








博客内容将首发在微信公众号"跟我一起读论文啦啦",上面会定期分享机器学习、深度学习、数据挖掘、自然语言处理等高质量论文,欢迎关注!

本次要分享的是14年论文DeepWalk: Online learning of Social Representations, 论文链接DeepWalk,参考的代码CODE,本论文是图表示学习领域内的一篇较早的文章,是学习图表示学习绕不过的一篇文章,虽然整体难度不大,但是文章所提出的方法个人感觉非常独到和有趣。
论文动机和创新点
-
本论文提出的是一种针对图结构的representation learning方法,其从某种角度来说机器学习或深度学习的发展就是围绕着representation learning方法进行的。
-
在自然语言处理领域,word2vec(以前总结的word2vec)是一个非常基础和著名的词表示方法,利用 句子 中词与词之间的共现或相邻关系,对词进行表示学习,所学习到的词表示向量能准确的刻画词与词之间的实际意义关系。
-
那么在非语言结构的其他结构中,例如图结构中,是否可以根据图中节点与节点相邻关系,来学习每个节点的表示呢?显然是可以的,论文中提出,在图结构中,以任意一个节点为起始节点,进行随机游走,当游走到最长的步数时,可以获取一串由节点构成的序列,这个序列就可以类比自然语言中的句子,节点类比句子中的词,然后利用word2vec的方法对每个节点进行表示学习。
-
该论文所提出的方法是一种无监督的特征学习方法,具体来说,就是从可截断的随机游走中得到一串节点序列,利用word2vec方法学习每个节点的表示向量。我们认为这样学习到的表示向量可以捕捉到节点之间的邻近相似关系以及其所属社区(类别)的关系。
-
论文中讲到所提方法有以下特点
① 适应性:在实际的社交网络中,由社交关系产生的图是不断发展的,而该方法可以自适应的去学习,不必重复从头再学习。
② 社区意识:该方法学习到的隐空间应该表示网络中同质节点或相邻节点的距离远近信息。
③ 低维度:当带标签的数据稀疏和低维度时,模型生泛化能力更好,训练更容易收敛。
④ 连续性:该方法所学习到的表示是连续型的,因此具有光滑的决策边界,鲁棒性更高。 -
论文实验证明了,在缺乏足够的带标签数据时,本文所提方法比其他的无监督表征学习方法效果上更好。
-
个人感觉,本论文在实验部分,某些细节并未讲清,例如图是如何构建的?节点和边的具体业务意义是什么?并未讲清,只是笼统的说,利用这些数据构图,有多少个节点,多少条边。
-
在实际应用时,需根据业务逻辑,定义节点,以及根据某种规则定义连接节点的边,由此可以构成一张图进行表示学习。
Learning Social Representations
图的定义
在社交网络中多分类任务为例:
G
=
(
V
,
E
)
G=(V,E)
G=(V,E)
V 表示图中的节点,节点的含义为图中的类别(member)。 E表示图中的边,
E
⊆
(
V
×
V
)
E\subseteq(V \times{V})
E⊆(V×V)
G
L
=
(
V
,
E
,
X
,
Y
)
G_L=(V,E,X,Y)
GL=(V,E,X,Y) 表示一个带标签的图,其中
X
∈
R
∣
V
∣
×
S
X\in R^{|V| \times{S}}
X∈R∣V∣×S, S表示节点的特征空间大小,
Y
∈
R
∣
V
∣
×
γ
Y \in R^{|V| \times {\gamma}}
Y∈R∣V∣×γ,
γ
\gamma
γ 表示类别个数。
在实际应用中,是需要根据业务的具体逻辑去构建图。
传统的机器学习方法是由X映射到Y,模型所需要学习的是如何准确的学习到这个映射函数。而本论文所提方法是独立于标签的分布信息,由图中的拓扑信息去学习节点的向量表示。是完全无监督学习方法。
该方法所学习到的表示向量可以使用在任何的分类算法中。
随机游走
以任意一个节点为起始节点,每次随机的选择与它邻近节点进行游走,直到达到最大步长。这种截断的随机游走方式提供了两个优点
- 局部探索游走很容易并行化进行,几个不同walker可以同时游走多条不同的线路。
- 从截断随机游走中获取信息,当图结构发生小的变化时,不需要重复重新的去学习。
在实际应用时,方便很多。
长尾分布
在论文指的是power laws,其实和长尾分布大同小异,在自然语言领域,我们发现大部分词的词频都很小,只有少数词的词频很高,符合长尾分布。而在YouTube Social Graph中,进行随机游走,发现节点的分布也是符合这种长尾分布的,如下图所示:

