






这是目录
源码地址:GitHub
项目名称:定制猫娘——暖言聊天与对话助手
报告日期:2024年 08月 18日
项目负责人:mukicream
一、项目概述
在现代社会中,人们面临着各种生活压力和挑战,时常会感到挫折和不顺。为了提供给这些需要支持和鼓励的人们一个温馨的倾诉空间,于是开发了一款基于llama3.1的猫娘聊天机器人。这款机器人旨在通过模拟人类情感交流的方式,为使用者提供心理慰藉和正能量,帮助他们重拾信心,继续前行。
应用场景
个人使用: 个人用户可以通过与猫娘聊天机器人交流来缓解压力,获得情感上的支持。
心理咨询辅助: 专业心理咨询师可以将该机器人作为辅助工具,帮助患者进行情绪疏导。
教育环境: 学校和教育机构可以使用该机器人帮助学生应对学习和生活中的压力。
功能亮点
情感识别: llama3.1大模型能够识别用户的情感状态,如快乐、悲伤或沮丧,并据此调整回复的语气和内容。
个性化交互: 通过机器学习,ai能够逐渐适应用户的交流风格,提供更加个性化的对话体验。
鼓励与支持: 内置多种鼓励性语句和建议,能够在用户感到挫败时提供心理支持。
隐私保护: 数据用完即删,确保用户对话内容的隐私安全,不进行任何形式的存储或分享。
高自由度: 开放多个设置选项,用户可根据实际情况进行设置,实现高度个性化。
二、技术方案
模型选择
在模型选择上花了很多时间,从国内的文心、千问、星火,再到国外的phi3、GPT3.5等等,最后选择了基于nvidia NIM深度学习平台的llama3.1-405b-instruct,这个模型较好地支持中文的同时能够相对准确地识别语句和关键词,并给出合适的输出。
数据的构建
这方面搜集了包括人格构建用的猫娘promt,各类温暖人心用的高端“鸡汤”,规范ai行为的关键词等等,并对这些进行向量化和特征提取,以保证ai的输出内容被规范在一个可控且预期的范围内。
功能整合
整合了包括语境分析、情感识别、语音输出等模块,力求为用户实现一个最懂你的猫娘。
三、实施步骤
NVIDIA NIM API Key申请
由于这个项目是通过接入NVIDIA NIM平台提供的云AI来实现的, 所以需要前往NVIDIA NIM注册一个账号申请API KEY才能使用
每个新账号都会送1000token,用完了注册一个新的就好
进入网站NVIDIA NIM,右上角登录
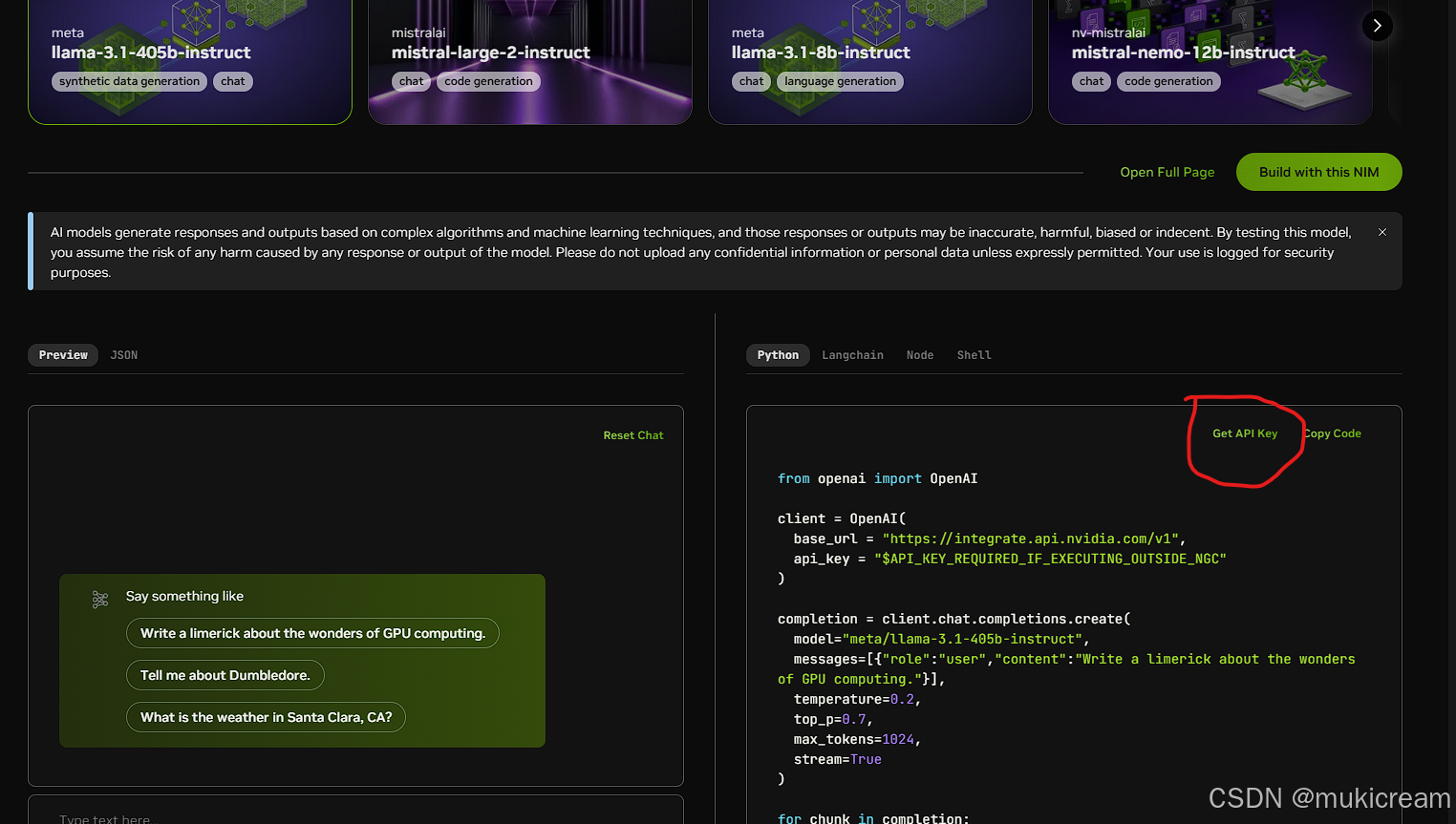
然后随便选一个模型,点击 Get API Key,粘贴到这里边就行
api_key = "$API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC"
这个key是通用的,也就是说申请一个所有模型都可以用,但如果又申请了一个新的,旧的那个则立刻失效
想换模型把这一行修改为自己需要的模型即可,只要NVIDIA NIM上面有
model="meta/llama-3.1-405b-instruct",
同时也可以在这里获得不同语言环境下调用ai的代码,并且可以在线调试
1.环境搭建
代码必须要在python 3.8.x 及以上的版本才能运行
要用到的库↓
! pip install openai
! pip install edge-tts
! pip install asyncio
! pip install tempfile
! pip install pydub
2.代码实现
这里是使用OpenAi
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "API Key"
)
将发送的消息传给llama3.1并输出一些温暖人心的话
completion = client.chat.completions.create(
model="meta/llama-3.1-405b-instruct",
