






从前的深度学习主要关注以文字为代表的序列结构和以图片为代表的平面结构,并且处理这些数据的方式也已经比较成熟。但是有一种有一种更为常用的结构还没有解决——图结构。
因而GNN(Graph Neural Networks:图神经网络)就成了当时的研究热点。简单了解GNN只需知晓一点点图论的数据结构~
具体的GNN内容可以研读一下这篇博客A Gentle Introduction to Graph Neural Networks
GNN概括
什么是GNN?
A GNN is an optimizable transformation on all attributes of the graph (nodes, edges, global-context) that preserves graph symmetries (permutation invariances).
GNN 是对图的所有属性(节点、边、全局上下文)的可优化转换,它保留了图的对称性(排列不变性)。
GNNs adopt a “graph-in, graph-out” architecture meaning that these model types accept a graph as input, with information loaded into its nodes, edges and global-context, and progressively transform these embeddings, without changing the connectivity of the input graph.
GNN 采用“图输入,图输出”架构,这意味着这些模型类型接受图作为输入,在不更改输入图的连通性的情况下,将信息加载到其节点、边缘和全局上下文中,并逐步转换这些嵌入。
简单结构
图分为有向图和无向图(暂不考虑成环)。那么图上的信息也就是两种:节点(node)和边(edge)。
一个简单的图结构如下:
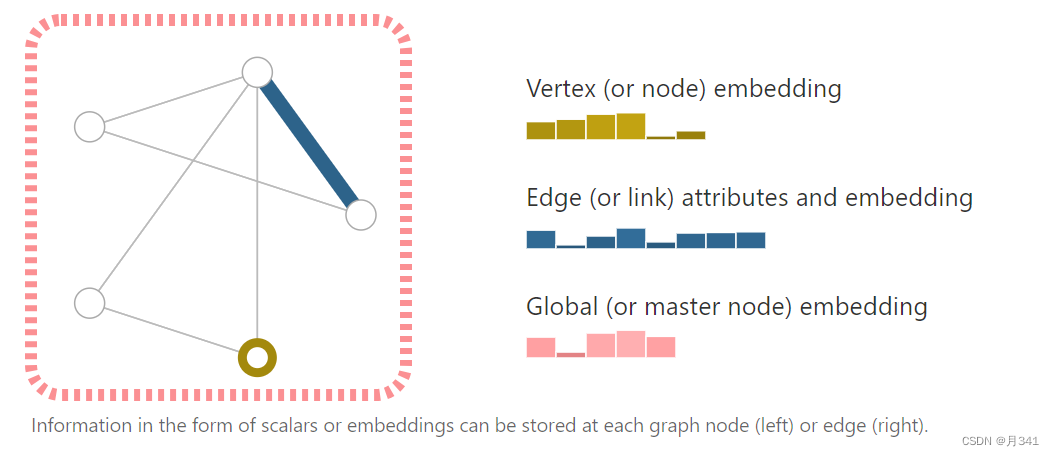
在图神经网络里,需要的嵌入有三种:
- V 节点属性(Vertex (or node) attributes)
- E 边属性位置(Edge (or link) attributes and directions)
- U 全图属性(Global (or master node) attributes)
V向量中包含的是每个节点自身的信息,E向量中包含的是节点与节点相连的边所包含的信息。
这个U向量就比较抽象了,表示的是全图的信息。其表示的结构非传统的节点和边,它在有些地方被称为master node,或者是context vector。这个节点可以和图上的任何一个节点相连,也可以和任何一条边相连。这个其实就比较抽象,点和点连接还是可以接受,那边和点连接,在图里面其实是难以表示的。
听说在算法里这个点被叫做超级源点…
在输入Embedding的时候可能会用到邻接矩阵和邻接表的概念。
我们可以用邻接矩阵来表示一个图的信息。以上方图片的图为例,以黄色的节点为1号点,顺时针编号至5号点。可以得到邻接矩阵:
(
0
1
0
1
0
1
0
0
1
0
0
0
0
1
1
1
1
1
0
1
0
0
1
1
0
)
\left( \begin{matrix} 0 & 1 & 0 & 1 & 0\\ 1 & 0 & 0 & 1 & 0\\ 0 & 0 & 0 & 1 & 1\\ 1 & 1 & 1 & 0 & 1\\ 0 & 0 & 1 & 1 & 0 \end{matrix} \right)
0101010010000111110100110
- 主对角线的元素代表节点,一般来说是0(自环除外)
- 第 i i i行 j j j列的元素代表第 i i i个节点和第 j j j个节点之间有没有边,有则为1(重边除外)
- 邻接矩阵是对称阵
有向图的邻接矩阵也是差不多的~
派别
GNN通常分为频域(Spectral domain)和空域(Vertex domain)两个派别,这两个派别都有非常优秀的模型存在。
Spectral domain
Spectral domain是GCN(图卷积神经网络)的理论基础,这种思路是借助谱图的理论来实现拓扑图上的卷积操作。
什么是谱图理论?
