







这篇对整体框架还是系统分析下,说下里面的控制逻辑,以及列出相关的优化点有哪些。
一个LangChain+大模型的知识库关键环节,包括:文档导入、文本切割、文本块向量化、提问向量化、文本块匹配、prompt拼装、大模型加工返回结果。
[BUG] 关于答案胡乱生成的问题 · Issue #886 · imClumsyPanda/langchain-ChatGLM (github.com):
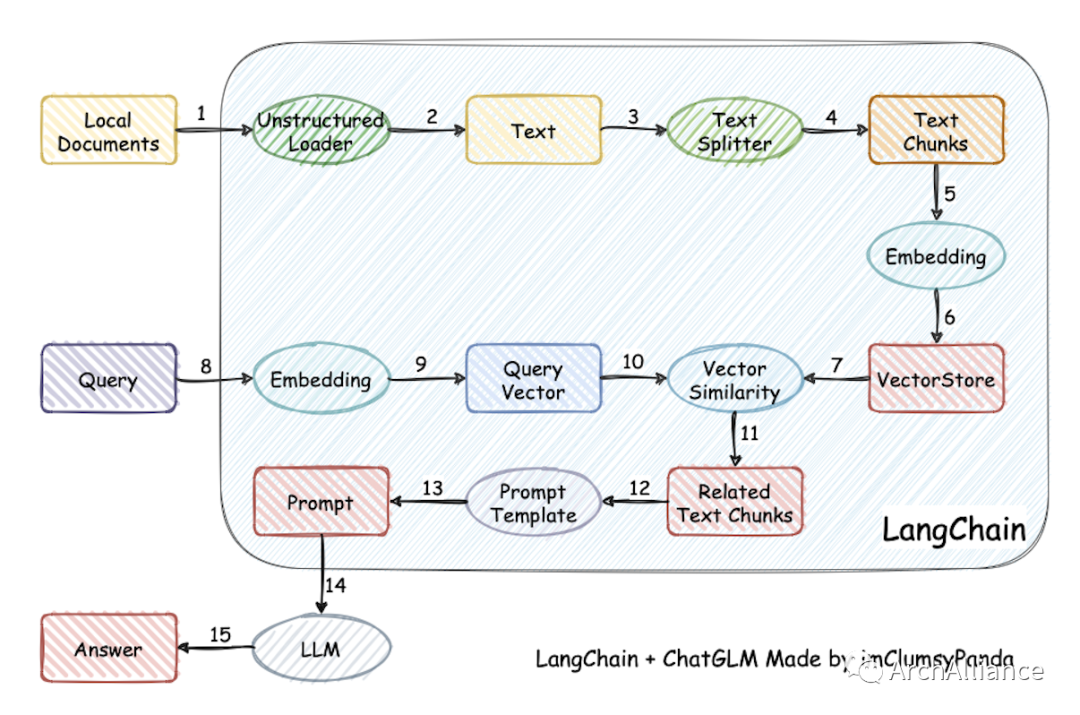
还是以上面的开源项目举例,回答准确能下手的地方:
-
数据质量:导入的文档已经是清洗过的,信息集中度高,就像FAQ。类似导入制度、手册这种,效果会差。
-
文本切割:在load_file函数中,针对不同类型可指定不同分割器,这里可根据自己的文档去定制如何切割更符合实际场景。model_config中有SENTENCE_SIZE是指切割时单句的最大长度,太长或非常短的话向量化后匹配就不精准。还有前面所提的FAQ,可以用txt导入,按固定切割符切割。
-
搜索匹配:在get_knowledge_based_answer函数中,chunk_conent控制是否上下文关联(context_expand),chunk_size控制上下文关联时关联的幅度有多大。如果是FAQ,只需context_expand_method向forward扩展一段文本。另外VECTOR_SEARCH_TOP_K控制取匹配的前几个文档,非常明确的话就配为1。
VECTOR_SEARCH_SCORE_THRESHOLD是相关度过滤,比如设置300以下,那回答非常准确,不过这和问题的质量也有关系。
-
大模型:prompt、temperature、top_p。prompt比较关键,毕竟一个听话的大模型,prompt里可以控制不乱说。可以在prompt模板里加上“不要在答案里添加已知信息不存在的内容”。但更多的是少说了,所以还会加上“请把答案的已有内容全部罗列出来”。temperature设置低点,top_p高点。
















 3573
3573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











