越多越好。所以可以设该cos结果的差值为损失,则优化该损失。借鉴Circle Loss和SimCSE的监督损失函数,
设计下面基于cos的排序损失函数:
log ( 1 + ∑ cos ( h i , h i + ) > cos ( h i , h i − ) e ( cos ( h i , h i − ) − cos ( h i , h i + ) ) / t ) \log\left( 1 + \sum_{\cos(h^i, h^{i+}) > \cos(h^i, h^{i-})} e^{(\cos(h^i, h^{i-}) - \cos(h^i, h^{i+}))/t}\right) log 1+cos(hi,hi+)>cos(hi,hi−)∑e(cos(hi,hi−)−cos(hi,hi+))/t
CoSENT的损失函数
- 正样本对是 ( x i , x i + ) (x^{i}, x^{i+}) (xi,xi+) ,负样本对是 ( x i , x i − ) (x^{i}, x^{i-}) (xi,xi−)。
- h i h^i hi 是 x i x^{i} xi 句子向量。
- t t t 表示 temperature,是温度系数,超参数。
模型结构:
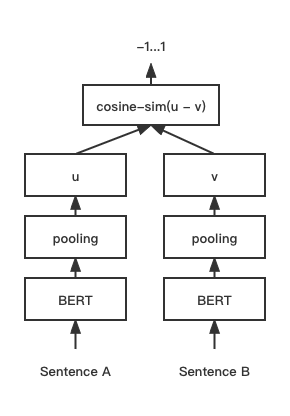
训练与预测同模型结构
3.3 融合监督和无监督信号
除了有监督训练以外,我们还可以进一步融合监督信号的策略:
先做有监督再无监督(sup-unsup):先使用有监督损失训练模型,再使用SimCSE的无监督的方法进行表示迁移也是可以的,具体效果下面有分析,大家可以自行实验,可以在领域迁移学习快速应用。
4. 实验分析
我们主要在文本语义匹配(Semantic Textual Similarity,STS)任务上进行了实验,主要是STS-B数据集,为STS benchmark,来自于SemEval2017评测赛,
该数据集中的样本均包含两个短文本text1和text2,以及人工标注的位于0~5之间的分数,代表text1和text2语义上的匹配程度(5表示最匹配,即“两句话表达的是同一个语义”;
0表示最不匹配,即“两句话表达的语义完全不相关”)。
下面给出了两条样本作为示例:
| text1 | text2 | score |
|---|---|---|
| A black and white photo of an old train station. | A black and white photo of a motorcycle laying on the ground. | 0.2 |
| a woman is dancing in the rain . | a woman dances in the rain out side . | 5.0 |
中文STS-B数据集,是英文STS-B数据集的中文翻译版本,示例case如下:
| text1 | text2 | score |
|---|---|---|
| 一个男人在玩电子键盘。 | 一个人在吹长笛。 | 1 |
| 女人剥土豆。 | 一个女人在剥土豆。 | 5 |
在测试时,为了跟之前的文本匹配工作保持一致,选择了斯皮尔曼相关系数(Spearman correlation)作为评测指标,
它将用于衡量两组值(模型预测的余弦相似度和人工标注的语义相似度)之间的相关性,结果将位于[-1, 1]之间,仅当两组值完全正相关时取到1。
对于每个数据集,我们将其测试样本全部融合计算该指标。考虑到简洁性,会在表格中报告乘以100倍的结果。
4.1 英文匹配数据集
| Arch | Backbone | Model Name | English-STS-B |
|---|---|---|---|
| GloVe | glove | Avg_word_embeddings_glove_6B_300d | 61.77 |
| BERT | bert-base-uncased | BERT-base-cls | 20.29 |
| BERT | bert-base-uncased | BERT-base-first_last_avg | 59.04 |
| BERT | bert-base-uncased | BERT-base-first_last_avg-whiten(NLI) | 63.65 |
| SBERT | sentence-transformers/bert-base-nli-mean-tokens | SBERT-base-nli-cls | 73.65 |
| SBERT | sentence-transformers/bert-base-nli-mean-tokens | SBERT-base-nli-first_last_avg | 77.96 |
| CoSENT | bert-base-uncased | CoSENT-base-first_last_avg | 69.93 |
| CoSENT | sentence-transformers/bert-base-nli-mean-tokens | CoSENT-base-nli-first_last_avg | 79.68 |
英文数据集的实验结果
在英文匹配任务实验中,我们基于预训练的BERT在STS数据上进行Fine-tune。
在有监督实验中,我们没有使用额外的SNLI和MNLI训练数据,仅使用了STSb的训练数据,CoSENT在backbone为bert-base-uncased和bert-base-nli-mean-tokens下,实现结果得分均超过了基线。
