







caffe中batch_norm层代码注解
一:BN的解释:
在训练深层神经网络的过程中, 由于输入层的参数在不停的变化, 因此, 导致了当前层的分布在不停的变化, 这就导致了在训练的过程中, 要求 learning rate 要设置的非常小, 另外, 对参数的初始化的要求也很高. 作者把这种现象称为
internal convariate shift
. Batch Normalization 的提出就是为了解决这个问题的. BN 在每一个 training mini-batch 中对每一个 feature 进行 normalize. 通过这种方法, 使得网络可以使用较大的 learning rate, 而且, BN 具有一定的 regularization 作用.
(BN在知乎上的一个解释:
顾名思义,batch normalization嘛,就是“
批规范化”咯。Google在ICML文中描述的非常清晰,即在每次SGD时,通过mini-batch来对相应的activation做规范化操作,使得结果(输出信号各个维度)的均值为0,方差为1. 而最后的“scale and shift”操作则是为了让因训练所需而“刻意”加入的BN能够有可能还原最初的输入(即当
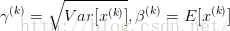
),从而保证整个network的capacity。(有关capacity的解释:实际上BN可以看作是在原模型上加入的“新操作”,这个新操作很大可能会改变某层原来的输入。当然也可能不改变,不改变的时候就是“还原原来输入”。如此一来,既可以改变同时也可以保持原输入,那么模型的容纳能力(capacity)就提升了。)以上部分的链接:https://www.zhihu.com/question/38102762/answer/85238569
)
Batch Normalization 算法

