







0
写在前面
随着ResMLP、MLP-Mixer等文章的提出,基于MLP的backbone重新回到了CV领域。在图像识别方面,基于MLP的结构具有较少的假设偏置,但是依旧能够达到与CNN和Vision Transformer相当的性能。
其中 spatial-shift MLP(S2-MLP)采用了空间移位操作,因此达到了比ResMLP、MLP-Mixer更好的性能。近期,采用了更小的patch和金字塔结构的Vision Permutator (ViP)和Global Filter Network (GFNet) 在性能上又一次超越了S2-MLP。
因此,作者基于S2-MLP,沿着通道维度拓展了特征的维度,并将特征按通道维度分成了多组,每组进行不同的空间移位操作,最后再采用split-attention将这些特征融合起来。
此外,与其他工作一样,作者也采用了更小尺度的patch和金字塔结构来提高图像识别精度。在55M参数 下,作者提出的S2-MLPv2-Medium能够在ImageNet上达到83.6% 的性能(不适用额外的数据预训练,输入图片大小为224x224)。
1
论文和代码地址

S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision
论文:https://arxiv.org/abs/2108.01072
代码:未开源
2
Motivation
近年来,研究者们在更少的假设偏置下实现更高的性能(主要包括Vision Transformer结构和基于MLP的结构)。Vision Transformer模型堆叠了一系列Transformer块,实现了全局感知的效果。MLP-based方法通过MLP将不同patch的信息进行投影,实现不同patch的信息交互,这也是一种全局的信息交互。
为了使得原始的S2-MLP达到更高的性能,S2-MLP的作者重新对S2-MLP结构进行了改进,提出了S2-MLPv2。相比于S2-MLP,S2-MLPv2的改动主要有两个方面:
1)作者沿着通道维度拓展特征图,并将扩展的特征图分割为多个部分。对于不同的部分,作者进行不同的空间移位操作,以增加特征的多样性。最后,作者使用split-attention操作来融合这些分裂的部分。
2)借鉴现有的MLP架构(比如ViP,GFNet,Cycle-MLP等等),作者采用较小的patch和分层金字塔结构。
作者在ImageNet-1K上进行了实验,结果表明S2-MLPv2的图像识别精度达到了SOTA。在使用55M参数的情况下,作者提出的S2-MLPv2-Medium能够在ImageNet上达到83.6%的性能。
3
方法
3.1. Spatial-Shift MLP (S2-MLP)
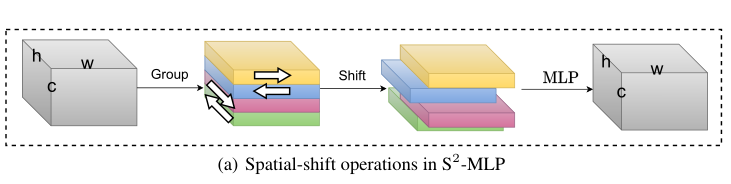
在介绍S2-MLPv2之前,首先回顾一下S2-MLP的做法。S2-MLP的结构如上图所示,主要有三部分组成:patch embedding、一系列S2-MLP block和classification head。
Patch embedding layer
这一步和ViT一样,首先将W × H × 3大小的图像裁剪成w × h个patch。每个patch的大小为p × p × 3, p =W/w =H/h。然后通过全连通层将每个patch映射为一个d维向量。
Spatial-shift MLP block

如上图所示,Spatial-shift MLP block由4个用于混合通道的MLP层和一个用于spatial shift的mixing patch。
spatial-shift层的输入为一个w x h x c的特征X,首先X在通道维度上被均分为了四份,然后对每一份分别做四个不同方向(长、宽的正、负方向)的shift操作,用公式表示如下(其实就是沿不同方向偏移一个单位的距离):
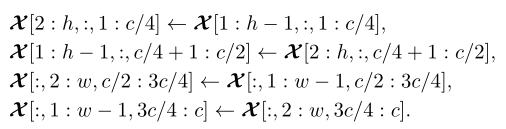
S2-MLP 的N个spatial-shift MLP块采用了相同的设置,并且没有像GFNet那样采用金字塔结构。
Split Attention
ViP[1]中采用了ResNest中提出的Split Attention来将不同操作之后的feature map进行融合。具体实现上,对于给定的K个nxc的特征图 (其中n是patch的数量,c是通道数量),Split Attention首先K个特征图空间的信息进行了求和,计算如下:
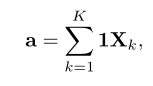
这里的 就是一个长度为n,内容全部为1的向量(将 和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









