







深度学习经典网络解析目标检测篇(二):Fast R-CNN

阅读此博客建议先了解R-CNN,R-CNN详解见博客:
深度学习经典网络解析目标检测篇(一):R-CNN
Fast R-CNN论文翻译详情见我的博客:
深度学习论文阅读目标检测篇(二):Fast R-CNN《Fast R-CNN》
更多Ai资讯:公主号AiCharm

1.背景介绍
2014年R-CNN横空出世,首次将卷积神经网络带入目标检测领域。受SPPnet启发,rbg在15年发表Fast R-CNN,它的构思精巧,流程更为紧凑,大幅提高目标检测速度。
在同样的最大规模网络上,Fast R-CNN和R-CNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间。
2.R-CNN 与 Fast R-CNN
R-CNN具体详解见博客:深度学习经典网络解析目标检测篇(一):R-CNN
2.1 R-CNN存在的问题:
简单来说,R-CNN使用以下四步实现目标检测:
- 在图像中确定约1000-2000个候选框
- 对于每个候选框内图像块,使用深度网络提取特征
- 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
- 对于属于某一特征的候选框,用回归器进一步调整其位置
但是R-CNN会存在以下问题:
- R-CNN网络训练、测试速度都很慢:R-CNN网络中,一张图经由selective search算法提取约2k个建议框【这2k个建议框大量重叠】,而所有建议框变形后都要输入AlexNet CNN网络提取特征【即约2k次特征提取】,会出现上述重叠区域多次重复提取特征,提取特征操作冗余;
- R-CNN网络训练、测试繁琐:R-CNN网络训练过程分为ILSVRC 2012样本下有监督预训练、PASCAL VOC 2007该特定样本下的微调、20类即20个SVM分类器训练、20类即20个Bounding-box回归器训练,该训练流程繁琐复杂;同理测试过程也包括提取建议框、提取CNN特征、SVM分类和Bounding-box回归等步骤,过于繁琐;
- R-CNN网络训练需要大量存储空间:20类即20个SVM分类器和20类即20个Bounding-box回归器在训练过程中需要大量特征作为训练样本,这部分从CNN提取的特征会占用大量存储空间;
- R-CNN网络需要对建议框进行形变操作后【形变为227×227 size】再输入CNN网络提取特征,其实像AlexNet CNN等网络在提取特征过程中对图像的大小并无要求,只是在提取完特征进行全连接操作的时候才需要固定特征尺寸【R-CNN中将输入图像形变为227×227可正好满足AlexNet CNN网络最后的特征尺寸要求】,然后才使用SVM分类器分类,R-CNN需要进行形变操作的问题在Fast R-CNN已经不存在。
2.2 Fast R-CNN改进
问题一:测试时速度慢 训练时速度慢
-
原因:R-CNN一张图像内候选框之间大量重叠,提取特征操作冗余。
-
解决:Fast R-CNN将整张图片归一化送入神经网络,在最后一层再加入候选框信息(这些候选框还是经过 S e l e c t i v e S e a r c h Selective Search SelectiveSearch提取,再经过一个 R O I ROI ROI层统一映射到最后一层特征图上,而RCNN是通过拉伸来归一化尺寸),这样提取特征的前面层就不再需要重复计算。
问题三:训练所需空间大
-
原因:RCNN中独立的分类器和回归器需要大量特征作为训练样本。
-
解决:本文把类别判断和位置精调统一用深度网络实现,不再需要额外存储。损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练。

3. Fast R-CNN
3.1 检测步骤
RCNN算法流程可分为4个步骤
- 一张图像生成1K~2K个候选区域(使用Selective Search方法)
- 对每个候选区域,使用深度网络提取特征
- 特征送入每一类的SVM 分类器,判别是否属于该类
- 使用回归器精细修正候选框位置


Fast R-CNN算法流程可分为3个步骤
- 用selective search在一张图片中生成约2000个object proposal,即RoI。
- 把图像输入到卷积网络中,并输入候选框,在最后一个卷积层上对每个ROI求映射关系,并用一个RoI pooling layer来统一到相同的大小,得到 (fc)feature vector,即一个固定维度的特征表示。
- 继续经过两个全连接层(FC)得到特征向量。特征向量经由各自的FC层,得到两个输出向量:第一个是分类,使用softmax,第二个是每一类的bounding box回归。

3.2 创新点
- 卷积不再是对每个region proposal进行,而是直接对整张图像,这样减少了很多重复计算。原来RCNN是对每个region proposal分别做卷积,因为一张图像中有2000左右的region proposal,肯定相互之间的重叠率很高,因此产生重复计算。
- 用ROI pooling进行特征的尺寸变换,因为全连接层的输入要求尺寸大小一样,因此不能直接把region proposal作为输入。
- 将regressor放进网络一起训练,每个类别对应一个regressor,同时用softmax代替原来的SVM分类器。
在实际训练中,每个mini-batch包含2张图像和128个region proposal(或者叫ROI),也就是每张图像有64个ROI。然后从这些ROI中挑选约25%的ROI,这些ROI和ground truth的IOU值都大于0.5。另外只采用随机水平翻转的方式增加数据集。测试的时候则每张图像大约2000个ROI。
损失函数的定义是将分类的loss和回归的loss整合在一起,其中分类采用log loss,即对真实分类(下图中的pu)的概率取负log,而回归的loss和R-CNN基本一样。分类层输出K+1维,表示K个类和1个背景类。
Fast R-CNN 的改进可以用下面的图概括。其中,图1是原 RCNN 的做法,图3则是 Fast RCNN 的做法。



