







本文转自知乎,已获作者授权转载,请勿二次转载。
链接:https://zhuanlan.zhihu.com/p/339126633
前言

这篇论文是对 MMDet 团队参加今年7月份举办的 LVIS 2020 竞赛的技术报告 (LVIS2020-MMDet) 一个更加详细完善的阐述。
在此之前,我们主要研究 COCO 这类均衡分布的目标检测数据集,并提出了一系列方法来提高检测精度(例如 Hybrid Task Cascade,Guided Anchoring,Libra R-CNN, CARAFE, Prime Sample Attention, Side-Aware Boundary Localization)。
这次我们着眼于长尾分布的目标检测/实例分割数据集 LVIS v1.0, 指出了限制检测器在长尾分布数据上性能的一个关键原因:施加在尾部类别(tail class)上的正负样本梯度的比例是不均衡的。
因此,我们提出 Seesaw Loss 来动态地抑制尾部类别上过量的负样本梯度,同时补充对误分类样本的惩罚。Seesaw Loss 显著提升了尾部类别的分类准确率,进而为检测器在长尾数据集上的整体性能带来可观的增益。
一分钟速读
本文指出了尾部类别上的正负样本梯度的不平衡是影响长尾检测性能的关键因素之一。为了解决这个问题,我们提出了 Seesaw Loss 来针对性地调整施加在任意一个类别上的负样本梯度。给定一个尾部类别和一个相对更加高频的类别,高频类施加在尾部类上的负样本梯度将根据两个类别在训练过程中累计样本数的比值进行减弱。
同时为了避免因负样本梯度减弱而增加的误分类的风险,Seesaw Loss 根据每个样本是否被误分类动态地补充负样本梯度。Seesaw Loss 有效地平衡了不同类别的正负样本梯度,提高了尾部类别的分类准确率,在长尾目标检测/实例分割数据集LVIS v1.0带来了上显著的性能提升。
Motivation
在长尾分布的数据集中(例如:LVIS),大部分训练样本来自头部类别(head class),而只有少量样本来自尾部类别(tail class)。因此在训练过程中,来自头部类别的样本会对尾部类别施加过量的负样本梯度,淹没了来自尾部类别自身的正样本梯度。
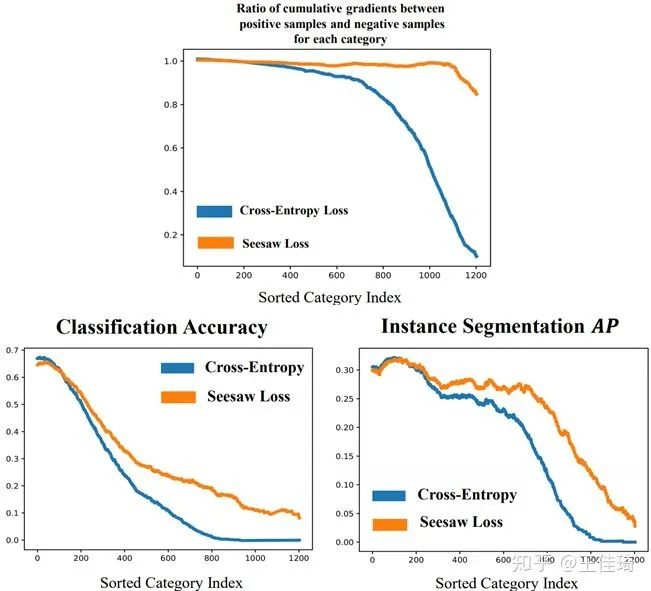
这种不平衡的学习过程导致分类器倾向于给予尾部类别很低的响应,以降低训练的loss。如下图所示,我们统计了在 LVIS v1.0 上训练Mask R-CNN过程中,施加在每个类别的分类器上正负样本累计梯度的分布。
显然,头部类别获得的正负样本梯度比例接近1.0,而越是稀有的尾部类别,其获得的正负样本梯度的比例就越小。由此带来的结果就是分类的准确率随着样本数的减少而急剧下降,进而严重影响了检测器的性能。
