







摘要
本文主要介绍张量(Tensor)相关技术以及张量在数据恢复(missing data)、推荐中的应用。在文章的最后,简单介绍怎么通过ADMM算法吧把张量应用在大规模数据上。文章的内容来自于葛瀚骋博士、现任美国亚马逊资深科学家。
我们现在所处的时代是一个信息爆炸的时代,许多现代的信息系统,比如物联网,电子健康记录,以及社交网络,每天都在不断产生着新的数据,这些数据是以指数级的方式去增长的。它的特点包括数量庞大、维度较多、而且这些数据的来源也是“多方面”的。那么我们怎么样去理解“多方面”这个词呢?
这里举一个非常简单的例子,我们可以看到下图这三人大家应该都比较熟悉。他们三人日常会通过不同的方式去联系,比如推特、facebook、微信以及电话。但是因为众所周知的原因,推特以及facebook在某些国家是没法使用的,微信在某些国家是特别受欢迎的。所以,这些因素会导致联系方式上的多样性。
这种多方面的社交关系,可以用多个矩阵来表达。在上述情况下,我们需要四个矩阵来刻画上面所提到的关系,每一个矩阵代表某种特定联系方式下的人物之间关系,比如用一个矩阵来表示基于推特的关系,用另一个矩阵来表示基于微信的关系等等。这种多方面的关系网络存在于我们生活中的点点滴滴。
一、什么是张量(Tensor)?
张量这个词英文叫Tensor。很多人有可能觉得比较陌生,但相信大部分人都听说过Tensorflow。其实Tensorflow里最基本的数据结构就是Tensor,跟本文讲的Tensor的概念是一样的,并不是物理学中的张量概念。

那具体什么是张量呢,张量是多维数组的泛概念。一维数组我们通常称之为向量,二维数组我们通常称之为矩阵,但其实这些都是张量的一种。以此类推,我们也会有三维张量、四维张量以及五维张量。那么零维张量是什么呢?其实零维张量就是一个数。
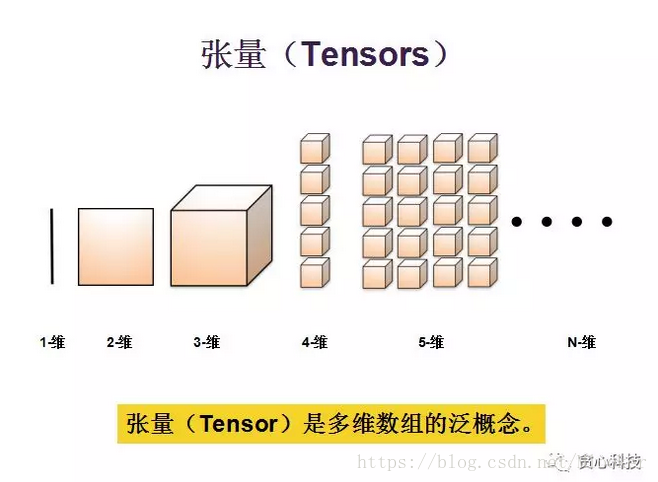
为了加深大家对张量概念的理解,再举一个简单例子。如用户对电影的评分可以用来一个二维矩阵来表示。但是如果我们把时间因素也考虑进去,就变成了一个三维数组,那么我们就称这一数组是一个三维张量。其实在某些方面,张量和多维度数据是对等的。张量非常适合去表示多维度的数据,张量通过多维度的数据,可将用户间的内在联系捕捉到。
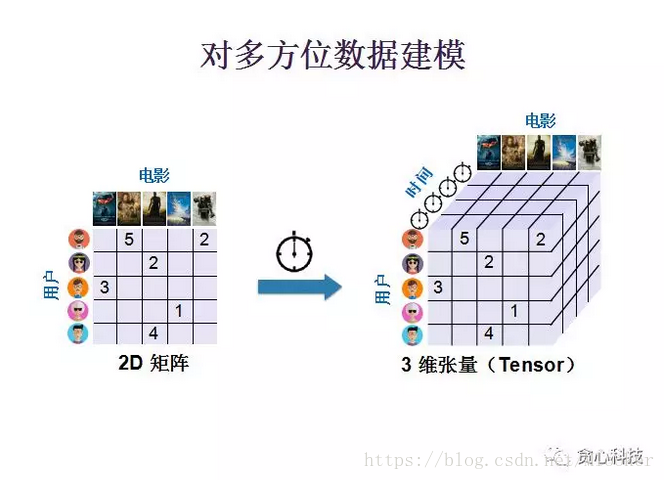
