







本文只是一个搬运工:给大家找到了一些合理的东西!!!
超感谢:http://www.cnblogs.com/imAkaka/archive/2012/03/20/2407877.html
http://www.oschina.net/question/234345_48876
2,下列关于stl的说法正确的是()
A,map的迭代器的key是const类型,无法对其进行修改
B,list是双向链表实现,插入元素的复杂度是O(1)
C,vector的大小会增大或者减少,但容量只会增大而不会减少
D,stl的排序算法一般比较传统的快速排序块是因为其选取中值的算法好
答案:a,b,c
解析:
A选项:
1、map简介
map是一类关联式容器。它的特点是增加和删除节点对迭代器的影响很小,除了那个操作节点,对其他的节点都没有什么影响。对于迭代器来说,可以修改实值,而不能修改key。
2、map的功能
自动建立Key - value的对应。key 和 value可以是任意你需要的类型。
根据key值快速查找记录,查找的复杂度基本是Log(N),如果有1000个记录,最多查找10次,1,000,000个记录,最多查找20次。
快速插入Key - Value 记录。
快速删除记录
根据Key 修改value记录。
遍历所有记录。
3、使用map
使用map得包含map类所在的头文件
#include <map> //注意,STL头文件没有扩展名.h
map对象是模板类,需要关键字和存储对象两个模板参数:
std:map<int, string> personnel;
这样就定义了一个用int作为索引,并拥有相关联的指向string的指针.
为了使用方便,可以对模板类进行一下类型定义,
typedef map<int, CString> UDT_MAP_INT_CSTRING;
UDT_MAP_INT_CSTRING enumMap;
4、在map中插入元素
改变map中的条目非常简单,因为map类已经对[]操作符进行了重载
enumMap[1] = "One";
enumMap[2] = "Two";
.....
这样非常直观,但存在一个性能的问题。插入2时,先在enumMap中查找主键为2的项,没发现,然后将一个新的对象插入enumMap,键是2,值是一个空字符串,插入完成后,将字符串赋为"Two"; 该方法会将每个值都赋为缺省值,然后再赋为显示的值,如果元素是类对象,则开销比较大。我们可以用以下方法来避免开销:
enumMap.insert(map<int, CString> :: value_type(2, "Two"))
B选项:
双(向)链表中有两条方向不同的链,即每个结点中除next域存放后继结点地址外,还增加一个指向其直接前趋的指针域prior。双向链表在查找时更方便 特别是大量数据的遍历


注意:
①双链表由头指针head惟一确定的。
②带头结点的双链表的某些运算变得方便。
③将头结点和尾结点链接起来,为双(向)循环链表。
2、双向链表的结点结构和形式描述
①结点结构(见上图a)
②形式描述
typedef struct dlistnode{
DataType da
struct dlistnode *prior,*next;
}DListNode;
typedef DListNode *DLinkList;
DLinkList head;
由于双链表的对称性,在双链表能能方便地完成各种插入、删除操作。
①双链表的前插操作
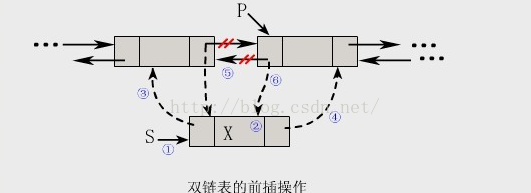
ps:注意箭头 没有直入框内 而是整体 代表指向的是整个结点包括 prior da
void DInsertBefore(DListNode *p,DataType x)
{//在带头结点的双链表中,将值为x的新结点插入*p之前,设p≠NULL
DListNode *s=malloc(sizeof(DListNode));//①(为链表结点动态分配内存)
s->da
s->prior=p->prior;//③ (将结点p的前驱的值赋给s的前驱 使s的前驱指向原来p之前的结点)
s->next=p;//④ (使s的后驱指向p 经过2.3.4步结点s各个部分赋值完毕)
p->prior->next=s;//⑤ (原来p之前的结点的后驱指向s)
p->prior=s;//⑥ (使p的前驱指向s)
}
PS: 第⑤⑥步的顺序不能改变,想想为什么呢?
