



原论文:Query Rewriting for Retrieval-Augmented Large Language Models
公众号版本:提升大型语言模型性能的新方法:Query Rewriting技术解析
在人工智能飞速发展的今天,大型语言模型(LLMs)已成为处理复杂问题的关键技术。然而,它们在知识准确性和时效性方面仍面临挑战。本文将深入探讨一种新兴的解决方案——Query Rewriting技术,它为提升LLMs的性能开辟了新思路。
这篇论文提出了经典的RRR框架。
论文地址:https://arxiv.org/abs/2305.14283
git地址是:https://github.com/xbmxb/RAG-query-rewriting
下面我们来仔细研究一下这篇论文。
动机
大型语言模型(LLMs)在处理知识密集型任务方面取得了显著进展,但它们仍面临事实性错误和时效性不一致的问题。为了解决这些问题,研究者们提出了检索增强的方法,通过检索模块为语言模型提供相关的外部知识。
摘要
大型语言模型 (LLM) 在检索-然后读取管道中发挥强大的黑盒阅读器作用,在知识密集型任务中取得显着进展。 这项工作从查询重写的角度引入了一个新的框架,Rewrite-RetrieveRead,而不是以前的检索增强LLM的检索然后读取。 与之前专注于适应检索器或读者的研究不同,我们的方法关注搜索查询本身的适应,因为输入文本和检索所需的知识之间不可避免地存在差距。 我们首先提示法学LLM生成查询,然后使用网络搜索引擎检索上下文。 此外,为了更好地将查询与冻结模块对齐,我们为我们的管道提出了一个可训练的方案。 采用小型语言模型作为可训练的重写器,以满足黑盒 LLM 读者的需求。 通过强化学习,利用 LLM 读者的反馈来训练重写器。 对下游任务、开放域 QA 和多项选择 QA 进行评估。 实验结果显示了一致的性能改进,表明我们的框架被证明是有效的和可扩展的,并为检索增强的LLM带来了新的框架。
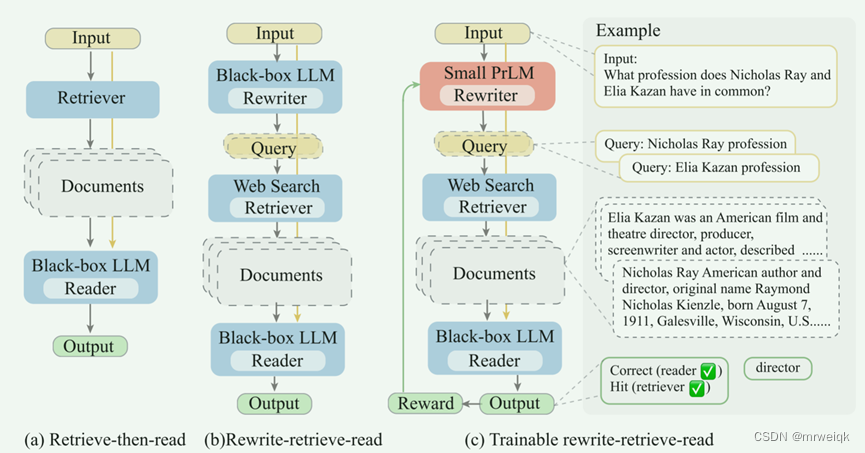
对模型图的解释:A:常规的检索和黑盒LLM读取+输出的过程。B:将输入使用LLM进行改写成query,将这个query输入到web进行检索,得到检索后的文档。