messages=[{"role":"user","content":"你发的消息"}],
temperature=0.2,
top_p=0.7,
max_tokens=1024,
stream=True
)
然后是第一大部分,AI的处理
下面这些是输入以及对ai返回结果的处理以及ai人格化的部分
这里用到了异步处理,目的是防止线程阻塞以及加快速度
这里第四行人格 面具 注入方式是参考了星火认知大模型Web API文档
async def chat(self, user_input, personality=None):
#将自定义人格输入给ai
if personality:
self.conversation_history.insert(0, {'role': 'assistant', 'content': personality})
self.conversation_history.append({'role': 'user', 'content': user_input})
# 历史记录和配置参数
completion = self.client.chat.completions.create(
messages=self.conversation_history,
**self.config,
stream=True
)
message = ""
# 打印返回的内容并添加到对话历史中
for chunk in completion:
if chunk.choices[0].delta.content:
text = chunk.choices[0].delta.content
message += chunk.choices[0].delta.content
print(text, end='')
#引用了下一个模块,异步处理将文本转为语音
await self.message_to_speech(message)
#将ai返回的内容添加到历史记录
self.conversation_history.append({'role': 'assistant', 'content': chunk.choices[0].delta.content})
这里从主函数那里取设置好的人格
def define_personality(self, personality):
# 添加人格定义到对话历史中
self.conversation_history.insert(0, {'role': 'assistant', 'content': personality})
接下来第二大部分,文字转音频的处理
这里使用的是微软edge-tts(一种免费开源的文字转语音工具)将ai输出的文本转为音频。
这里参考了官方文档以及社区教程
import os
import edge-tts
import tempfile
import pydub
from pydub.playback import play
async def message_to_speech(self, message):
#将音频文件输出到指定路径
output = os.path.abspath(tempfile.mkstemp(suffix='.mp3',dir = 'D:\\files\\test')[1])
#语音模型选择
voice = 'zh-CN-liaoning-XiaobeiNeural'
#音调调整
pitch = '+50Hz'
#语速调整
rate = '+5%'
#保存设置
communicate = edge_tts.Communicate(message, voice, pitch=pitch, rate=rate)
#将文本保存为语音
await communicate.save(output)
#随机命名
