







 本文介绍了BatchNorm(批量归一化)在机器学习中的作用,特别是如何解决神经网络训练中的InternalCovariateShift问题,以及其在加速训练、稳定梯度和替代Dropout的角色。它通过在每层输入前进行归一化处理,引入可学习参数来保持激活函数的有效性。
本文介绍了BatchNorm(批量归一化)在机器学习中的作用,特别是如何解决神经网络训练中的InternalCovariateShift问题,以及其在加速训练、稳定梯度和替代Dropout的角色。它通过在每层输入前进行归一化处理,引入可学习参数来保持激活函数的有效性。
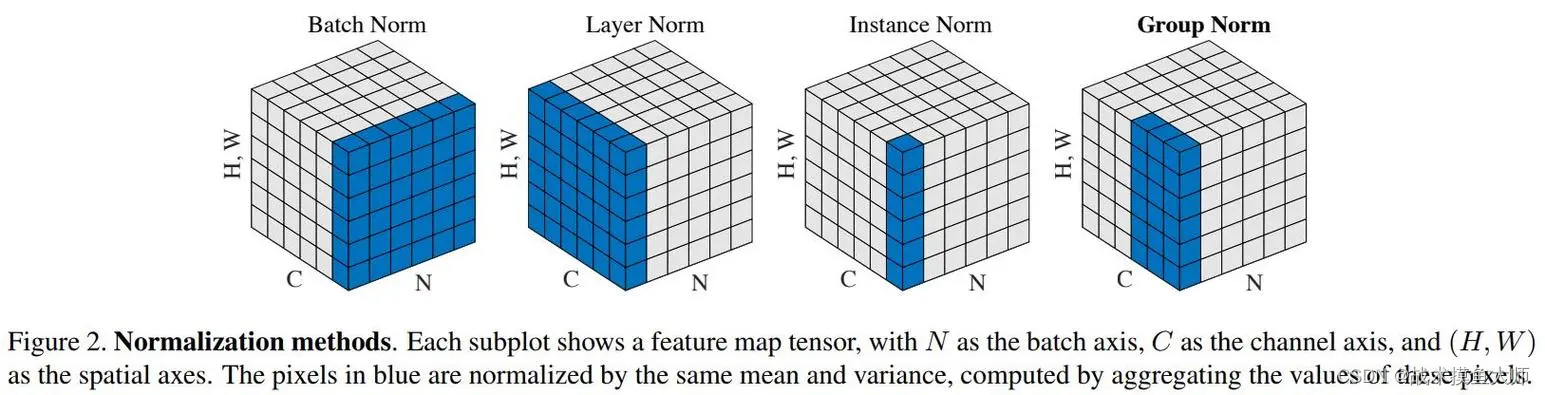
作用
之前上机器学习课程的时候老师讲归一化的作用,说归一化的作用是将不同的特征的尺度归一化到同一个量级,例如人的身高和脚的长度,这两个特征的值大小不在一个数量级,如果输入前不进行归一化会导致数量级大的特征主导模型,而数量级小的特征的影响自然就较小。
这种说法没有错,不过这个作用是指的训练前的尺度归一化,BatchNorm批归一化的作用与训练前数据的尺度归一化还是略有不同的。BatchNorm的作用要从机器学习中的一个假设谈起:IID独立同分布假设,也就是训练集和测试集的数据分布是相同的。
机器学习算法的本质就是学习训练集数据的分布情况,并将学习到的分布规律应用到测试集上,如果训练集和测试集不是独立同分布的,那么学到的分布规律自然也就没用了。
机器学习中为了满足IID假设,会对输入进行归一化,称为“白化”,最典型的白化方法就是PCA,白化的结果满足特征之间具有独立性,还满足所有特征同分布。
对于神经网络的单个层来说,这样的假设依然有作用。
对于一个神经网络的一层来说,他接受的输入是上一层的输出,并输出给下一层,在神经网络的训练过程中,每次前向推理完后模型的参数就要发生一次更新,参数的不同,每次输出数据的分布也不相同。因此每一次神经网络中每层的输入的分布都是不一样的,这样就加大了网络的训练难度,这种问题叫做Internal Covariate Shift(内部协变量转移)
在机器学习中有一个分支专门研究对于不符合IID假设的情况的机器学习应用,如transfer learning转移学习,domain adaptation领域自适应等,Covariate Shift就是不符合IID假设情况的一个子问题,即条件概率相同,但是边缘概率不同【也就是相对概率是相同的,但是绝对概率不同】,神经网络的这种情况符合这个子问题的定义,所以就被称为Internal Covariate Shift(内部协变量转移)
所以就提出了BatchNorm,通过在每一层之间加入批归一化层,就可以有效防止这种分布改变的问题。
所以BatchNorm的作用即:
加速训练,避免梯度爆炸和梯度消失的作用也有,不过不是重点
原论文中还提到,加了BatchNorm就可以把dropout给删掉了,BatchNorm可以起到相应的作用。
原理
BatchNorm的思想也很简单,既然每次更新会导致分布改变,那我直接在每层输入前都进行一次归一化处理,将输入归一化到固定均值,固定方差的分布然后再进行计算不就解决了?实际上也就是这么做的哈哈哈哈。
但是并不是用的PCA方法,因为PCA的计算量太大,神经网络的输入也不是很在乎是否相互独立,如果不是为了加速训练,内部是否满足同分布也不关心,只要input的训练集和测试集满足即可,里面什么样无所谓。