RRR(Rewrite-Retrieve-Read)出现的动机:完全依赖冻结的法学硕士也存在一些缺点。 推理错误或无效搜索会阻碍性能(Yao et al., 2023;BehnamGhader et al., 2022)。 另一方面,检索到的知识有时可能会误导和损害语言模型(Mallen et al., 2022)。 为了更好地适应冻结的模块,可以添加可训练的模型并通过将 LLM 读者的反馈作为奖励来对其进行调整。
• 查询重写:根据原始输入生成查询,以更好地检索所需知识。
• 检索:使用搜索引擎检索相关上下文。
• 阅读:结合输入和检索到的上下文进行阅读理解并预测输出
该论文使用了微调T5+强化学习来调整最终的结果。首先是重写阶段re-writer
- 我们提示LLM重写训练集中的原始问题x,并收集生成的查询〜x作为伪标签,然后进行过滤。
- 接着,那些被正确预测的样本会被加入到warm-up数据集,
这个数据集用来训练模型。
但是这个数据集并不稳定,模型性能也取决于数据集的质量,所以作者采用强化学习进行接下来的训练。
强化学习
把任务转换成马尔可夫决策过程(S,A,R,T,y),详细可以看原论文。
模型
使用T5作为rewriter,使用bing搜索作为retriver,reader是GPT3.5和Vicuna-13B(强化学习的部分就是这部分)
结果
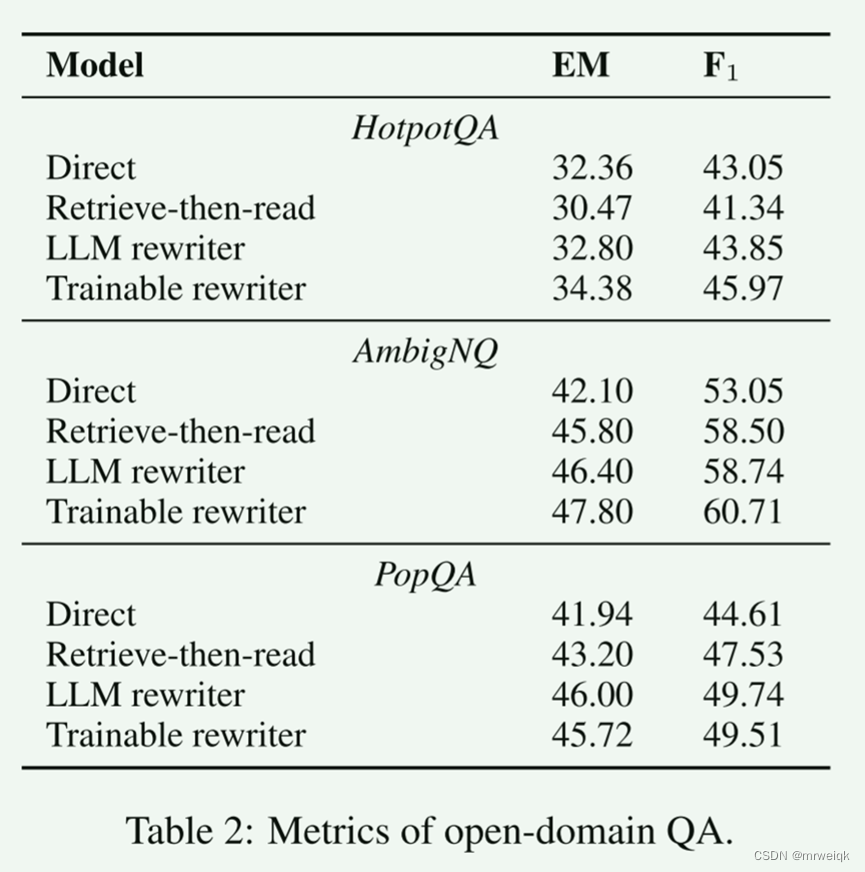
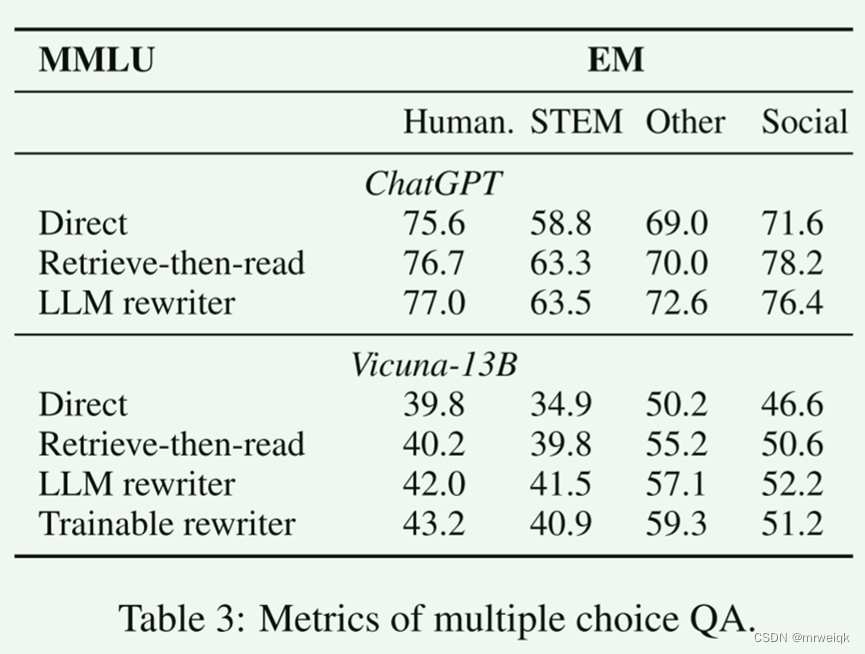
在开放域问答(open-domain QA)和多项选择问答(multiple-choice QA)任务上进行了评估。实验结果表明,查询重写一致性地提高了检索增强型LLM的性能。
相关阅读
大模型名词扫盲贴
RAG实战-QAnything
一文带你学会关键词提取算法—TextRank 和 FastTextRank实践


















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