张量通常是动态增长的,它的增长通常可以用三种形式来实现。
第一种是维度的增长。比如我们只考虑用户时间、电影和评分来进行张量建模,那么这个张量只有三个维度。但如果我们再把电影主题也加进去,那么就从一个三维张量增长成了四维张量,这是通过维度上的增长,
第二种增长是维度中数据的增长,如现在我们有用户、时间和电影这三个维度,但是还会有新的用户,也会有新的电影,时间也是逐渐增长的,所以每个维度也会自然增长,但是维数始终是固定的,这就是第二种增长。
最后一种增长是观测数据的增长,比如说维度的个数是固定的,三个维度——用户、时间、电影。那么每个维度上的数量也是固定的,但是呢,我们可能一开始只获取了部分数据,然后后面会获取越来越多的数据。这样就形成了一种观测数据的增长,所以这也是一种张量的增长方式。
下面我们介绍张量的基本操作。首先如何计算两个张量的内积?其实就是把他们相对应维度的元素相乘,然后把相乘后元素相加,这就是两个张量的内积。张量的每一维度都可以被展成一个相应的矩阵。一个三维的、3×4×2的张量可以被展成对应的三个矩阵(如下图所示)。
接下来介绍另一个重要的操作--张量乘以矩阵。因为很多时候我们都需要用一个张量去乘一个矩阵。比如,我们有一个三维张量,它的大小是3×4×2,我们还有一个矩阵,它的大小是2×5。那么我们用这一张量去乘以这一矩阵,最后得到的也是一个张量,它的大小就是3×4×5。
对于张量,我们可以定义两种不同的积,一个叫Kronecker(克罗内克)积,另一个叫Khatri-Rao积。这两个积跟张量分解息息相关。需要注意的是Khatri-Rao积是基于Kronecker积的扩展。如果大家对于这两种积的运算不太熟悉,建议大家可以在网上查询相关资料,网络有大量关于这两种积的介绍。

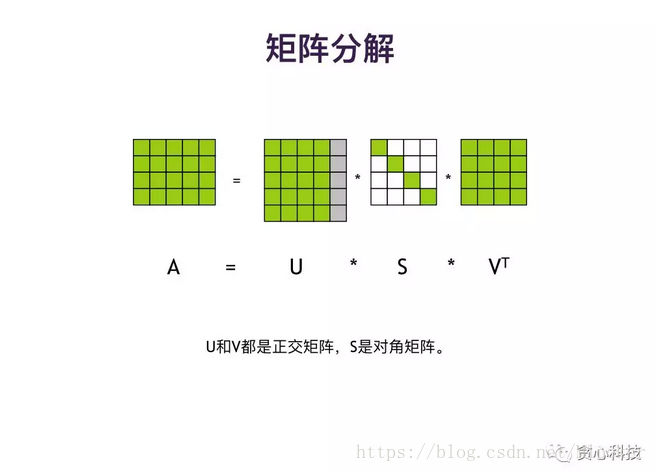
下面来谈一下张量的分解。谈张量分解之前,我们先回忆一下矩阵分解。下面的图表示如何做矩阵的SVD分解。SVD分解是矩阵分解的一种形式,一个矩阵A可分解成三个矩阵(如下图所示),U和V都是正交矩阵,S是一个对角矩阵。和矩阵分解相似,张量其实也是可以被分解的。
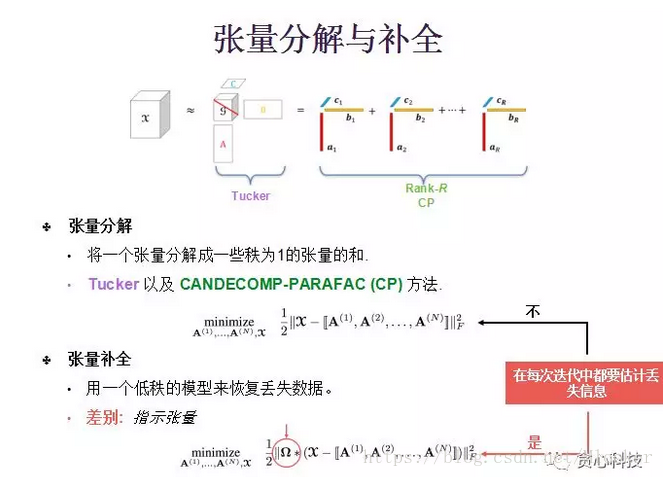
