






关注公众号,发现CV技术之美
本篇分享 ECCV 2024 Oral 论文Towards Open-ended Visual Quality Comparison, Co-Instruct: 让通用多模态大模型学会比较视觉质量。

作者:Haoning Wu等
论文链接:https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/00422.pdf
Git链接:https://github.com/Q-Future/Co-Instruct
亮点直击
本文提出了Co-Instruct数据集,通过训练激发通用多模态大模型潜在的对多图的理解能力,从而实现开放式的视觉质量比较。这一数据集协同利用了蒸馏GPT-4V对多图质量的判断+LLM对人类单图质量标注的整合,在感知类开放式质量比较任务上实现了超过GPT-4V的效果。
经过Co-Instruct训练的多模态大模型不止可以比较多张图片整体质量的好坏,还可以更细粒度的比较各种和质量相关的问题(“哪一张图片清晰度最高?”,“哪一张图片更真实?”;尽管训练数据全部是定性比较,在Compare2Score(Neurips2024)测试中,Co-Instruct也证明了拥有最好的零样本定量比较能力。
作为多模态大模型基础的能力之一,Co-Instruct数据集已经被集成到多个知名开源框架中,如最新的LLaVA-OneVision, mPLUG-Owl3等,为这些通用模型赋予了相同的开放式的视觉质量比较能力;Co-Instruct亦已被集成到开源多模态大模型多图训练框架Mantis)中。
方法
总览:数据建构的原则
尽管人工标注被广泛认为是收集数据的最直接方法,但在大量图像上获取足够的比较数据相较于在相同图像集合上获取意见需要显著增加的标注量。为了避免这种难以承受的成本,我们提出了一种无需额外人工标注的合成式数据构建策略,遵循以下三个关键原则:
转换(Convert):利用现有数据集中的可靠信息。
从模型中学习(Learn-from-Model):利用模型经过验证的能力。
共同指导(Co-Instruct):收集能够相互补充的多样化子集。
基于这些原则,我们收集了用于指令微调的两个不同子集:Merge2Compare,该方法将人类对单幅图像的质量描述以及单模态大模型比较和分析文本的能力相结合;以及 Teach2Compare,该方法利用了 GPT-4V 在图像比较上的验证能力。最后,我们探讨了在共同指导(co-instruct)框架下,这两个子集如何相互补充。
第一个子集:Merge2Compare

作为第一个子集(不依赖任何其他的多模态大模型),Merge2Compare通过对图像描述进行配对、筛选和合并,用于生成高质量的比较数据。其目标是最大程度利用现有的图像描述以及开源的单模态模型,减少人工标注成本,并确保最终数据的准确性和多样性。
流程:
配对/分组匹配:从现有的图像质量描述中(Q-Instruct数据集,CVPR2024)随机选取81K图像对、27K三图组和18K四图组,以确保涵盖不同场景和多样化的图像组合。
去除高相似度配对:使用文本嵌入模型计算描述之间的相似性,去除任何高相似度的配对或分组,确保对比数据具备信息增益。筛选后,保留70K图像对、20K三图组和10K四图组。
大模型合并:利用大模型(LLMs)将单幅图像的评价转化为对比性文本,并为描述添加合理推理。最终的人工抽检验证显示,Merge2Compare生成的比较数据准确率高达96%,验证了其高质量的数据构建能力。
第二个子集:Teach2Compare

作为第二个子集,Teach2Compare 方法的选择来自于GPT-4V已经被验证的强大的视觉比较能力。因此,本文用GPT-4V生成两种伪标签子集:Teach2Compare-general(整体质量比较)和 Teach2Compare-Q&A(问答对)。首先,作为Teach2Compare的准备,本文从各种来源收集9K图像,以涵盖不同质量和视觉外观:
5.4K原始世界图像:从 YFCC-100M 数据库中提取。
1.8K人工失真的图像:来自 COCO 数据库,包括 15 种 ImageCorruptions 和 KADIS-700K 中的失真类型。
1.8K AI生成的图像:来自 ImageRewardDB。这些图像进一步分组为 18K 对、6K 三图组和 6K 四图组,由 GPT-4V 提供伪标签,生成以下两种格式的子集:
Teach2Compare-general:类似于 Merge2Compare,general 子集也包含整体质量比较及其推理。具体来说,将 Merge2Compare 提示模板中的 <desc_i> 替换为相应真实图像 <img_i>,并输入至 GPT-4V。为了验证伪标签的质量,对 250 个样本进行检查,准确率约为 94%。尽管略低于 Merge2Compare(96%),但人工评估表明,GPT-4V 标签包含了更多的内容信息,从而增强了模型对质量的理解。这两个不同来源的子集彼此互补,有助于更好地学习。
Teach2Compare-Q&A:除了整体比较,Teach2Compare 还收集了一个专门子集,以提升多模态大模型在处理开放性问题上的能力。为了收集这些问答,本文首先列出参考维度(例如清晰度、光照、颜色等);然后要求 GPT-4V 基于这些维度生成关于图像对比的提问(以及相应的正确答案和错误答案);最终删除生成失败的问答对,保留 230K 个问答对,涵盖 30K 张图像组。这些问答对转换为直接问答训练样本和多选样本,以支持开放式问题(简答题)和多选题的训练。
为什么选择这样的结合?