结果显示,CoSENT方法在完全一致的设置下超过Sentence-BERT,达到了2%的相对性能提升。
4.2 中文匹配数据集
| Arch | Backbone | Model Name | ATEC | BQ | LCQMC | PAWSX | STS-B | Avg |
|---|---|---|---|---|---|---|---|---|
| SBERT | bert-base-chinese | SBERT-bert-base | 46.36 | 70.36 | 78.72 | 46.86 | 66.41 | 61.74 |
| SBERT | hfl/chinese-macbert-base | SBERT-macbert-base | 47.28 | 68.63 | 79.42 | 55.59 | 64.82 | 63.15 |
| SBERT | hfl/chinese-roberta-wwm-ext | SBERT-roberta-ext | 48.29 | 69.99 | 79.22 | 44.10 | 72.42 | 62.80 |
| CoSENT | bert-base-chinese | CoSENT-bert-base | 49.74 | 72.38 | 78.69 | 60.00 | 79.27 | 68.01 |
| CoSENT | hfl/chinese-macbert-base | CoSENT-macbert-base | 50.39 | 72.93 | 79.17 | 60.86 | 79.30 | 68.53 |
| CoSENT | hfl/chinese-roberta-wwm-ext | CoSENT-roberta-ext | 50.81 | 71.45 | 79.31 | 61.56 | 79.96 | 68.61 |
中文数据集的实验结果
在中文匹配任务实验中,我们在五个数据集中做了实验,包括:ATEC、BQ、LCQMC、PAWSX、STS-B,并且报告了五个数据集的平均结果,结果显示,
CoSENT方法在在相同的MacBERT预训练模型下Fine-tune,其得分超过Sentence-BERT,达到了5%的相对性能提升。
4.3 BackBone选择的实验分析
我们对比了CoSENT在不同的BackBone下的中文STS-B的实验结果,包括bert-base-chinese、hfl/chinese-macbert-base、nghuyong/ernie-3.0-base-zh等多种中文预训练模型。
| backbone | Chinese-STS-B (spearman, test) |
|---|---|
| bert-base-chinese | 0.7927 |
| hfl/chinese-bert-wwm-ext | 0.7635 |
| hfl/chinese-roberta-wwm-ext | 0.7996 |
| hfl/chinese-macbert-base | 0.7930 |
| hfl/chinese-macbert-large | 0.7495 |
| nghuyong/ernie-3.0-nano-zh | 0.6677 |
| nghuyong/ernie-3.0-base-zh | 0.8153 |
| nghuyong/ernie-3.0-xbase-zh | 0.7827 |
在中文STS-B的实验中,我们发现CoSENT在不同的BackBone下的实验结果相差不大,这说明CoSENT方法对于不同的BackBone都有很好的适应性,
该实验显示同等参数量模型size下,Backbone最佳是nghuyong/ernie-3.0-base-zh。
4.4 Pooling策略的实验分析
我们对比了CoSENT使用不同pooling策略的实验结果,包括MEAN、CLS、FIRST_LAST_AVG等多种pooling策略,其他实验设置是一样的:
Backbone为nghuyong/ernie-3.0-base-zh,训练集为Chinese-STS-B,batch size为64,t为0.05。
| pooling | Chinese-STS-B (spearman, test) |
|---|---|
| CLS | 0.8020 |
| POOLER | 0.7379 |
| FIRST_LAST_AVG | 0.7931 |
| MEAN | 0.8153 |
在中文STS-B的实验中,我们发现MEAN pooling 效果最好,但和CLS、FIRST_LAST_AVG相差不大,我们还发现个有趣的现象,用FIRST_LAST_AVG训练,再用MEAN预测,效果损失很小,或者换过来也一样,
pooling策略对中文匹配影响较小。pooling策略最佳选择MEAN。
4.5 Temperature超参的实验分析
在实验中,我们发现对比学习损失函数中的温度超参数(t)对于结果有很大影响。从下面CoSENT模型的分析实验中可以看到,当t值在0.01到0.05之间时会得到最优结果。
这个现象再次证明了BERT表示的坍缩问题,因为在句子表示都很接近的情况下,t过大会使句子间相似度更平滑,编码器很难学到知识。而t如果过小,任务就太过简单,所以需要调整到一个合适的范围内。
不同超参数t下的性能
| temperature | Chinese-STS-B (spearman, test) | first-epoch-spearman(dev) | best_epoch_num |
