







返回目录:总目录——深度学习代码实战
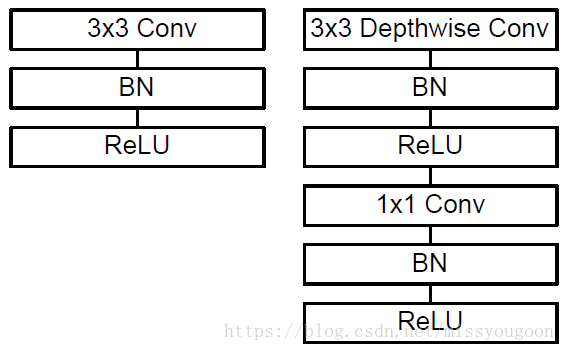
思路:深度可分离卷积,拆分到极致.
做法:将每个通道拆分,分别进行卷积,然后在进行合并.
优点:计算量比较小,但是精度会有所下降.
Mobilenet结构图:
import tensorflow as tf
import os
import numpy as np
import pickle
# 文件存放目录
CIFAR_DIR = "./cifar-10-batches-py"
def load_data( filename ):
'''read data from data file'''
with open( filename, 'rb' ) as f:
data = pickle.load( f, encoding='bytes' ) # python3 需要添加上encoding='bytes'
return data[b'data'], data[b'labels'] # 并且 在 key 前需要加上 b
class CifarData:
def __init__( self, filenames, need_shuffle ):
'''参数1:文件夹 参数2:是否需要随机打乱'''
all_data = []
all_labels = []
for filename in filenames:
# 将所有的数据,标签分别存放在两个list中
data, labels = load_data( filename )
all_data.append( data )
all_labels.append( labels )
# 将列表 组成 一个numpy类型的矩阵!!!!
self._data = np.vstack(all_data)
# 对数据进行归一化, 尺度固定在 [-1, 1] 之间
self._data = self._data / 127.5 - 1
# 将列表,变成一个 numpy 数组
self._labels = np.hstack( all_labels )
# 记录当前的样本 数量
self._num_examples = self._data.shape[0]
# 保存是否需要随机打乱
self._need_shuffle = need_shuffle
# 样本的起始点
self._indicator = 0
# 判断是否需要打乱
if self._need_shuffle:
self._shffle_data()
def _shffle_data( self ):
# np.random.permutation() 从 0 到 参数,随机打乱
p = np.random.permutation( self._num_examples )
# 保存 已经打乱 顺序的数据
self._data = self._data[p]
self._labels = self._labels[p]
def next_batch( self, batch_size ):
'''return batch_size example as a batch'''
# 开始点 + 数量 = 结束点
end_indictor = self._indicator + batch_size
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3144
3144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