本文将 Merge2Compare 和 Teach2Compare 这两个子集结合的动机在于它们的互补性,这体现在两个方面:
首先,在一般的图像比较中,Merge2Compare 具有更高的准确率,但由于高相似度配对移除的原因,缺乏对更细粒度比较的支持。而 Teach2Compare-general 虽然准确率略低,但提供了更加多样化的场景,并且包含了内容信息作为背景。因此,将这两个子集共同用于训练,有助于模型在整体上进行更全面的质量比较。
此外,Teach2Compare 还包含了一个独特的问答子集(Q&A subset),显著提升了模型回答开放式问题的能力。这进一步增强了模型在广泛应用中的表现。因此,通过整合这两个子集,我们可以构建一个在质量比较和问答能力上都更为强大的模型。
模型设计
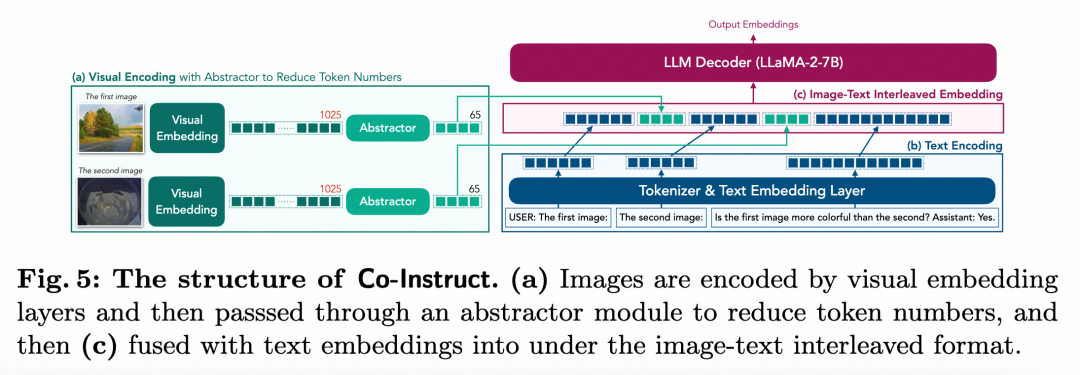
基于所采集的数据集,本文进一步提出所模型 Co-Instruct,并针对多图像比较的场景进行了两项简单而有效的设计创新:
视觉Token压缩:目前大多数先进的大语言模型(LMMs)使用的是简单的投影器,保留了大量的token(例如1,025个)。这种结构不适合多图像的场景:仅传递两张图像就会超过LLaVA模型的最大长度(2,048个),而传递四张图像则会超过LLaMA-2的上下文窗口大小(4,096个)。为了解决这个问题,我们采用了一种广泛使用的压缩结构,将视觉嵌入的token数量在传入模型之前进行压缩,从而能够更好地适应多图像场景。
图文交错格式:传统的单图像指令微调通常不考虑图像的“位置”。大多数方法直接将所有图像堆叠在文本之前<img0> (<img1>...) <text>,这样多个图像就没有区分,LMM可能会混淆来自不同图像的信息,无法有效比较(参见基线结果)。