②双链表上删除结点*p自身的操作
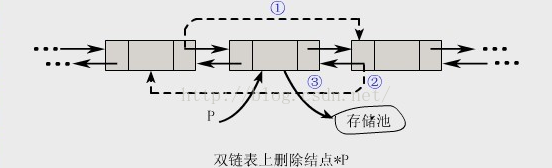
void DDeleteNode(DListNode *p)
{//在带头结点的双链表中,删除结点*p,设*p为非终端结点
p->prior->next=p->next;//① (使p的前一个结点的后驱直接指向 原来的p的后驱)
p->next->prior=p->prior;//② (使p的后一个结点的前驱 直接为原来p的前一个结点)
free(p);//③ (释放p的内存 这个很重要 特别是处理大量数据时)
}
注意:
与单链表上的插入和删除操作不同的是,在双链表中插入和删除必须同时修改两个方向上的指针。
上述两个算法的时间复杂度均为O(1)。
C:
Vector是一个可以容纳动态长度的容器。为了高效地运用Vector,应该了解Vector大小(size)和容量(capacity)的关系:Vector之中用于操作大小的函数有size()、empty()等,另一个与大小有关的函数是capacity(),它返回Vector实际能够容纳的元素数量。如果超出这个数量,Vector就有必要重新配置内部存储器。
Vector的容量之所以重要,主要有两个方面的原因:
1. 一旦内存重新配置,和Vector元素相关的所有reference、pointers、iterators都会失效;
2. 内存重新配置很耗时间。
当然,你可以通过使用reserve()函数预留相当大的容量,以避免一再重新配置内存。只要保留的容量足够大,就不用担心references等会失效。
std::vector<int> v;
v.reserve(100);
另一种避免重复配置内存的方法是:std::vector<T> v(5);不过这种方法,对基本型别效率和上一相似,如果元素型别是自定义的类型,此类型就必须提供一个default构造函数(自定义型别在初始化操作的时候很耗时, 不如reserve)。
几点注意事项:
1. Vector的容量不会缩减,即使使用clear()函数,清空Vector的所有元素,Vector的真正占用内存不会减少。不过有一个缩减Vector容量的小窍门:两个Vector交换内容后,两者的容量也会互换。现有Vector V;
std::vector<int> tmp;
V.swap(tmp); // 这样tmp就和V交换了容量
或者:
V.swap(std::vector<int>() ); // 和一个临时Vector交换
2. 慎用Vector:Vector本身就占用一定的内存,即使不向其中添加任何元素。
std::vector<int> tmp;
int a = sizeof(tmp); // 可以看到a的值为20(当然这个值根据不同的系统与环境有关,我的VS2008+win7)
甚至,在许多实作方案中,容量的增长幅度比我们料想的还大。事实上为了防止内存破碎,在许多实作方案中即使不调用reserve(),当第一插入元素时也会一口气配置整块内存(如2K)。如果有一大堆Vectors,每个Vector的实作元素却寥寥无几,那么浪费的内存会相当可观。切记!!慎用Vector
在c++中,vector是一个十分有用的容器,下面对这个容器做一下总结。
1 基本操作
(1)头文件#include<vector>.
(2)创建vector对象,vector<int> vec;
(3)尾部插入数字:vec.push_back(a);
(4)使用下标访问元素,cout<<vec[0]<<endl;记住下标是从0开始的。
(5)使用迭代器访问元素.
vector<int>::iterator it; for(it=vec.begin();it!=vec.end();it++) cout<<*it<<endl;
(6)插入元素: vec.insert(vec.begin()+i,a);在第i+1个元素前面插入a;
(7)删除元素: vec.erase(vec.begin()+2);删除第3个元素
vec.erase(vec.begin()+i,vec.end()+j);删除区间[i,j-1];区间从0开始
(8)向量大小:vec.size();
(9)清空:vec.clear();
2
vector的元素不仅仅可以使int,double,string,还可以是结构体,但是要注意:结构体要定义为全局的,否则会出错。下面是一段简短的程序代码:

#include<stdio.h> #include<algorithm> #include<vector> #include<iostream> using namespace std; typedef struct rect { int id; int length; int width; //对于向量元素是结构体的,可在结构体内部定义比较函数,下面按照id,length,width升序排序。 bool operator< (const rect &a) const { if(id!=a.id) return id<a.id; else { if(length!=a.length) return length<a.length; else return width<a.width; } } }Rect; int main() { vector<Rect> vec; Rect rect; rect.id=1; rect.length=2; rect.width=3; vec.push_back(rect); vector<Rect>::iterator it=vec.begin(); cout<<(*it).id<<' '<<(*it).length<<' '<<(*it).width<<endl; return 0; }
3 算法
(1) 使用reverse将元素翻转:需要头文件#include<algorithm>
reverse(vec.begin(),vec.end());将元素翻转(在vector中,如果一个函数中需要两个迭代器,
一般后一个都不包含.)
(2)使用sort排序:需要头文件#include<algorithm>,
sort(vec.begin(),vec.end());(默认是按升序排列,即从小到大).
