







目前很多企业都开始做知识库或客服。通过开源项目里的issue去看,碰到的问题也是大同小异。例如:
[BUG] 关于答案胡乱生成的问题 · Issue #886 · imClumsyPanda/langchain-ChatGLM (github.com) 。
如何文本分割的时候,按照每行进行分割?因为我的本地TXT文件知识库是按照Q,A的形式组织的。也就是文本切片的时候按照每行进行切片。· Issue #893 · imClumsyPanda/langchain-ChatGLM (github.com)
知识库或者客服,其要求就是知识库要细分,应用要垂直。根据实际场景来优化。例如客服场景:要求特定的问题回答要准确,而且问题是和公司业务强相关,非常的细分,那最好的就是FAQ库。整个架构模型核心点就是围绕持续沉淀FAQ来做的,大模型是在FAQ和转人工之间加了一层,不管是大模型提炼答案、用户反馈、人工维护都是让FAQ更丰富。
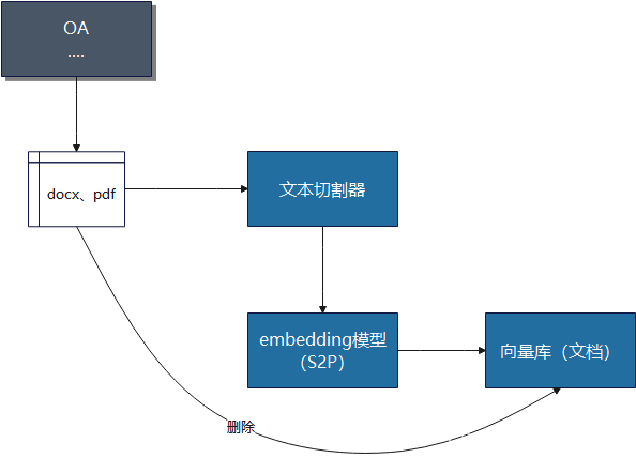
语料处理1:

语料处理2:
客服/知识库的逻辑架构模型:
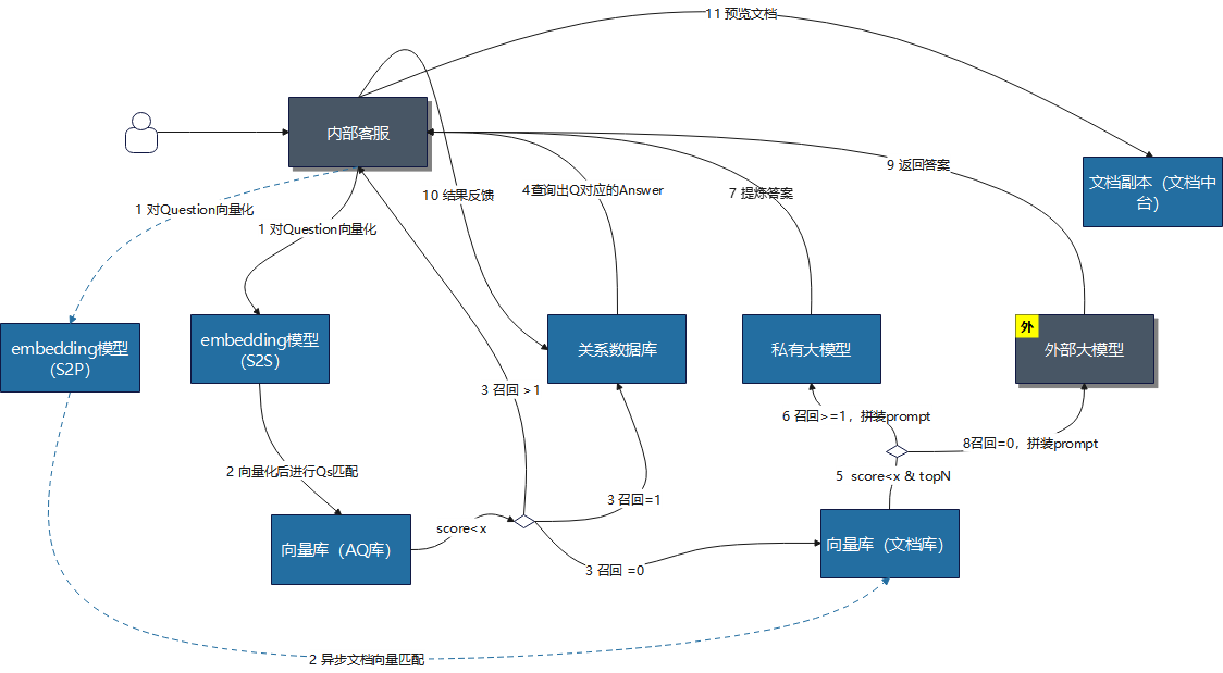
FAISS这种嵌入的向量库做前期预研可以。生产的话,数据库选择PG比较合适,不管是关系型还是向量的数据都可以存储。后续还可以有管理端可以对数据进行修改。
















 1801
1801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