|---|---|---|---|
| 0.2 | 0.7711 | 0.8158 | 2 |
| 0.1 | 0.7945 | 0.8291 | 5 |
| 0.05 | 0.8051 | 0.8277 | 2 |
| 0.03 | 0.8061 | 0.8255 | 3 |
| 0.025 | 0.8065 | 0.8181 | 2 |
| 0.0125 | 0.8105 | 0.7982 | 9 |
| 0.01 | 0.8127 | 0.7838 | 9 |
| 0.005 | 0.7846 | 0.6399 | 4 |
在中文STS-B的实验中,温度超参数(t)最佳的是0.01,需要9个epoch训练,而设置t为0.05时,仅需要2个epoch即可达到最佳性能,
而且模型收敛速度更快,第一个epoch的dev结果就有0.8277,相较t=0.01的0.7838有0.04的提升。另外,Sentence-BERT第一个epoch的dev结果只有0.4630。
4.6 Batch size超参的实验分析
NLP的transformer框架下的模型,Batch size会对结果有影响,因此我们也对比了不同Batch size下在Chinese-STS-B数据集CoSENT模型的表现。
不同Batch size下的性能
| batch size | Chinese-STS-B (spearman, test) | first-epoch-spearman(dev) | best_epoch_num |
|---|---|---|---|
| 16 | 0.7891 | 0.8295 | 5 |
| 32 | 0.7957 | 0.8339 | 4 |
| 64 | 0.8051 | 0.8306 | 2 |
| 128 | 0.8011 | 0.8251 | 2 |
| 192 | 0.8018 | 0.8191 | 7 |
实验结果,可以看到batch size和spearman得分两者基本是成正比的,但提升很有限。该实验显示最佳batch size是64。
4.7 融合无监督信号的实验分析
无监督句子表征的模型有较大突破,为了提升模型的表征效果,我们希望能在有监督模型之后融合无监督信号,下面对比实验了Whitening、SimCSE等无监督方法。
| arch | backbone | model | Chinese-STS-B (spearman) |
|---|---|---|---|
| SBERT | bert-base-chinese | SBERT-bert-chinese-finetune-ChineseSTS | 0.7723 |
| RoFormer-Sim | RoFormer-base-chinese | chinese_roformer-sim-char-ft_L-12_H-768_A-12 | 0.7827 |
| SimBERT | bert-base-chinese | chinese_simbert_L-12_H-768_A-12 | 0.7098 |
| SimBERT | chinese_simbert_L-12_H-768_A-12 | SimBERT-base-chinese-SimCSE-cls-unsup | 0.7562 |
| SimBERT | chinese_simbert_L-12_H-768_A-12 | SimBERT-base-chinese-SimCSE-first-last-avg-unsup | 0.7264 |
| BERT | bert-base-chinese | BERT-base-chinese-SimCSE-cls-unsup | 0.6699 |
| BERT | bert-base-chinese | BERT-base-chinese-SimCSE-cls-sup | 0.7613 |
| BERT | bert-base-chinese | BERT-base-chinese-mean_pooling | 0.5473 |
| BERT | bert-base-chinese | BERT-base-chinese-first_last_avg | 0.5446 |
| BERT | bert-base-chinese | BERT-base-chinese-first_last_avg-whiten(768) | 0.6808 |
| BERT | bert-base-chinese | BERT-base-chinese-sup-finetune-ChineseSTS | 0.7755 |
| CoSENT | bert-base-chinese | CoSENT-bert-base-chinese-first_last_avg | 0.7942 |
| CoSENT | hfl/chinese-macbert-base | CoSENT-macbert-base-chinese-first_last_avg | 0.8051 |
| CoSENT | hfl/chinese-macbert-base | CoSENT-macbert-base-chinese-first_last_avg-whiten(768) | 0.7642 |
| CoSENT | hfl/chinese-macbert-base | CoSENT-macbert-base-chinese-first_last_avg-whiten(384) | 0.7708 |