张量分解通常是从数据中提取一个低秩(low rank)的结构。具体来说,就是把张量分解成一堆rank为1的张量的和。我们可以看下面的图,这张图里揭示了两种张量分解的方式,一种叫tucker,一种叫cp。张量x,可以被分解成矩阵a、b、c 以及一个张量叫g。这种分解形式跟矩阵的分解非常像。该张量是三维的,其每一维都会分解成一个矩阵。对应的分别是abc,那么中间那个对角矩阵也会变成一个三维的对角张量。
另外一种方式为cp,cp是由秩为1的张量来组成的,这个秩为1的张量,是由三个向量相乘所得到的。R我们通常就称为是这个张量的秩。
除了张量分解之外,还有另外一个概念叫张量补全。张量补全的目标是用一个低秩的模型来恢复丢失的数据。通过下图的两个公式,我们可以看到,其实张量分解和张量补全只有一个微小的差别,就是张量补全会多出一个告诉张量哪个位置是我们观测到的数据,而剩下的就是我们没有观测到的数据。在具体的方法中,张量分解在每次迭代中,是不需要估计丢失信息的。而张量补全在每次迭代中是需要估计丢失信息的。
二、张量在时空数据恢复的应用
众所周知,手机已经成为了我们不可或缺的生活工具,每时每刻通过手机在互联网上产生了大量的动态信息,这些动态信息一般分为以下几个维度——时间、位置、内容,这些动态信息本身很有价值,比如谁产生了这些信息,在哪里产生了这些信息,什么时候产生了这些信息,以及这些信息是关于什么事件等。
但是因为各种限制,如访问权限的限制,我们往往不能获取到全部的信息,也就是说我们在获取信息的时候,同时也会发生信息的丢失,比如,我们只能获取到新浪微博中很少一部分的数据,那么我们在基于这些极为有限的信息,来作出社交网络结构特点的估计时,其结果往往是不准确的。
所以如何去恢复这些丢失的信息,对于某些应用来说,是一件非常重要的事情。

接下来我们拿主题标签(Hashtags)举一个例子。主题标签指的是(以微博为例)我们在发微博的时候,会带一个#,后面会跟一个跟你发的信息相关的一个主题,每一个主题标签在发出去的时候都会统计到当时所发信息的时间、地理位置,以及主题内容信息,这三个维度信息就可以被一个三维张量去表示。
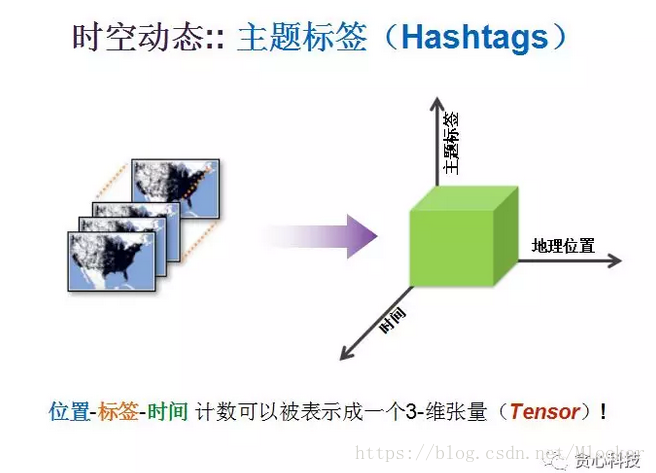
我们通常所获取的主题标签信息是不完整的,我们的目标是学习一个模型,使得我们没有观测到的数据,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









