






关注公众号,发现CV技术之美
本文来自遥感与深度学习。分享论文Text2Earth: Unlocking Text-driven Remote Sensing Image Generation with a Global-Scale Dataset and a Foundation Model,介绍了一个 1000 万图像文本对的全球遥感数据集和生成式基础模型Text2Earth。

论文:https://arxiv.org/abs/2501.00895
主页:https://chen-yang-liu.github.io/Text2Earth/
GitHub:https://github.com/Chen-Yang-Liu/Text2Earth
年份:2025
单位:北京航空航天大学

创新点
Git-10M 数据集:引入了一个包含 1000 万图像文本对的全球遥感数据集,覆盖广泛的地理场景和多分辨率图像,大幅度提升了训练多模态生成模型的基础数据多样性。
Text2Earth 模型:提出了一个基于扩散模型的生成基础模型,具有 13 亿参数,支持分辨率控制、无边界场景生成和多任务能力。
动态条件适配策略:提出了训练和推理过程中动态调整条件的机制,以增强模型在条件缺失情况下的生成能力和适应性。
全能任务表现:模型在多任务中展示了通用性,包括零样本生成、场景扩展、图像编辑和跨模态生成。
数据
Git-10M数据

1. 数据集规模和特点
规模
Git-10M 是一个包含 1000 万对图像与文本描述的全球遥感数据集。
数据规模是现有最大的遥感图像-文本数据集的 5 倍(如 RS5M 数据集仅包含 200 万对数据)。
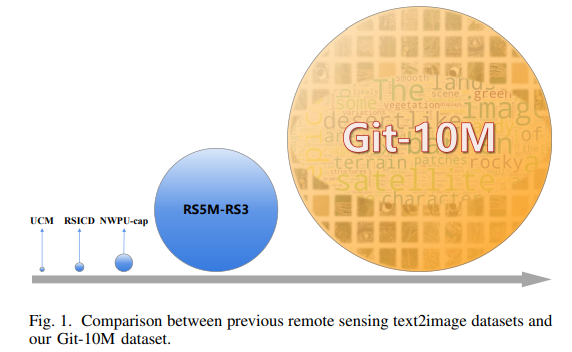
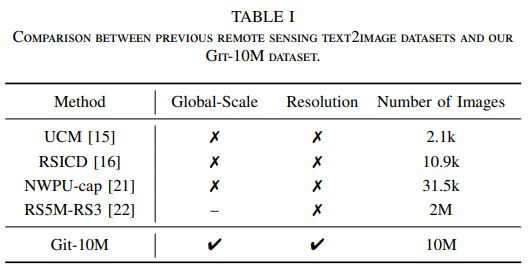
多样性
涵盖全球范围内的典型地理场景,如 城市、森林、沙漠、山地、湿地 等。
包括不同的地理分布和自然特征,增强了数据的空间覆盖性和内容丰富性。
分辨率范围
数据集包含从 0.5m/pixel 到 128m/pixel 的多分辨率图像:
高分辨率图像(如 0.5m/pixel):用于精细特征的捕捉。
低分辨率图像(如 128m/pixel):适用于大范围场景的宏观生成。
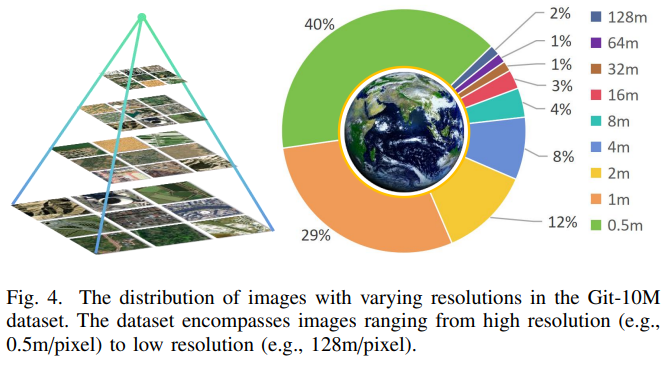
元数据支持
每张图像都附带地理位置和分辨率信息,为生成高精度图像提供了更多上下文信息。
2. 数据来源
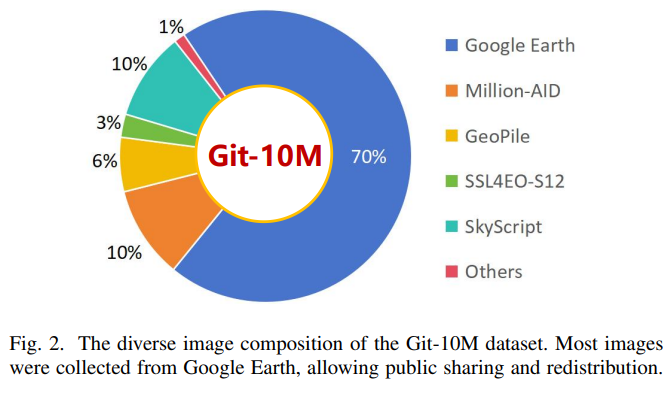
公开数据集
公开数据集来自现有高质量遥感图像数据集,如:
Million-AID
GeoPile
SSL4EO-S12
SkyScript
DIOR
RSICB
手动收集
