









模型性能衡量介绍
混淆矩阵
混淆矩阵(Confusion Matrix)
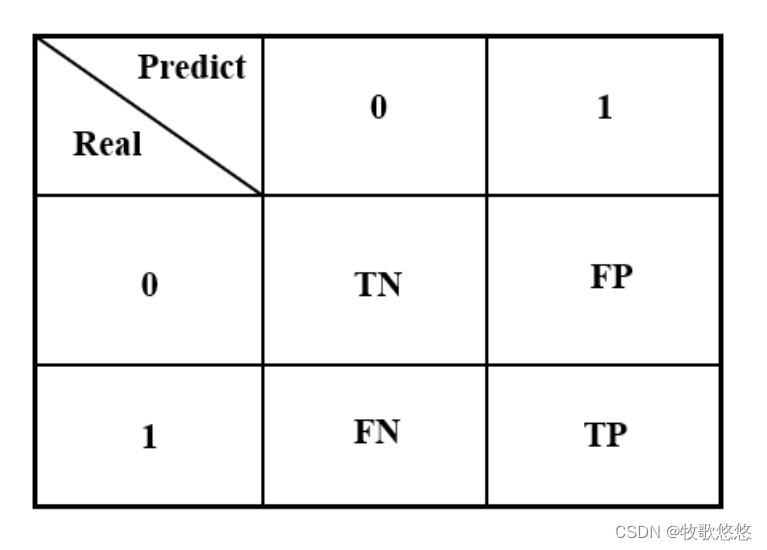
TP(真阳性):预测为阳性,且预测正确。
TN(真阴性):预测为阴性,且预测正确。
FP(伪阳性):预测为阳性,但预测错误,又称型一误差(Type I Error),或α误差。
FN(伪阴性):预测为阴性,但预测错误,又称型二误差(Type II Error),或β误差
有了TP/TN/FP/FN之后,我们就可以定义各种效能衡量指标,常见的有四种:
准确率 精确率 召回率 F1
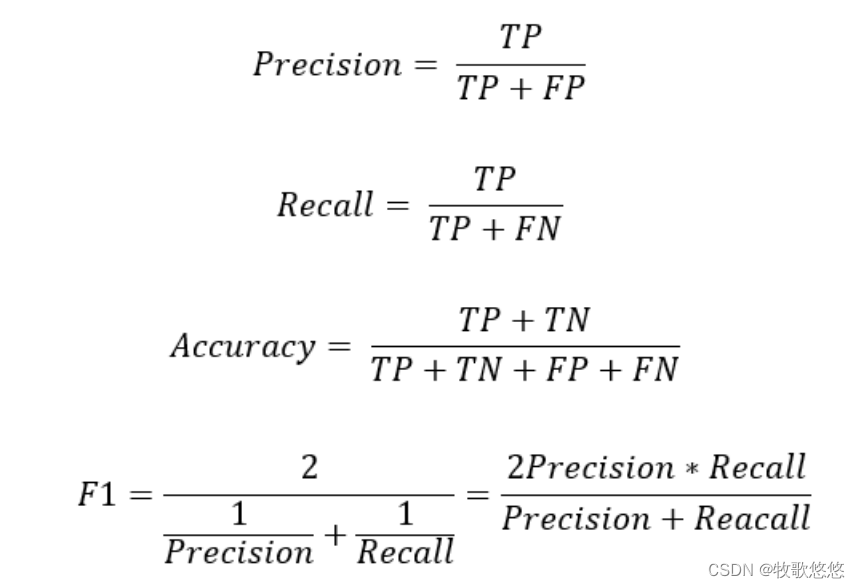
准确率
准确率(Accuracy)=(TP+TN)/(TP+FP+FN+TN),即预测正确数/总数
精确率
精确率(Precision)=TP/(TP+FP),即正确预测阳性数/总阳性数
召回率
召回率(Recall)=TP/(TP+FN),即正确预测阳性数/实际为真的总数
F1
F1=精确率与召回率的调和平均数,即1/[(1/Precision)+(1/Recall)]
针对二分类,还有一种较客观的指标称为ROC/AUC曲线,它是在各种检验门槛值下,以假阳率为X轴,真阳率为Y轴,绘制出来的曲线,称为ROC。
覆盖的面积(AUC)越大,表示模型在各种门槛值下的平均效能越好,这个指标有别于一般预测固定以0.5当作判断真假的基准。
采用Scikit-Learn示例
假设有8笔数据如下,请计算混淆矩阵(Confusion Matrix)。
实际值=[0, 0, 0, 1, 1, 1, 1, 1]
预测值=[0, 1, 0, 1, 0, 1, 0, 1]
加载相关套件
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score,classification_report,confusion_matrix, precision_score,recall_score