词频分布和节点频率分布一致,因此认为在自然语言处理领域内有效的word2vec方法可以复用在图结构中。
Deep Walk

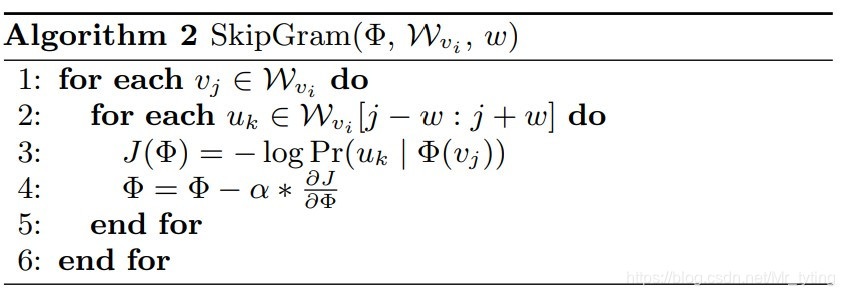
以上两个算法流程已经能很好的说明Deep Walk的步骤,其中SkipGram算法表示由某个节点预测他周围的节点,是word2vec方法中的一种模型。
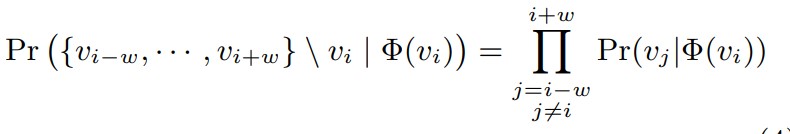
上述公式表示,由节点
v
i
v_i
vi 来预测与之相邻的周围节点
v
j
v_j
vj,其中所得到的副产品
Φ
\Phi
Φ 这个embedding 矩阵就是我们要学习的目标。
和自然语言处理相同,这里的skip-Gram同样面临计算复杂度很高的问题,如果不做任何处理,每次都需要对所有节点进行概率计算,时间复杂度过高,训练缓慢,由此引入了Hierarchical Softmax。
Hierarchical Softmax 是NLP中常用方法,详情可以查看Hierarchical Softmax。其主要思想是以词频构建Huffman树,树的叶子节点为词表中的词,相应的高频词距离根结点更近。当需要计算生成某个词的概率时,不需要对所有词进行softmax计算,而是选择在Huffman树中从根结点到该词所在结点的路径进行计算,得到生成该词的概率,时间复杂度从 O(N) 降低到 O(logN)(N个结点,则树的深度logN)。该方法同样适用在图结构的skip-Gram模型中。