大部分数据来自从 Google Earth 手动获取的遥感图像,补充了现有公开数据集中未覆盖的地理场景。
3. 数据处理与增强
筛选
去除了重复场景(如大面积的海洋图像),以提高地理分布的多样性。
手动剔除低质量数据,如受噪声或伪影影响的图像。
增强
对所有图像进行质量增强:
使用预训练的高质量遥感图像增强模型,提升图像视觉效果和整体数据质量。
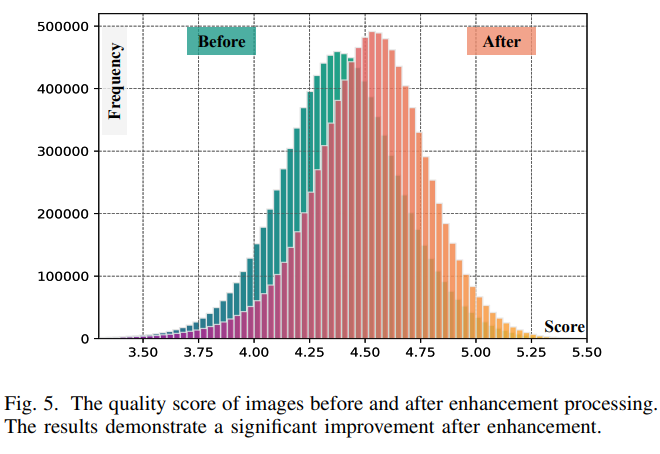
4. 文本注释
自动化注释流程
使用 GPT-4o 模型自动生成高质量的图像文本描述。
通过场景标签(如“机场”)和元数据(如地理位置和分辨率)优化提示词,提高描述的精准性。
质量保证
自动审计:检测 GPT-4o 的超时或错误响应。
手动抽样:定期检查文本描述的语义准确性,并针对问题样本调整提示词后重新生成。
文本统计
平均每条描述包含 52 个词汇。
数据集中总计超过 1050 万条文本描述 和 55 亿个词汇。
5. 数据分析
地理分布:图像覆盖全球范围,包括所有大洲的城市、自然景观和农业场景,确保数据的代表性和多样性。
分辨率分布:包括从高分辨率(0.5m/pixel)到低分辨率(128m/pixel)图像的广泛分布,适应不同的生成任务需求。
图像质量评估:使用审美评分模型评估图像增强前后的质量。增强后的图像质量显著提升,适合作为高可靠性的训练数据。
文本丰富性:通过词云和长度分布分析,文本覆盖了多样化的概念和地物,表明其在语义上的广泛性和细致性。
6. 数据集优势
全球覆盖:克服了现有数据集局限于特定区域的缺点,支持生成真实的全球遥感场景。
分辨率多样性:为模型的分辨率控制能力提供了全面支持。
高质量和多样性:经过严格筛选、处理和增强后的图像和文本,提升了数据的整体质量。
方法
1. 模型架构
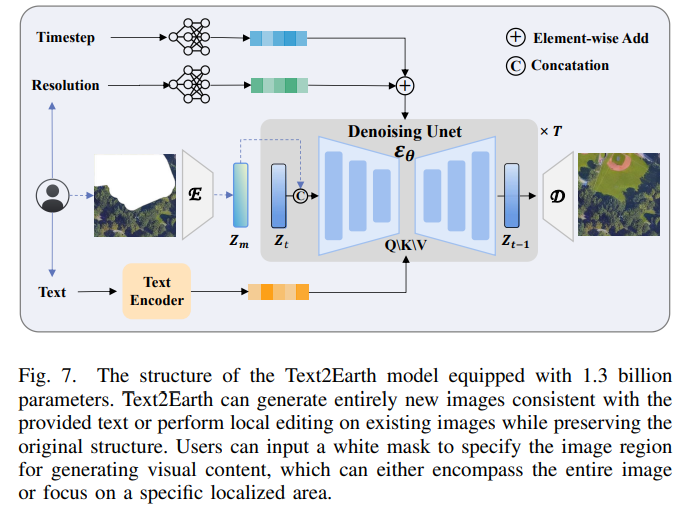
Text2Earth 模型基于扩散框架,核心架构包括:
变分自编码器 (VAE):用于压缩高分辨率图像到隐空间,提高计算效率。
扩散模型:通过逐步去噪还原隐空间表示,生成高质量图像。
条件嵌入机制:
使用 OpenCLIP ViT-H 编码器将文本嵌入高维语义空间。
分辨率信息通过嵌入模块与时间步信息结合,用于指导图像生成。
交叉注意力机制:
文本嵌入通过以下公式与隐变量结合,指导扩散过程:
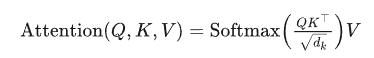
2. 动态条件适配策略 (DCA)
训练中的动态条件丢弃:在训练过程中,随机丢弃一部分条件(文本描述或分辨率信息),让模型在部分或完全缺失条件的情况下学习生成能力。这种策略模拟了真实应用中条件信息不完整的场景,同时提升了模型的多样性和鲁棒性。
推理中的条件指导:融合有条件和无条件预测,平衡生成图像的语义一致性和多样性。条件指导的公式如下:

