







题目
检索增强大语言模型的查询重写

论文地址:https://arxiv.org/abs/2305.14283
项目地址:https://github.com/xbmxb/RAG-query-rewriting
摘要
大语言模型(LLM)在检索--然后阅读(retrieve--then--read)管道中发挥着强大的黑盒阅读器的作用,在知识密集型任务中取得了显著进展。这项工作从查询重写的角度出发,为检索增强型 LLMs 引入了一个新的框架,即重写-检索-阅读(Rewrite-Retrieve-Read),而不是以前的检索-重写-阅读(Retrieve-then-read)。与之前侧重于调整检索器或阅读器的研究不同,我们的方法关注的是搜索查询本身的调整,因为输入文本与检索所需的知识之间不可避免地存在差距。我们首先促使 LLM 生成查询,然后使用网络搜索引擎检索上下文。此外,为了更好地将查询与冻结模块相匹配,我们为我们的管道提出了一个可训练的方案。我们采用一个小型语言模型作为可训练的重写器,以满足黑盒 LLM 阅读器的需要。通过强化学习,利用 LLM 阅读器的反馈对改写器进行训练。在下游任务、开放域质量保证和多选质量保证上进行了评估。实验结果表明性能得到了持续改善,这表明我们的框架被证明是有效的、可扩展的,并为检索增强型 LLM 带来了新的框架。
方法
我们提出了 “重写-检索-阅读”(Rewrite-Retrieve-Read),这是一个从查询重写角度改进检索增强 LLM 的管道。下图显示了一个概览。
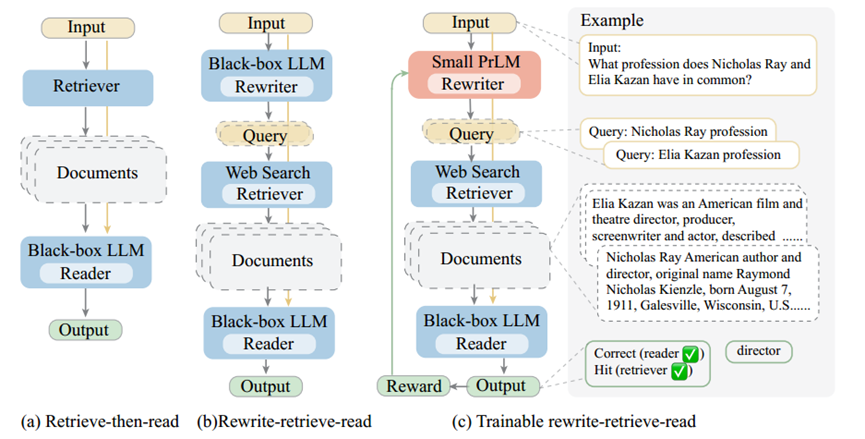
带有检索增强的任务可表示如下。给定一个知识密集型任务的数据集(如开放域 QA),D = {(x, y)i}, i = 0, 1, 2, . , N,x(如问题)是管道的输入,y 是预期输出(如正确答案)。我们的管道包括三个步骤。(i) 查询重写:根据原始输入 x 生成所需知识的查询 x˜;(ii) 检索:搜索相关上下文 doc;(iii) 阅读:理解输入和上下文 [doc, x],并预测输出 yˆ。一种直接而有效的方法是要求 LLM 重写查询,以搜索可能需要的信息。我们使用一个短促的提示来鼓励 LLM 思考,输出可以是没有、一个或多个搜索查询。
此外,完全依赖冻结的 LLM 也有一些缺点。推理错误或无效搜索会影响性能。另一方面,检索到的知识有时会误导和损害语言模型。为了更好地与冻结模块保持一致,可以添加一个可训练模型,并通过将 LLM 读者的反馈作为奖励来调整该模型。基于我们的框架,我们进一步建议利用一个可训练的小语言模型来接管改写步骤,如上图右侧所示。可训练模型由预先训练好的 T5
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