实验
论文中使用了三个数据集:
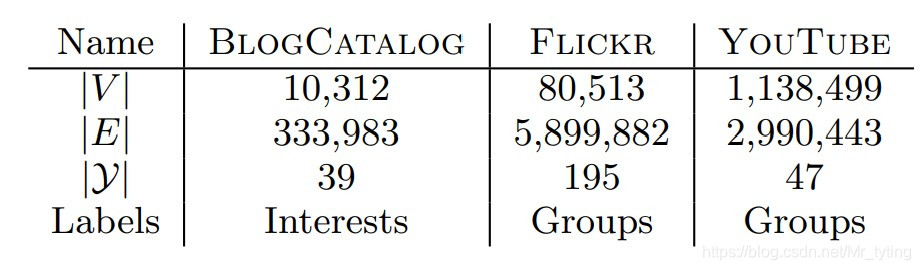
但是论文没有详细给出在三个数据集中,所构成的图结构中节点以及边的实际业务意义,例如在图中,每个数据集中节点具体指的是什么?以什么样的规则来定义边的?
论文实验中,随机抽取部分样本作为训练集(带label),剩余的作为测试集,在训练集中,以上面所说的方式(DeepWalk+Skip-Gram+Hierarchical softmax)学习每个节点的表示向量,然后以学习到的表示向量作为特征,LR分类器进行训练,训练出一个分类模型;再在测试集上进行测试。实验结果如下:
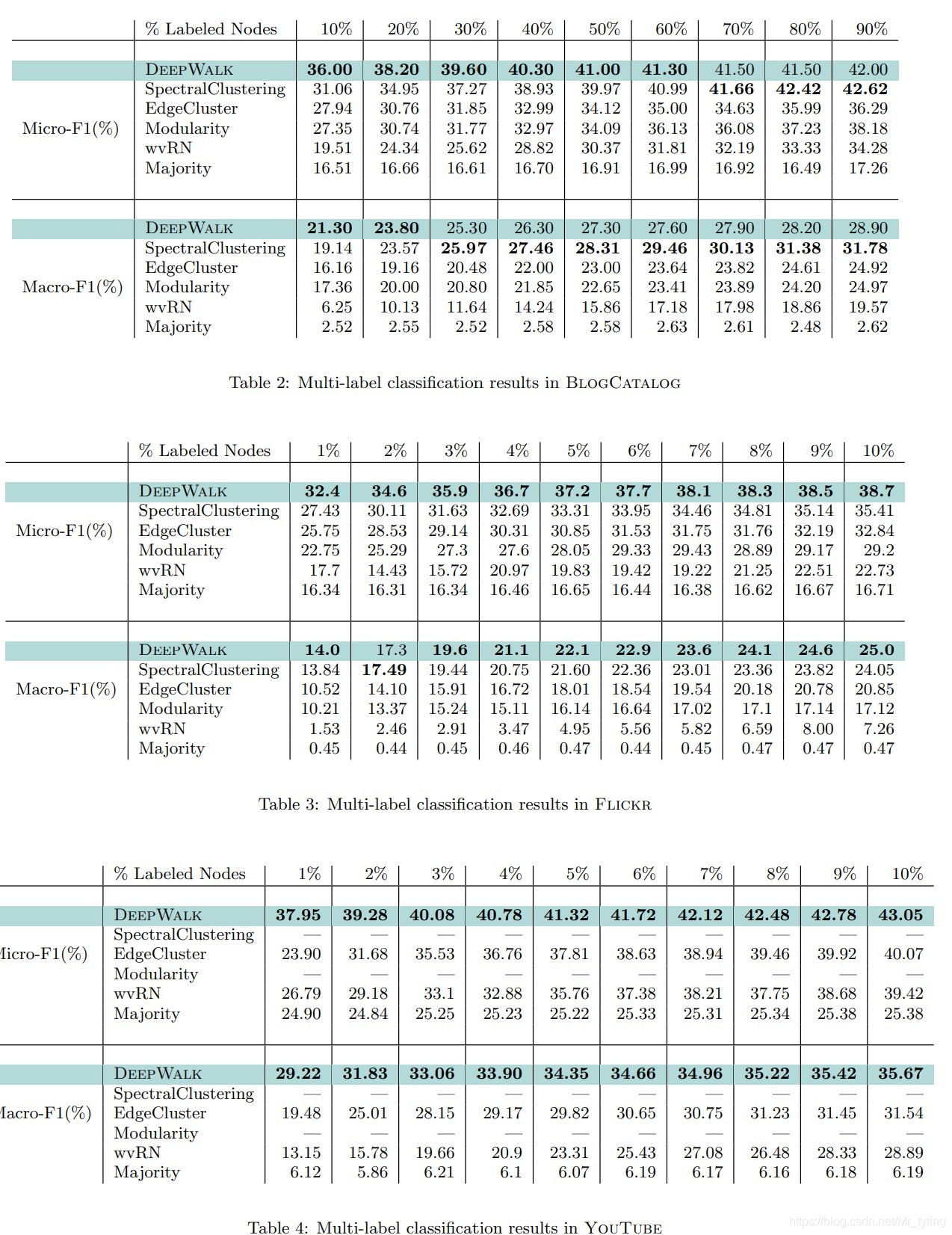
可以看出当选取较少的带label训练数据时(label sparse),相对于其他方法,DeepWalk的效果更好。
个人总结
本文所提方法不难,其word2vec也是很基础的方法,但是能借此应用到图结构中的确很有趣和有意义,使得word2vec这种简单有效的方法能应用的更加广泛。














 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