但是并没有那么简单,如果只是简单的归一化,会影响到精度,因为每一层的输出都是要经过激活函数的,如果只是暴力归一化,那激活函数约等于没用了,反正最后都会被归一化。所以BN中引入了可学习参数
γ
\gamma
γ和
β
\beta
β,具体公式为:
x
t
=
x
i
−
μ
σ
2
+
ϵ
y
=
γ
(
x
t
)
+
β
\begin{align} x_t &= \frac{x_i-\mu}{\sqrt[]{\sigma ^2}+\epsilon } \\ y &= \gamma(x_t)+\beta \end{align}
xty=σ2+ϵxi−μ=γ(xt)+β
其中 μ \mu μ是输入均值, σ 2 \sigma^2 σ2是方差, ϵ \epsilon ϵ是为了保持稳定加上的一个常量
当然,实现的时候不会又xt,这里只是为了方便理解添了个中间量xt
这里的 μ \mu μ选择输入的均值而不是整个训练集的均值这一点,在BN原论文里花了好大一段文字解释,在我们现在看来理所当然的方案,在提出时经过了慎重的论证,并且援引了前人的成果。我们现在已经习惯了一个batch一个batch的训练方式,但当时神经网络刚复兴没多久,SGD这种传统机器学习中的算法在神经网络中有没有用,有多大用,都是需要经过论证的。可能多少年后我们现在的技术也会被后人认为是理所应当的哈哈哈哈。
还有需要注意的一点是,在推理时BN中的均值和方差用的是输入的均值和方差,不再需要从所有输入中挑选几个作为batch计算均值和方差
和上文提到的一样,这种做法在我们现在看来理所应当,因为我们现在的算力比起当时已经不知道翻了多少翻了哈哈哈哈。
实现
官方文档链接
Pytorch中的BN操作为:
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
# num_freatures:输入的channel数
# eps,就是上文提到的,为了计算稳定加的常数
# momentum:跟踪记录训练阶段中的平均值和方差用的,滑动平均的参数,更详细的作用看官方文档
# affine:是否进行仿射变换,即是否进行添加从xt到y这一步,如果false,那么就直接把xt当作y,不添加gamma和beta
# tracking_running_stats:是否记录训练阶段的均值和方差,如果设为false,那么momentum也就没用了
pytorch中添加一个BN层的代码:
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv = nn.Conv2d(3, 16, 3, 1, 1)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
# 创建一个模型实例
model = MyModel()
# 创建一个随机输入张量
input = torch.randn(1, 3, 32, 32)
# 通过模型传递输入
output = model(input)
如果觉得有帮助,可以点赞+关注。















 2050
2050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









