







本文地址http://blog.csdn.net/mounty_fsc/article/details/51092920
本部分内容为[1]CUDA_C_Programming_Guide.pdf中笔记
1 限定符
1.1 函数限定符
| 限定符 | 执行 | 调用 |
|---|---|---|
__device__ | device | device |
__global__ | device | host(计算能力3.x可device ) |
__host__ | host | host |
1.2 变量限定符
| 限定符 | 变量位置 | device访问 | host访问 | 生命周期 |
|---|---|---|---|---|
__device__ | device(global memory default) | 所有线程 | 通过运行时库 | application |
__constant__ | constant memory | 所有线程 | 通过运行时库 | application |
__shared__ | shared memory of a thread block | 块内线程 | 不可访问 | block |
- 注:
__device__可以与__constant__或__shared__配合使用
2 内建类型变量
2.1 内建类型
- 基本类型:char, short, int, long, longlong, float, double
- 向量类型:基于基本类型,如int1,int2,int3,int4,uint4等等,每一维分别由x,y,z,w访问
- 维度类型:dim3,基于unit3,未初始化的维度赋值为1
2.2 内建变量
| 变量 | 类型 | 说明 |
|---|---|---|
| gridDim | dim3 | 一般用2维 |
| blockDim | dim3 | 一般用2维 |
| blockIdx | uint3 | 当前grid中block索引 |
| threadIdx | uint3 | 当前block中thread索引 |
| warpSize | int | warp size in threads(1.0:24,>1.0:32) |
- warp 线程束
3 Kernels
Kernels为从CPU上调用,在GPU上执行的函数。该函数由GPU上的线程执行N次。
定义方式为:
__global__ void Func(float* parameter);调用方式为:
Func<<< Dg, Db, Ns, S >>>(parameter);其中:
- Dg规定了Grid包含Block的维度(尺寸),类型为dim3
- Db规定了Block包含Thread的维度(尺寸),类型为dim3
- Ns规定了每个Block中动态分配的共享存储器(shared memory)大小(可选,默认为0)
- S为流(可选,默认流为0)
4 线程层次
4.1 线程层次
为 一个Grid -> 多个Block -> 多个Thread
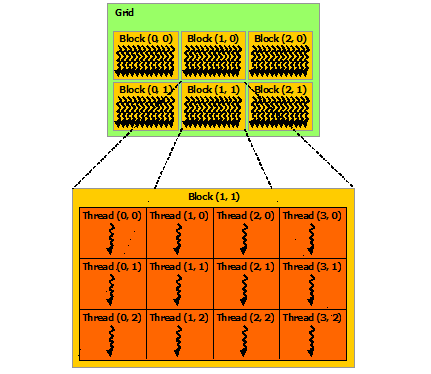
4.2 线程索引
- 列优先
- 一维block:线程索引x与线程ID相等
- 二维block(Dx,Dy):索引index (x, y)的线程ID为 (x + yDx)
- 三维block(Dx,Dy,Dz):索引index (x, y, z)的线程ID为(x + yDx + zDxDy)
4.3 其它
- 当前一个block最多可以有1024个线程(老一点设备为512)
5 存储器层次
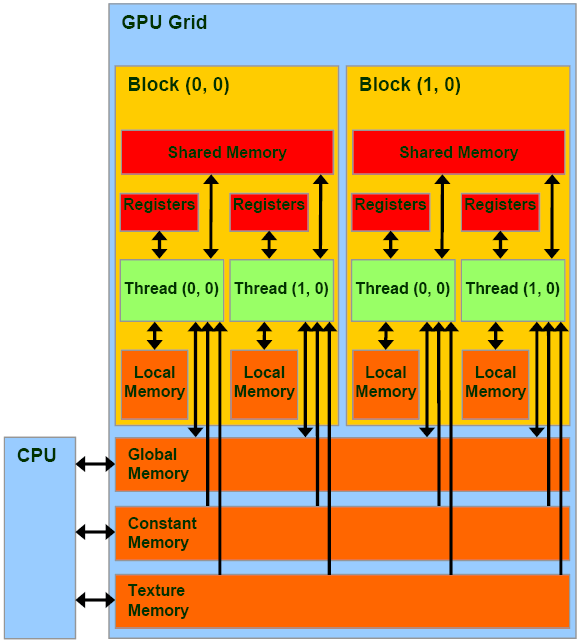
- 常量、纹理存储器为只读















 80
80

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