可以通过重写排序比较函数按照降序比较,如下:
定义排序比较函数:
bool Comp(const int &a,const int &b)
{
return a>b;
}
调用时:sort(vec.begin(),vec.end(),Comp),这样就降序排序。
来看程序:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
bool Comp(int a,int b)//sort中的写法,返回值为bool,参数int
{
return a>b;
}
int main()
{
int i;
int a[] = {1,3,2,4,5};
vector<int> array;
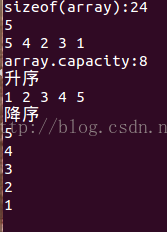
cout<<"sizeof(array):"<<sizeof(array)<<endl;//vector的容量为24,大小不一样的。
for(i = 0; i< 5; i++)
array.push_back(a[i]);
cout<<array.size()<<" ";
cout<<endl;
reverse(array.begin(),array.end()); //翻转字符//第一个和最后一个,依次相互交换
for(i = 0; i < 5; i++)
cout<<array[i]<<" ";
cout<<endl;
cout<<"array.capacity:"<<array.capacity()<<endl;//容量问题
cout<<"升序"<<endl;
sort(array.begin(), array.end()); //排序,默认是升序
for(i = 0; i< 5; i++)
cout<<array[i]<<" ";
cout<<endl;
//排序,改为降序
cout<<"降序"<<endl;
sort(array.begin(), array.end(), Comp);
for(i = 0; i< 5; i++)
cout<<array[i]<<endl;
cout<<endl;
return 0;
}
sort函数的用法
做ACM题的时候,排序是一种经常要用到的操作。如果每次都自己写个冒泡之类的O(n^2)排序,不但程序容易超时,而且浪费宝贵的比赛时间,还很有可能写错。STL里面有个sort函数,可以直接对数组排序,复杂度为n*log2(n)。使用这个函数,需要包含头文件。
bool cmp(int a,int b)//这里之所以没有用&或者*,是因为内部可能已经实现好了
{
}
struct node{
}
以下是代码片段:
bool cmp(node x,node y)
{
if(x.b!=y.b) returnx.b>y.b;
}
qsort(s[0],n,sizeof(s[0]),cmp);
int cmp(const void *a,const void *b)
{
}
一、对int类型数组排序
intnum[100];
Sample:
int cmp ( const void *a , const void *b)
{
return *(int *)a - *(int*)b;
}
qsort(num,100,sizeof(num[0]),cmp);
二、对char类型数组排序(同int类型)
charword[100];
Sample:
int cmp( const void *a , const void *b)
{
return *(char *)a - *(int*)b;
}
qsort(word,100,sizeof(word[0]),cmp);
三、对double类型数组排序(特别要注意)
doublein[100];
int cmp( const void *a , const void *b)
{
return *(double *)a > *(double *)b ? 1 :-1;
}
qsort(in,100,sizeof(in[0]),cmp);
四、对结构体一级排序
structIn
{
double data;
int other;
}s[100]
//按照data的值从小到大将结构体排序,关于结构体内的排序关键数据data的类型可以很多种,参考上面的例子写
int cmp( const void *a ,const void*b)
{
return ((In *)a)->data - ((In*)b)->data;
}
qsort(s,100,sizeof(s[0]),cmp);
五、对结构体
structIn
{
int x;
int y;
}s[100];
//按照x从小到大排序,当x相等时按照y从大到小排序
int cmp( const void *a , const void *b)
{
struct In *c = (In *)a;
struct In *d = (In *)b;
if(c->x != d->x) returnc->x -d->x;
else return d->y -c->y;
}
qsort(s,100,sizeof(s[0]),cmp);
六、对字符串进行排序
structIn
{
int data;
char str[100];
}s[100];
//按照结构体中字符串str的字典顺序排序
int cmp ( const void *a , const void *b)
{
return strcmp( ((In *)a)->str , ((In*)b)->str);
}
qsort(s,100,sizeof(s[0]),cmp);
七、计算几何中求凸包的cmp
int cmp(const void *a,const void *b)//重点cmp函数,把除了1点外的所有点,旋转角度排序
{
struct point *c=(point*)a;
struct point *d=(point*)b;
if( calc(*c,*d,p[1]) < 0) return1;
else if( !calc(*c,*d,p[1]) &&dis(c->x,c->y,p[1].x,p[1].y)<dis(d->x,d->y,p[1].x,p[1].y))//如果在一条直线上,则把远的放在前面
return 1;
else return -1;
}
D,stl的排序算法一般比较传统的快速排序块是因为其选取中值的算法好
关于D选项
STL sort源码剖析
STL的sort()算法,数据量大时采用Quick Sort,分段递归排序,一旦分段后的数据量小于某个门槛,为避免Quick Sort的递归调用带来过大的额外负荷,就改用Insertion Sort。如果递归层次过深,还会改用Heap Sort。本文先分别介绍这个三个Sort,再整合分析STL sort算法(以上三种算法的综合) --Introspective Sorting(内省式排序)。
一、Insertion Sort
 Insertion Sort
Insertion Sort
二、Quick Sort
Quick Sort
Partitioning
三、Heap Sort
Heap Sort
四、IntroSort
Intro Sort
View Code
<span style="font-size: 13px;">if (last - first > __stl_threshold){ // > 16
...
...
__introsort_loop(cut,last,value_type(first), depth_limit);
__introsort_loop(first,cut,value_type(first), depth_limit);</span>
原来,microsoft的sort并没有比sgi的sort快。只是在排序vector时,microsoft把vector的本质数据“萃取”出来了。
即,取消了vector在++时的边界检查语句,把vector::iterator当指针一般使用。所以才在对vector排序时会比我自己写的introsort算法快那么多呢。















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