方法概述
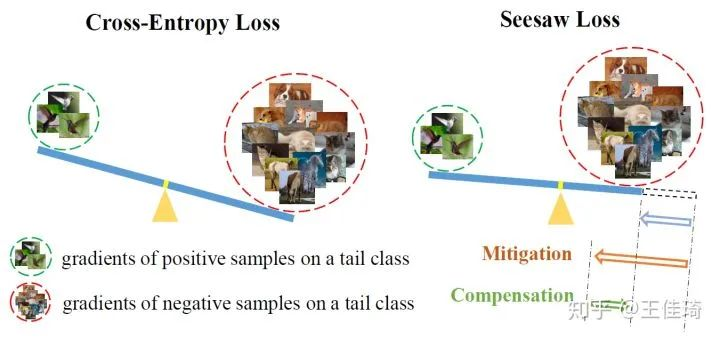
为了方便直观理解,我们可以把正负样本梯度不均衡的问题,类比于一个一边放有较重物体而另一边放有较轻物体的跷跷板(Seesaw),如下图所示。为了平衡这个跷跷板,一个简单可行的方案就是缩短重物一侧跷跷板的臂长,即减少重物的重量在平衡过程中的权重。
回到正负样本梯度不均衡的问题,我们提出了 Seesaw Loss 来动态地减少由头部类别施加在尾部类别上过量的负样本梯度的权重,从而达到正负样本梯度相对平衡的效果。
Seesaw Loss的数学表达如下
是one-hot label,
是每一类预测的 logit。
此时,对于一个第 类的样本,它施加在第
类上的负样本梯度为
这里我们可以发现 就像一个平衡系数,通过调节
,我们可以达到放大或者缩小第
类施加在第
类上的负样本梯度的效果。这样,我们就可以通过选择合适
来达到平衡正负样本梯度的目的。
在 Seesaw Loss 的设计中,我们考虑了两方面的因素,一方面我们需要考虑类别间样本分布的关系(class-wise),并据此减少头部类别对尾部类别的"惩罚" (负样本梯度);
另一方面,盲目减少对尾部类别的惩罚会增加错误分类的风险,因为部分误分类的样本受到的惩罚变小了,因此对于那些在训练过程中误分类的样本我们需要保证其受到足够的"惩罚"。据此, 由两项相乘得到
(Mitigation Factor)用来缓解尾部类别上过量的负样本梯度,
(Compensation Factor)用来补充那些错误分类样本上的"惩罚"。
【Mitigation Factor】
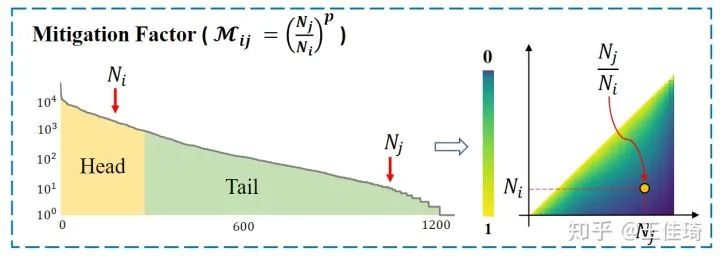
既然正负样本梯度不平衡的问题来自于样本数量的不平衡,那么一种直接有效的办法就是根据不同类别之间样本数量的相对比例来进行调节。在训练过程中,Seesaw Loss在线地统计每一类的累计训练样本数量 ,并根据如下公式计算
,
也就是说当第 类比第
类更加高频率地出现时,Seesaw Loss 就会自动根据两类之间不平衡的程度来减少第
类对第
类施加的负样本梯度。
此外,我们在线地累计样本数量,而非使用预先统计的数据集样本分布,这样的设计主要是因为一些高级的样本 sampling 方式会改变数据集的分布(例如:repeat factor sampler, class balanced sampler 等)。在这种情况下,预先统计的方式无法反映训练过程中数据的真实分布。
【Compensation Factor】
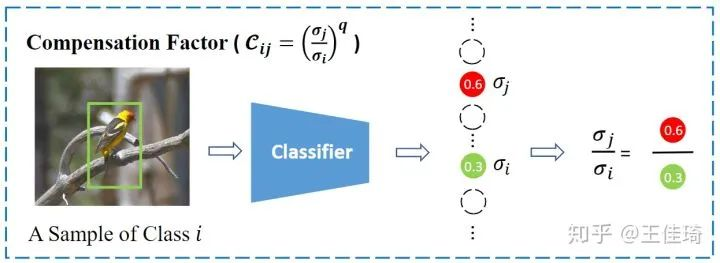
为了防止过度减少负样本梯度而带来的分类错误,Seesaw Loss会增加对那些错误分类样本的惩罚。具体来说,如果一个第 类的样本错误分给了第