在线性代数里,我们知道矩阵相乘可以看做是线性变换或者是对应的某种运动。简单来说,当矩阵恰好是一个图的邻接矩阵的时候,这样的矩阵描述了一种在图上的类似于热力扩散的运动,其矩阵的特征值和特征向量也有着特殊的含义。
了解谱图理论相关的可以参考这篇文章谱图理论(spectral graph theory)
当然,本人的线性代数现在也是遗忘的比较多,所以开始从拉普拉斯矩阵和傅里叶变换讲起的GCN学起有点对我不太友好…
Vertex domain
Vertex domain是比较直观的方式,通过找到每个节点相邻的节点来提取拓扑图上的空间特征。一般来说需要逐个节点进行处理。
GAT就是Vertex domain GNN的代表模型。
GAT(Graph Attention Networks)
实现GAT的方法很简单,只需实现图注意力网络(GAL)的每一层,然后将每一层进行堆叠。对的,简单粗暴的。
Graph Attentional Layer
该层的输入是一组节点特征,可以理解为向量组。用
h
h
h来表示,
h
=
{
h
⃗
1
,
h
⃗
2
,
.
.
.
,
h
⃗
N
}
h=\{\vec h_1, \vec h_2,...,\vec h_N\}
h={h1,h2,...,hN},其中,
N
N
N代表节点的个数,每个节点的特征个数用
F
F
F来表示。
经过该层后,得到一组新的节点特征,每个节点的特征个数假设变为了
F
′
F'
F′,那么得到输出
h
′
=
{
h
⃗
1
′
,
h
⃗
2
′
,
.
.
.
,
h
⃗
N
′
}
h'=\{\vec h_1', \vec h_2',...,\vec h_N'\}
h′={h1′,h2′,...,hN′}。
论文中作者解释,如果要想得到这样的效果并且能够将输入特征提取为更高级的特征,则至少需要一个可学习的用于线性变换的矩阵。因而,权重矩阵
W
W
W顺理成章地提出。
W
W
W的维度设定为
F
′
×
F
F'×F
F′×F。
我们不难得知,每一个
h
⃗
\vec h
h的维度是
F
×
1
F×1
F×1,对于任意的
h
⃗
i
,
h
⃗
j
∈
h
\vec h_i,\vec h_j\in h
hi,hj∈h,都有着相同的维度。那么我们就可以得到任意节点
i
i
i对任意节点
j
j
j的原始注意力分数
e
i
j
e_{ij}
eij。
e
i
j
=
a
(
W
h
⃗
i
,
W
h
⃗
j
)
e_{ij}=a(W\vec h_i,W\vec h_j)
eij=a(Whi,Whj)
这里的
a
a
a是一个映射,用于计算出注意力分数用的。论文中用的是单层前馈神经网络(a single-layer feedforward neural network)实现的。
可以看到矩阵相乘后
W
h
⃗
i
,
W
h
⃗
j
W\vec h_i,W\vec h_j
Whi,Whj的维度都变为了
F
′
×
1
F'×1
F′×1。熟悉线性代数就可以看出,这里括号中的逗号是什么意思了。这其实就是相当于对两个矩阵进行拼接(concatenate)。也就是说后面那个矩阵的最终维度是
2
F
′
×
1
2F'×1
2F′×1,那么显而易见,我们要得到作为一个数的注意力分数,
a
a
a矩阵的维度自然是
1
×
2
F
′
1×2F'
1×2F′。
算出原始的注意力分数就可以了吗?回看Transformer中的自注意力,还是缺了归一化的。最终注意力分数
α
i
j
\alpha_{ij}