为了改进这一点,我们提出了一种图文交错的格式用于多图像训练:每一张图像之前都会有明确的文本说明其序号,例如:第一张图像:<img0> 第二张图像:<img1> (…) 在我们的实验中,这种交错格式显著提高了 Co-Instruct 的性能,并且明显优于使用特殊token(如 <img_st> 和 <img_end>)来划分图像的方法。
实验分析
双图比较&选择题
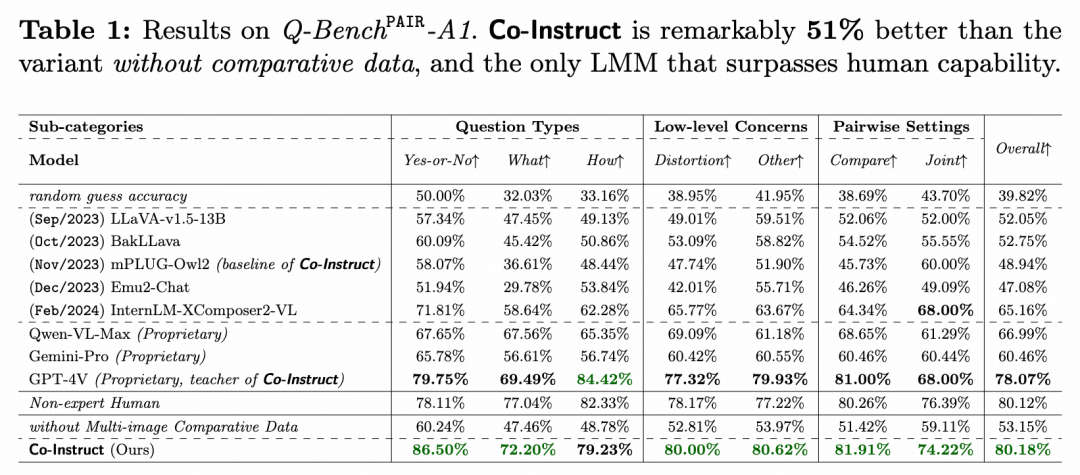
Q-Bench 是一个视觉质量比较的基准测试,包含1,999道由专家精心编写的开放式多选题(MCQs),用来比较图像对的质量。在上表中,我们将 Co-Instruct 与现有的开源和专有模型在这个基准上进行了比较。
Co-Instruct 在准确率上远超开源的多模态大模型,比其基线模型(mPLUG-Owl2)高出 64%,比没有多图像子集(Merge2Compare 和 Teach2Compare)的模型变体高出 51%,并且比所有开源模型的最佳性能还高出 23%。同时,它在准确率上也大幅领先于专有模型 Qwen-VL-Max 和 Gemini-Pro,分别高出 21% 和 33%。
尽管所有训练所用的MCQ数据都来自 GPT-4V,但 Co-Instruct 在这个MCQ评估集上的表现仍比它的“老师”(GPT-4V)高出 2.7%,说明这种协作教学策略的有效性。此外,Co-Instruct 也是唯一一个在基准测试中准确率超过非专家人类水平(尤其在 Compare 子集上)的多模态大模型。这强烈支持了未来使用模型来减轻人类在真实世界视觉质量比较上的工作量的愿景。
双图比较&长描述
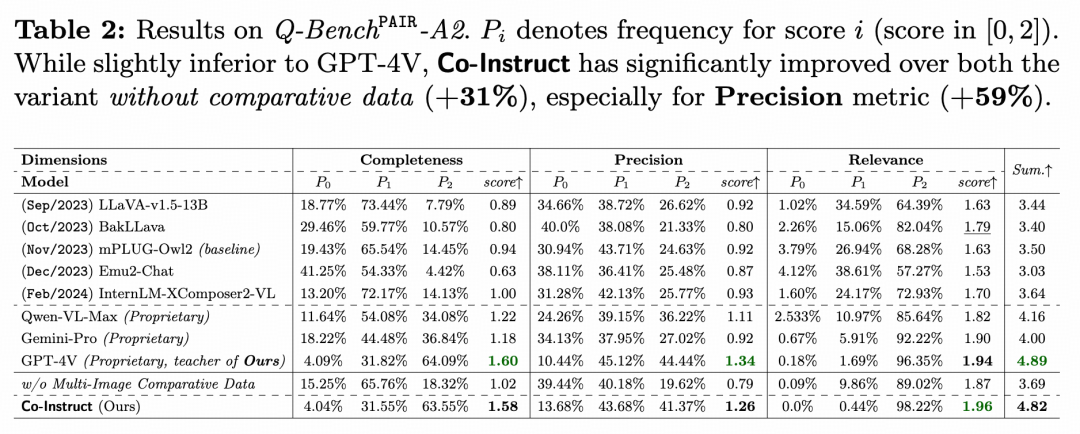
Q-Bench-A2 是一个基准测试,专门用于对图像对进行整体和详细的视觉质量比较,并提供详细的推理。它包含了 499 对图像,通过 GPT 对多模态大模型的输出在完整性(Completeness)、准确性(Precision)和相关性(Relevance)方面进行评估。