| CoSENT | hfl/chinese-macbert-base | CoSENT-macbert-base-chinese-first_last_avg-simcse | 0.8133 |
从实验结果中可以看,后接whitening操作使模型效果降低了0.035,而接SimCSE模型效果提升0.008。
表明在监督模型后直接硬接无监督训练,提升不大,基于SimCSE无监督训练会有小幅提升。
5. Release Model
我们基于以上实验结果,按最优参数训练了文本表征的CoSENT模型,在中文匹配评测集上取得了SOTA效果,并具备s2s(sentence to sentence)和s2p(sentence to paraphrase)的文本相似度计算、相似文本检索能力。
训练参数
- arch: CoSENT
- backbone: nghuyong/ernie-3.0-base-zh
- pooling: MEAN
- temperature: 0.05
- batch_size: 64
- max_seq_length: 256
评测结果:
| Arch | BackBone | Model | ATEC | BQ | LCQMC | PAWSX | STS-B | SOHU-dd | SOHU-dc | Avg | QPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word2Vec | word2vec | w2v-light-tencent-chinese | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| SBERT | xlm-roberta-base | sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| Instructor | hfl/chinese-roberta-wwm-ext | moka-ai/m3e-base | 41.27 | 63.81 | 74.87 | 12.20 | 76.96 | 75.83 | 60.55 | 57.93 | 2980 |
| CoSENT | hfl/chinese-macbert-base | shibing624/text2vec-base-chinese | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| CoSENT | hfl/chinese-lert-large | GanymedeNil/text2vec-large-chinese | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| CoSENT | nghuyong/ernie-3.0-base-zh | shibing624/text2vec-base-chinese-sentence | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| CoSENT | nghuyong/ernie-3.0-base-zh | shibing624/text2vec-base-chinese-paraphrase | 44.89 | 63.58 | 74.24 | 40.90 | 78.93 | 76.70 | 63.30 | 63.08 | 3066 |
shibing624/text2vec-base-chinese模型,是用CoSENT方法训练,基于hfl/chinese-macbert-base在中文STS-B数据训练得到,并在中文STS-B测试集评估达到较好效果,模型文件已经上传HF model hub,中文通用语义匹配任务推荐使用shibing624/text2vec-base-chinese-sentence模型,是用CoSENT方法训练,基于nghuyong/ernie-3.0-base-zh用人工挑选后的中文STS数据集训练得到,并在中文各NLI测试集评估达到较好效果,模型文件已经上传HF model hub,中文s2s语义匹配任务推荐使用shibing624/text2vec-base-chinese-paraphrase模型,是用CoSENT方法训练,基于nghuyong/ernie-3.0-base-zh用人工挑选后的中文STS数据集,并加入了s2p数据,强化了其长文本的表征能力,并在中文各NLI测试集评估达到SOTA,模型文件已经上传HF model hub,中文s2p语义匹配任务推荐使用- 为测评模型的鲁棒性,加入了未训练过的SOHU测试集,用于测试模型的泛化能力
6. 总结
在此工作中,我们分析了BERT句向量表示空间坍缩的原因,并分析了基于排序loss的句子表示CoSENT模型的优势。CoSENT在有监督训练的实验中表现出了优秀的性能,在中英文数据集上都超越了基线模型,表现出模型对句子表征的有效性。
目前,相关代码已经放Github上:shibing624/text2vec,欢迎大家使用。
参考文献
- [1] Reimers, Nils, and Iryna Gurevych. “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks.” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.