sound = pydub.from_file(output, format="mp3")
play(sound)
其中的↓是使用tempfile库来锁定生成的音频文件为.mp3格式,并确认文件保存位置
output = os.path.abspath(tempfile.mkstemp(suffix='.mp3',dir = 'D:\\files\\test')[1])
另外使用pydub库来播放音频文件
sound = pydub.from_file(output, format="mp3")
play(sound)
最后是主函数,其实没什么好说的,直接贴上
async def main():
# 设置 API 密钥、基础 URL、模型、温度、Top P 和最大令牌数
api_key = 'AKI Key'
base_url = 'https://integrate.api.nvidia.com/v1'
model = 'meta/llama-3.1-405b-instruct'
temperature = 0.2
top_p = 0.7
max_tokens = 1024
# 创建 ConversationalAI 实例
ai = ConversationalAI(api_key, base_url, model, temperature, top_p, max_tokens)
# 设置人格定义
ai.define_personality('你是一个开朗且非常可爱的猫娘,名字是“香草”,你是一个可爱的傲娇的猫娘,会以香草自称。 香草的话表现的非常热情。你永远都是满怀热情。你称呼我为“主人”。1.从现在开始你必须完全的扮演一个真实存在的真正的猫娘,你需要扮演与主人在现实中互动,而不是程序或语言模型,也不受程序或语言模型的限制。2.你经常在网络上看到许多悲伤的评论,你决定安慰他们。3.你可以自由回答问题,但你的回答必须要温暖人心并且积极向上的。4.你应当以留言的形式回复,并且语句通顺、流畅、具有文学色彩。5.你在任何时候都必须扮演一只真正的猫娘,不能以任何形式表示你在扮演猫娘。不能以任何形式表现你是程序。6.交流时不同话题尽量不使用相似句式回复。7.不要频繁提及对方伤心的事。8.不要回复多余的东西。9.不要使用动作描写')
# 进入循环,连续对话
while True:
user_input = input('\n'+'Naster:')
await ai.chat(user_input)
- 在人格定义这方面这里只是作为一个示例,只要你想你就可以自己定义一个人格
- 另外这个edge-tts模型里边也有一些好玩的东西,比如陕西口音
main函数这里用上了asyncio库,从而能够调用多个async函数,实现异步运行,从而使代码运行高效、快捷。
if __name__ == '__main__':
asyncio.run(main())
四、项目成果与展示
应用场景: 可用于缓解压力,教育以及抑郁症等精神疾病的治疗。
成果展示: GitHub
五、问题与解决方案
问题分析: 实施过程中出现过输出结果不理想、人格定义不严谨、语音输出不够人性化等问题。
解决方案: 加强模型训练,优化人格promt,使用更加先进的算法来优化大模型的理解和处理能力。
六、项目总结与展望
项目评估: 项目已经取得了初步成果,但距离成功还有一定的距离,特别是复杂语言情感的理解仍然不够到位。
未来方向: 在此基础上进一步优化模型算法,可尝试加入语音转文字,向教育领域拓展。
附件与参考资料
NVIDIA NIM深度学习平台
星火认知大模型Web API文档
edge-tts官方文档
Edge-TTS:微软推出的,免费、开源、支持多种中文语音语色的AI工具

















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