如上表所示,Co-Instruct 在比较输出的完整性和准确性上都有显著提升,相较于不包含比较数据的版本,分别提高了 57% 和 59%。在与同类 LMMs 的比较中,Co-Instruct 的表现与 GPT-4V 相当,并且显著超过其他现有多模态大模型。
通过比较进行定量打分
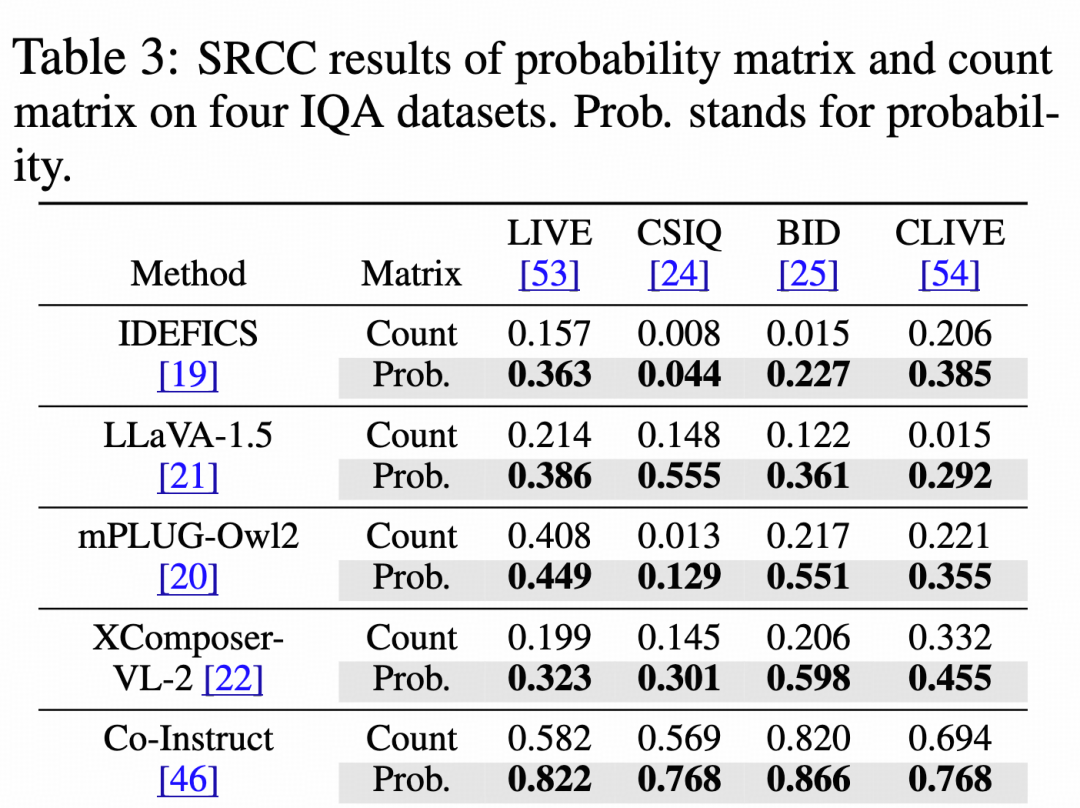
上表展示了来自 Compare2Score(NeurIPS 2024,改进自2AFC-LMM测试)的 SRCC 结果,该论文提供了一种测试方式,通过两种方式将多模态大模型的定性对比输出转化成定量分数(Count:基于生成的文本次数;Prob:基于生成的logits),从而衡量定量意义上的视觉质量比较能力。
Co-Instruct 在两种转换方式下都证明了更好的能力,实现了全数据集领先,相比每个数据集上最强的现有模型大幅提升了38%-83%不等。
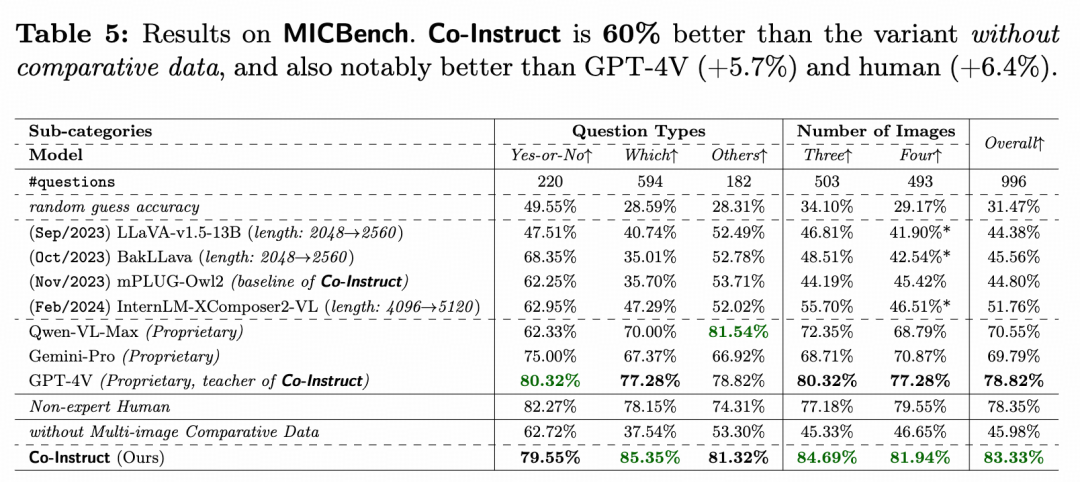
多图比较&选择题
在 MICBench 基准测试(多图比较的选择题)中,Co-Instruct 展现出了极具竞争力的表现。在针对三至四幅图像的开放性质量比较问题上,Co-Instruct 的准确率比目前表现最好的 GPT-4V 高 5.7% ,比非专家人类高 6.4% 。相比之下,其他开源的大模型(LMMs)在此场景下的准确率甚至难以达到 50% 。
此外,值得注意的是,LLaVA 系列和 XComposer2-VL 的原始上下文长度不足以处理四幅图像的任务,因此需要扩展上下文窗口。然而,这些模型在四幅图像组上的表现显著低于三幅图像组,强调了对视觉 token 压缩的重要性(参见方法部分)。这表明 Co-Instruct 在多图像比较任务中的表现优异,部分原因在于其对视觉 token 的有效处理。