二:caffe中的batch_norm层
Reshape()中是bn层需要的一些变量的初始化,代码如下
template <typename Dtype>
void BatchNormLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
if (bottom[0]->num_axes() >= 1)
CHECK_EQ(bottom[0]->shape(1), channels_);
top[0]->ReshapeLike(*bottom[0]);
vector<int> sz;
sz.push_back(channels_);
mean_.Reshape(sz);//通道数,即channel值大小,存储的是均值
variance_.Reshape(sz);//通道数,即channel值大小,存储的是方差值
temp_.ReshapeLike(*bottom[0]);//temp_中存储的是减去mean_后的每一个数的方差值。
x_norm_.ReshapeLike(*bottom[0]);
sz[0]=bottom[0]->shape(0);
batch_sum_multiplier_.Reshape(sz);//batch_size 大小
int spatial_dim = bottom[0]->count()/(channels_*bottom[0]->shape(0));//图像height*width
/*
*spatial_sum_multiplier_是一副图像大小的空间(height*width),并初始化值为 1 ,
*作用是在计算mean_时辅助通过乘的方式将一副图像的值相加,结果是一个数值
*/
if (spatial_sum_multiplier_.num_axes() == 0 ||
spatial_sum_multiplier_.shape(0) != spatial_dim) {
sz[0] = spatial_dim;
spatial_sum_multiplier_.Reshape(sz);
Dtype* multiplier_data = spatial_sum_multiplier_.mutable_cpu_data();//分配一副图像的空间
caffe_set(spatial_sum_multiplier_.count(), Dtype(1), multiplier_data);//初始化值为 1,
}
int numbychans = channels_*bottom[0]->shape(0);//batch_size*channel
if (num_by_chans_.num_axes() == 0 ||
num_by_chans_.shape(0) != numbychans) {
sz[0] = numbychans;
num_by_chans_.Reshape(sz);
//batch_sum_multiplier_ batch_size大小的空间,也是辅助在计算mean_时,将所要图像的相应的通道值相加。
caffe_set(batch_sum_multiplier_.count(), Dtype(1),
batch_sum_multiplier_.mutable_cpu_data());//分配空间,初始化为 1,
}
}
Forwad_cpu()函数中,计算均值和方差的方式,都是通过矩阵-向量乘的方式来计算。计算过程,对照上面的公式,代码如下:
template <typename Dtype>
void BatchNormLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
int num = bottom[0]->shape(0);
int spatial_dim = bottom[0]->count()/(bottom[0]->shape(0)*channels_);//spatial_dim值是 图像height*width
//如果底层的blob与顶层的blob不是同一个blob
if (bottom[0] != top[0]) {
caffe_copy(bottom[0]->count(), bottom_data, top_data);
}
if (use_global_stats_) {
// use the stored mean/variance estimates.
const Dtype scale_factor = this->blobs_[2]->cpu_data()[0] == 0 ?
0 : 1 / this->blobs_[2]->cpu_data()[0];
caffe_cpu_scale(variance_.count(), scale_factor,
this->blobs_[0]->cpu_data(), mean_.mutable_cpu_data());
caffe_cpu_scale(variance_.count(), scale_factor,
this->blobs_[1]->cpu_data(), variance_.mutable_cpu_data());
} else {
// compute mean 计算均值
//将每一副图像值相加为一个值,共有channels_ * num个值,然后再乘以 1/num*spatial_dim,结果存储到blob num_by_chans_中
caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim, //channel*num 行;spatial_dim 列,大小是height*width
1. / (num * spatial_dim), bottom_data,
spatial_sum_multiplier_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
//上面计算得到的值大小是num*channel, 将图像的每个通道的值相加,最后获得channel个数值,结果存储到mean_中
caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1.,
num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0.,
mean_.mutable_cpu_data());
}
// subtract mean
//将channels_个值的均值mean_矩阵扩展到num_*channels_*height*width,并用top_data数据减去均值
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1,
batch_sum_multiplier_.cpu_data(), mean_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels_ * num,
spatial_dim, 1, -1, num_by_chans_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 1., top_data);//用blob top_data中的数据减去mean_值
if (!use_global_stats_) {
// compute variance using var(X) = E((X-EX)^2)
caffe_powx(top[0]->count(), top_data, Dtype(2),
temp_.mutable_cpu_data()); // (X-EX)^2 //对向量的每一个值求方差,结果存储到blob temp_中
caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim,
1. / (num * spatial_dim), temp_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());//同上计算 mean_的方式,矩阵 向量 乘
caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1.,
num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0.,
variance_.mutable_cpu_data()); // E((X_EX)^2)//同上计算 mean_的方式,矩阵 向量 乘 (此处num_by_chans_转置)
// compute and save moving average
this->blobs_[2]->mutable_cpu_data()[0] *= moving_average_fraction_;
this->blobs_[2]->mutable_cpu_data()[0] += 1;
// blob_[0] = mean_ + moving_average_fraction_* blob_[0];
caffe_cpu_axpby(mean_.count(), Dtype(1), mean_.cpu_data(),
moving_average_fraction_, this->blobs_[0]->mutable_cpu_data());//Y=alpha*X+beta*Y;
int m = bottom[0]->count()/channels_;// m = num*height*width;
//blob_[1] = bias_correction_factor * variance_ + moving_average_fraction_ * blob_[1]
Dtype bias_correction_factor = m > 1 ? Dtype(m)/(m-1) : 1;
caffe_cpu_axpby(variance_.count(), bias_correction_factor,
variance_.cpu_data(), moving_average_fraction_,
this->blobs_[1]->mutable_cpu_data());
}
// normalize variance
caffe_add_scalar(variance_.count(), eps_, variance_.mutable_cpu_data());//将 variance 每个值加一个很小的值 eps_,防止除 0的情况。
caffe_powx(variance_.count(), variance_.cpu_data(), Dtype(0.5),
variance_.mutable_cpu_data()); // 对 variance的每个值 求开方。
// replicate variance to input size
//以下这两个函数同上面的mean_一样,将channels_个值的方差variance_矩阵扩展到num_*channels_*height*width
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1,
batch_sum_multiplier_.cpu_data(), variance_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels_ * num,
spatial_dim, 1, 1., num_by_chans_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 0., temp_.mutable_cpu_data());
caffe_div(temp_.count(), top_data, temp_.cpu_data(), top_data);//top_data 除以 temp_
// TODO(cdoersch): The caching is only needed because later in-place layers
// might clobber the data. Can we skip this if they won't?
caffe_copy(x_norm_.count(), top_data,
x_norm_.mutable_cpu_data());//将 最后的结果top_data 数据复制 到 x_norm_中。
}(完)














 1657
1657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