confusion_matrix 是 Scikit-Learn 中用于计算混淆矩阵的函数。
y_true = [0,0,0,1,1,1,1,1]
y_pred = [0,1,0,1,0,1,0,1]
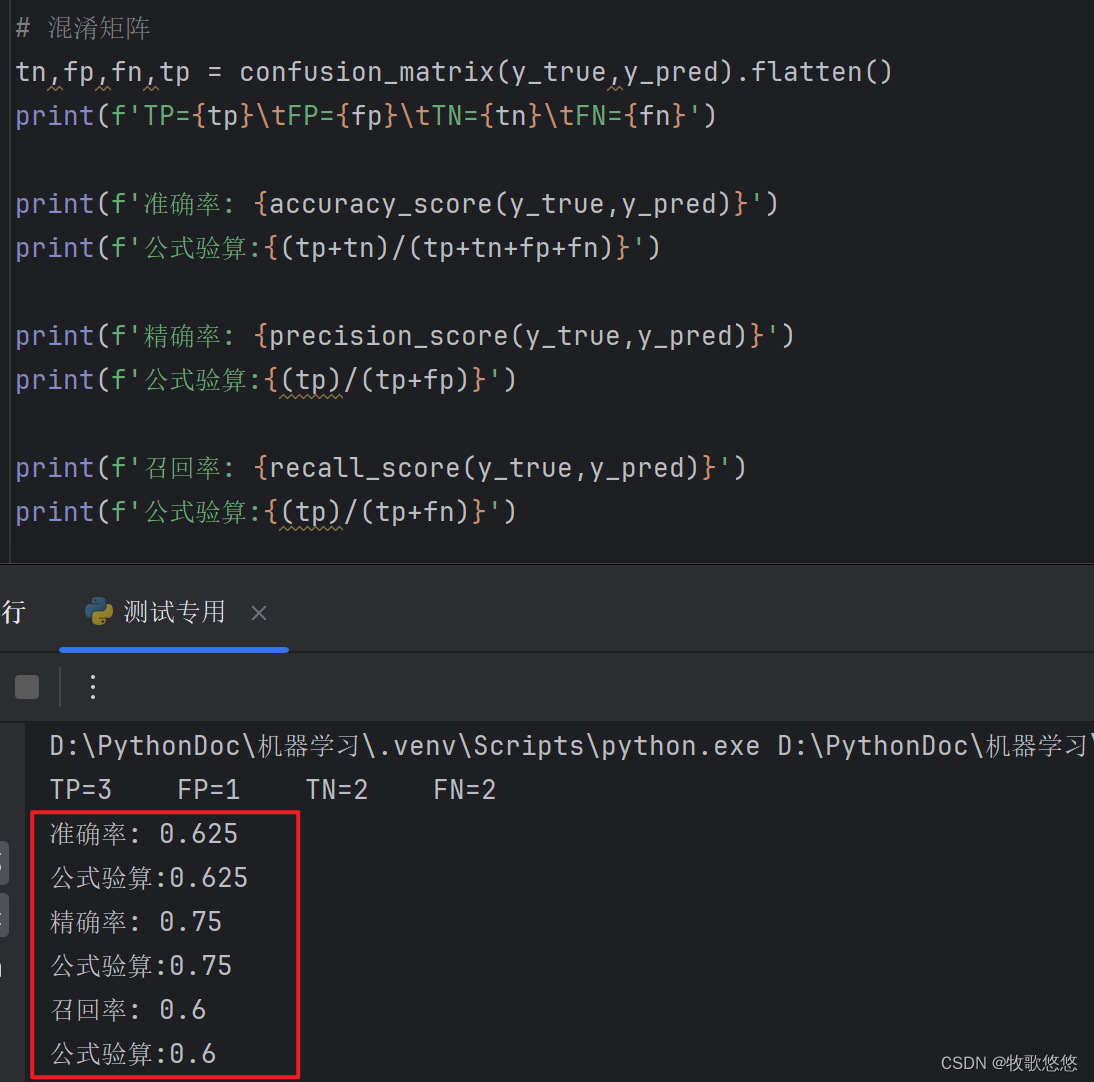
# 混淆矩阵
tn,fp,fn,tp = confusion_matrix(y_true,y_pred).ravel()
print(f'TP={tp}\tFP={fp}\tTN={tn}\tFN{fn}')
使用 ravel() 函数(或 .flatten() 方法)来将混淆矩阵展平为一维数组时,默认情况下,数组中的元素会按照行优先的顺序进行排列。这意味着数组的第一个元素将是混淆矩阵的第一行的第一个元素,第二个元素将是第一行的第二个元素,依此类推,直到第一行的最后一个元素。然后,数组将继续包含第二行的元素,以此类推。
实际值与预测值上下比较,TP为(1, 1)、FP为(0, 1)、TN为(0, 0)、FN为(1, 0)。
执行结果应该为:TP=3, FP=1, TN=2, FN=2
运行验证:

按上述数据计算效能衡量指标:
print(f'准确率: {accuracy_score(y_true,y_pred)}')
print(f'公式验算:{(tp+tn)/(tp+tn+fp+fn)}')
print(f'精确率: {precision_score(y_true,y_pred)}')
print(f'公式验算:{(tp)/(tp+fp)}')
print(f'召回率: {recall_score(y_true,y_pred)}')
print(f'公式验算:{(tp)/(tp+fn)}')















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