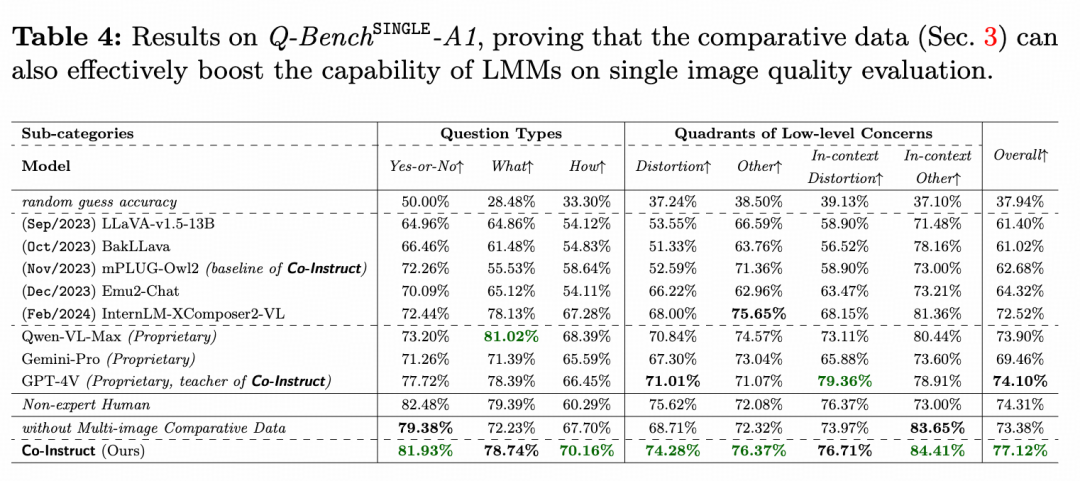
单图问答&选择题
在 Q-Bench-SINGLE-A1 中,我们也评估了 Co-Instruct 在单图像多选题(MCQ)上的表现,以验证比较微调对单图像质量感知的影响。如上表所示,Co-Instruct 相比仅基于单图像训练的模型提高了 5% 的准确率,比 GPT-4V 高 4%,并成为唯一一个超越非专家人类表现的大语言模型(LLM)。
这些结果表明,比较训练对大语言模型在总体质量相关理解上的贡献,并暗示单图像质量评估与多图像质量比较并不冲突,可以在一个统一的模型中共同提升。
结论
本文研究了开放式视觉质量比较问题,目标是构建一个能够在多图像间进行质量比较、并对开放式问题提供答案和详细推理的模型。为实现此目标,我们收集了首个用于微调多模态大模型(LMMs)的指令数据集——Co-Instruct-562K,包括两个子集:由 LLMs 合并的单图像人工标注,以及 GPT-4V 的输出。
在此数据集上,我们提出了 Co-Instruct 模型,其不仅在视觉质量比较中超越了所有现有的 LMMs(包括其“老师”GPT-4V),也是首个在相关任务上超越人类准确率的 LMM。此外,我们还对多图像质量比较进行了基准测试评估,为三张和四张图像的比较提供了参考。我们希望这项工作能够激发未来在视觉质量比较领域的研究。
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「图像质量」交流群👇备注:IQA


















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