类,Seesaw Loss会根据两类之间的分类置信度的相对比值来适当的增加对第
类的惩罚。
的计算如下,
【Normalized Linear Activation】
受到face recognition,few-shot learning等领域的启发,Seesaw Loss在预测分类logit的时候对weight和feature进行了归一化处理,即
【针对Instance Segmentation的其他设计】
1) Objectness 目标检测的分类器起到了两方面的作用,一方面确定候选框(proposal)是前景还是背景,另一方面确定前景的候选框属于哪个类别。通常来说,绝大多数 proposal 来自背景,与之相比任意一个前景类别的样本数量都相对稀少。
为了避免背景类对 Seesaw Loss 平衡前景类别之间正负样本梯度的干扰,我们的设计解耦了分类器的两个功能,即用一个额外的二分类器分辨前景和背景,而原本的分类器只用来区分前景类别并用 Seesaw Loss 监督。测试过程中,检测框的置信度为 ,其中
为类别的置信度,
为前景的置信度。
2)Normalized Mask Predication 类似于分类器,我们设计了一种归一化的Mask预测方式,即
实验结果
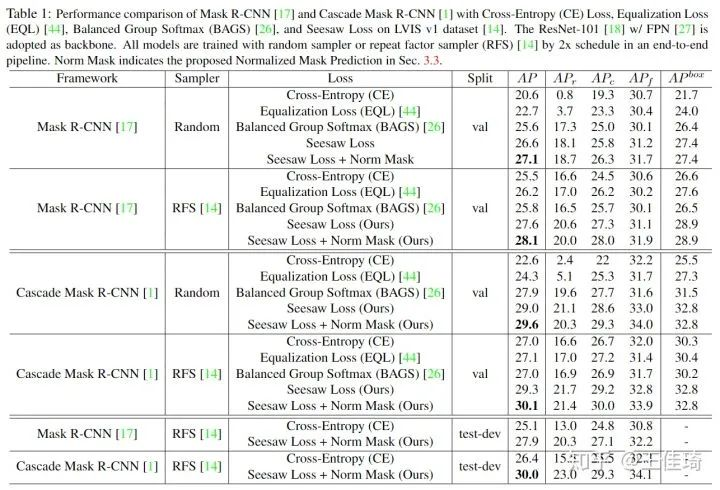
我们在LVIS v1.0 数据集上对 Seesaw Loss 进行了详细的测试。我们分别采用了 Mask R-CNN 和 Cascade Mask R-CNN 作为基础检测器,以及测试了 random sampler 和 repeat factor sampler (RFS) 两种 sampling 策略。
本文方法相比于 EQL 和 BAGS 两种专门为 LVIS 数据设计的方法取得了显著的性能优势,在 end-to-end 训练的情况下在 test-dev 上取得高达30.0 AP的精度。
更多详细的实验分析,消融实验和比赛中使用的 tricks 请详见我们的 Arxiv Paper:https://arxiv.org/pdf/2008.10032.pdf
代码照例将开源到:https://github.com/open-mmlab/mmdetection
我们正在火速整理相关的代码,争取尽快和大家见面。
END

备注:目标检测

目标检测交流群
2D、3D目标检测等最新资讯,若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
投稿:amos@52cv.net
网站:www.52cv.net

在看,让更多人看到 

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