αij的计算公式如下:
α
i
j
=
s
o
f
t
m
a
x
(
L
e
a
k
y
R
e
L
U
(
a
⃗
T
[
W
h
⃗
i
∣
∣
W
h
⃗
j
]
)
)
\alpha_{ij}=softmax(LeakyReLU(\vec a^T[W\vec h_i||W\vec h_j]))
αij=softmax(LeakyReLU(aT[Whi∣∣Whj]))
首先看“||”的符号,在论文中其实它代表的意思就是拼接,和上文分析的是一样的效果。
这里出来个全新的权重向量
a
⃗
T
\vec a^T
aT,其实就是上文提到的
a
a
a,只不过论文中是在这里正式说明的,并且定义它的维度是
2
F
′
×
1
2F'×1
2F′×1,所以这里严谨地加上了转置~
再看到这个奇怪的
L
e
a
k
y
R
e
L
U
LeakyReLU
LeakyReLU是个什么东西。其实作者也只是交代了一下使用它,并没有说明理由,可能也是试出来的?它和ReLU函数一样,作为激活函数,不同的是在x<0的时候,取斜率为0.2而不是直接置0。
左图即为归一化注意力分数计算的图示。
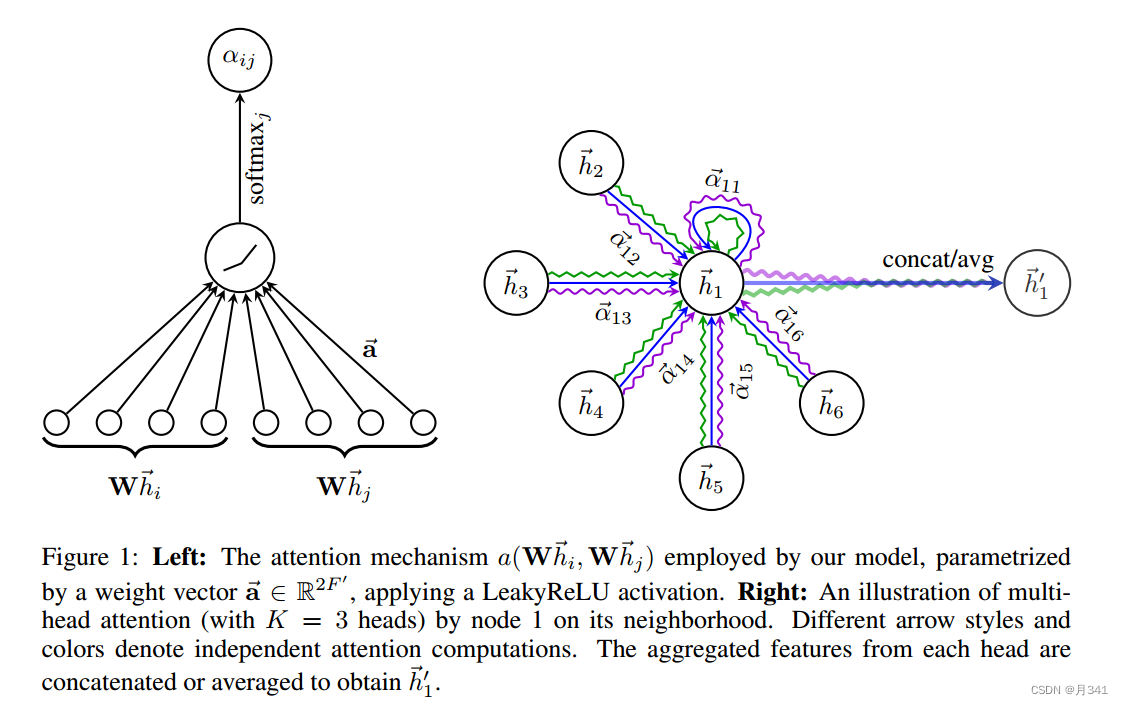
得到了每个节点的注意力分数,那就可以开始计算预设的输出
h
′
=
{
h
⃗
1
′
,
h
⃗
2
′
,
.
.
.
,
h
⃗
N
′
}
h'=\{\vec h_1', \vec h_2',...,\vec h_N'\}
h′={h1′,h2′,...,hN′}了。
h
⃗
i
′
=
σ
(
∑
α
i
j
W
h
⃗
j
)
\vec h_i'=\sigma(\sum \alpha_{ij}W\vec h_j)
hi′=σ(∑αijWhj)
这里的
σ
\sigma
σ是激活函数的意思,同上文用的
L
e
a
k
y
R
e
L
U
LeakyReLU
LeakyReLU。
但或许,这么得到的输出还不够完美呢?
在Transformer中对于Attention的计算采用了Multi-Head Attention的做法,并且效果不错。那想必这里也是要用来优化一下的。
假设有K个Head,输出
h
′
h'
h′的计算公式就变为
h
⃗
i
′
=
∥
k
=
1
K
σ
(
∑
α
i
j
k
W
k
h
⃗
j
)
\vec h_i'=\|_{k=1}^{K}\sigma(\sum \alpha_{ij}^{k}W^k\vec h_j)
hi′=∥k=1Kσ(∑αijkWkhj)上图中的右边即是当k=3时的计算情况,每一条波浪线就代表着一条Head的计算,最后的处理也是将它们进行拼接。
中间层的计算按上述公式进行,但是最后一层即输出层是要发生变化的。作者说因为在输出层再对多头进行拼接是不明智的,并且也需要替换激活函数。 h ⃗ i ′ = σ ( 1 K ∑ k = 1 K ∑ α i j k W k h ⃗ j ) \vec h_i'=\sigma(\frac {1}{K}\sum_{k=1}^{K}\sum \alpha_{ij}^{k}W^k\vec h_j) hi′=σ(K1k=1∑K∑αijkWkhj)这里的 σ \sigma σ换成了 s o f t m a x softmax softmax。















 6972
6972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









