







关注公众号,发现CV技术之美
本文分享 AAAI 2022 论文『Task-Customized Self-Supervised Pre-training with Scalable Dynamic Routing』,思考预训练的数据不是越多越好?并由港科大&华为诺亚实验室提出具有可扩展动态路由的自监督预训练范式SDRNet,在分类和检测任务上SOTA!
详细信息如下:

论文链接:https://www.aaai.org/AAAI22Papers/AAAI-12678.LiuZ.pdf
01
摘要
近年来,自监督学习(SSL)尤其是对比学习方法因其能够在无语义标注的情况下学习有效的可迁移表示而备受关注。自监督预训练的常见做法是使用尽可能多的数据。然而,从本文的大量实验中观察到,对于特定的下游任务,在预训练中涉及无关数据可能会降低下游性能。另一方面,对于现有的SSL方法,在针对不同任务的预训练中使用不同的下游任务定制数据集比较繁琐。
为了解决这个问题,作者提出了一种称为可扩展动态路由(Scalable Dynamic Routing,SDR)的新SSL范式,该范式可以训练一次,并使用任务定制的预训练模型有效地部署到不同的下游任务。具体地说,作者用不同的子网构造SDRnet,并通过数据感知渐进式训练,仅用数据的一个子集训练每个子网。当下游任务到达时,在所有预训练的子网之间进行路由,以获得最佳的子网及其相应的权重。
实验结果表明,本文的SDR可以在ImageNet上同时训练256个子网,这比在完整ImageNet上训练的统一模型提供了更好的迁移性能,在11个下游分类任务上达到了最先进的平均精度,在PASCAL VOC检测任务上达到了SOTA结果。
02
Motivation
最近,自监督学习(SSL)引起了人们的广泛关注,它通过无语义标注的借口任务(pretext task)学习表征。SSL的最新研究表明,与监督学习相比,SSL在各种下游任务上的表现具有竞争力,甚至更好。
SSL可以在模型预训练中使用大量未标记数据。然而,在自监督的预训练中,更多的数据是否总能带来更好的迁移性能?换言之,对于特定的下游任务,预训练中的无关数据会影响下游性能吗?
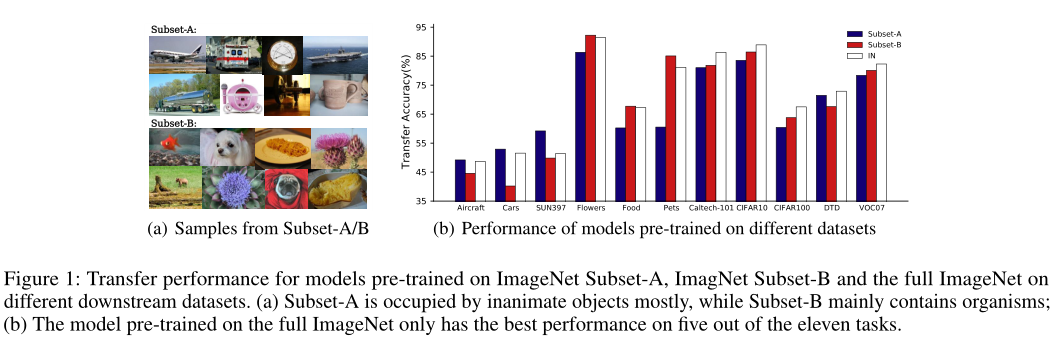
为了回答上述问题,作者进行了一系列实验。作者基于它们在WordNet Tree中的语义差异,故意将ImageNet拆分为两个不相交的子集,即子集A和子集
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 63
63











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