- [2] Li, Bohan, et al. “On the Sentence Embeddings from Pre-trained Language Models.” Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
- [3] Gao, Jun, et al. “Representation Degeneration Problem in Training Natural Language Generation Models.” International Conference on Learning Representations. 2018.
- [4] Wang, Lingxiao, et al. “Improving Neural Language Generation with Spectrum Control.” International Conference on Learning Representations. 2019.
- [5] Conneau, Alexis, et al. “Supervised Learning of Universal Sentence Representations from Natural Language Inference Data.” Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017.
- [6] Cer, Daniel, et al. “Universal Sentence Encoder for English.” Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2018.
- [7] Wang, Shuohang, et al. “Cross-Thought for Sentence Encoder Pre-training.” Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
- [8] Yang, Ziyi, et al. “Universal Sentence Representation Learning with Conditional Masked Language Model.” arXiv preprint arXiv:2012.14388 (2020).
- [9] Lee, Haejun, et al. “SLM: Learning a Discourse Language Representation with Sentence Unshuffling.” Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
- [10] Su, Jianlin, et al. “Whitening sentence representations for better semantics and faster retrieval.” arXiv preprint arXiv:2103.15316 (2021).
- [11] Gao, Tianyu, Xingcheng Yao, and Danqi Chen. “SimCSE: Simple Contrastive Learning of Sentence Embeddings.” arXiv preprint arXiv:2104.08821 (2021).
- [12] Wu, Xing, et al. “Conditional bert contextual augmentation.” International Conference on Computational Science. Springer, Cham, 2019.
- [13] Zhou, Wangchunshu, et al. “BERT-based lexical substitution.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019.
- [14] He, Kaiming, et al. “Momentum contrast for unsupervised visual representation learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
- [15] Chen, Ting, et al. “A simple framework for contrastive learning of visual representations.” International conference on machine learning. PMLR, 2020.
- [16] Zhang, Yan, et al. “An Unsupervised Sentence Embedding Method by Mutual Information Maximization.” Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
- [17] Fang, Hongchao, et al. “Cert: Contrastive self-supervised learning for language understanding.” arXiv preprint arXiv:2005.12766 (2020).
- [18] Carlsson, Fredrik, et al. “Semantic re-tuning with contrastive tension.” International Conference on Learning Representations. 2021.
- [19] Giorgi, John M., et al. “Declutr: Deep contrastive learning for unsupervised textual representations.” arXiv preprint arXiv:2006.03659 (2020).
- [20] Wu, Zhuofeng, et al. “CLEAR: Contrastive Learning for Sentence Representation.” arXiv preprint arXiv:2012.15466(2020).
- [21] 苏剑林. (Su. 06, 2022). 《CoSENT(一):比Sentence-BERT更有效的句向量方案 》[Blog post]. Retrieved from https://kexue.fm/archives/8847

















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