3. 模型功能与任务
零样本文本生成:根据用户输入文本生成多分辨率的真实遥感图像,无需场景特定的微调。
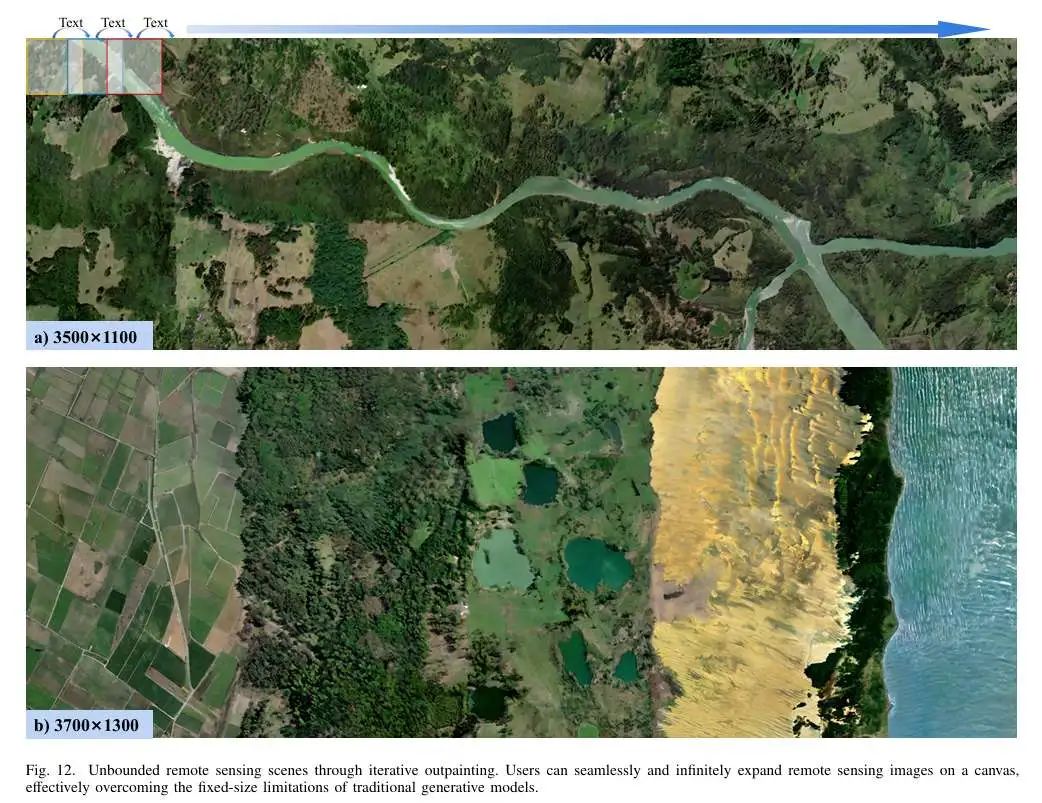
无边界场景生成:支持通过迭代扩展生成超大规模场景图像。
图像编辑:支持局部修改,如去云、地物替换、颜色变化。
跨模态生成:包括基于文本生成多模态图像(RGB、NIR、SAR)及图像跨模态转换。
实验与分析
精度对比
FID (Frechet Inception Distance) 是一种衡量生成模型(如 GAN 或扩散模型)生成的图像质量和多样性的重要指标。
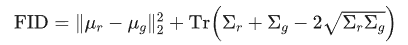
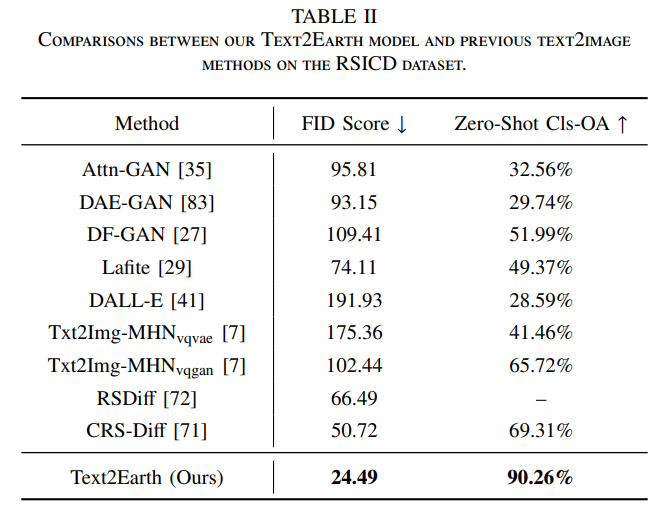
可视化展示
多地理特征的零样本图像生成

多分辨率
图像编辑

无边界场景
多模态和跨模态任务


更多图表分析可见原文。
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「文生图」交流群👇备注:生成


















 1986
1986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