3.3 网络结构
Fast-RCNN依旧基于VGG16,首先输入的图片resize为224*224后放入CNN网络提取特征(5个卷积层和2个降采样层)
VGG16网络结构:

作者在第五个卷积层提取特征,并加上Selective Search产生的2K个ROI,通过ROI pooling层将这些ROI调整为固定维度,再通过两个output都是4096的全连接层后,将输出分为分类和回归两块,在分类模块中,输出通过一个output为21的全连接层(21表示20个类和一个背景)和一个softmax层,在回归模块中,输出通过一个output为48的全连接层(48表示各个类别region proposal的四个坐标)和SmoothL1Loss层。


相比R-CNN最大的区别,在于RoI池化层和全连接层中目标分类与检测框回归微调的统一。
3.4 特征提取网络
图像归一化为224×224直接送入网络。前五阶段是基础的conv+relu+pooling形式,在第五阶段结尾,输入P个候选区域(图像序号×1+几何位置×4,序号用于训练)。文中给出了大中小三种网络,此处示出最大的一种。三种网络基本结构相似,仅conv+relu层数有差别,或者增删了norm层。

3.5 特征提取 ROI Pooling Layer
在Fast R-CNN中,作者提出了一个叫做ROI Pooling的网络层,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量。ROI Pooling层**将每个候选区域均匀分成M×N块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。**这样虽然输入的图片尺寸不同,得到的feature map(特征图)尺寸也不同,但是可以加入这个神奇的ROI Pooling层,对每个region都提取一个固定维度的特征表示,就可再通过正常的softmax进行类型识别。
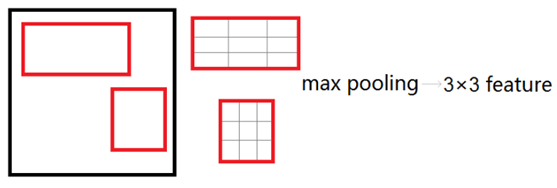
ROI Pooling Layer实际上是SPP Layer的简化版,SPP Layer对每个候选区域使用了不同大小的金字塔映射,即SPP Layer采用多个尺度的池化层进行池化操作;而RoI Pooling Layer只需将不同尺度的特征图下采样到一个固定的尺度(例如77)。例如对于VGG16网络conv5_3有512个特征图,虽然输入图像的尺寸是任意的,但是通过RoI Pooling Layer后,均会产生一个77512维度的特征向量作为全连接层的输入,即RoI Pooling Layer只采用单一尺度进行池化。如下图所示:

对于每一个虚线窗口内的卷积特征,SPP层采用3种尺度池化层进行下采样,将每个虚线框分别分成11bin, 22bin, 44bin,对每个bin内的特征分别采用max pooling,这样一共21个bin共得到21维的特征向量,然后将该特征向量送入全连接层中。而对于RoI pooling层则采用一种尺度的池化层进行下采样,将每个RoI区域的卷积特征分成4*4个bin,然后对每个bin内采用max pooling,这样就得到一共16维的特征向量。SPP层和RoI pooling层使得网络对输入图像的尺寸不再有限制,同时RoI pooling解决了SPP无法进行权值更新的问题。
RoI pooling层有两个主要作用:
- 将图像中的RoI区域定位到卷积特征中的对应位置.
- 将这个对应后的卷积特征区域通过池化操作固定到特定长度的特征,然后将该特征送入全连接层。

3.6 分类回归 Multi-task loss
在R-CNN中,先生成候选框,然后再通过CNN提取特征,之后再用SVM分类,最后再做回归得到具体位置(bbox regression)。而在Fast R-CNN中,作者巧妙的把最后的bbox regression也放进了神经网络内部,与区域分类合并成为了一个multi-task模型,如下图所示:

loss_cls层评估分类代价。由真实分类u对应的概率决定:
L
c
l
s
=
−
log
p
u
L_{c l s}=-\log p_{u}
Lcls=−logpu

loss_bbox评估检测框定位代价,比较真实分类对应的预测参数
t
u
t^{u}
tu 和真实平移缩放参数为
v
\mathrm{v}
v 的差别:
L
l
o
c
=
∑
i
=
1
4
S
m
o
o
t
h
L
1
(
t
i
u
−
v
i
)
L_{l o c}=\sum_{i=1}^{4} Smooth_{L1}\left(t_{i}^{u}-v_{i}\right)
Lloc=i=1∑4SmoothL1(tiu−vi)
S
m
o
o
t
h
L
1
Smooth_{L1}
SmoothL1误差(
S
m
o
o
t
h
L
1
Smooth_{L1}
SmoothL1误差),对outlier不敏感:
S
m
o
o
t
h
L
1
=
{
0.5
x
2
∣
x
∣
<
1
∣
x
∣
−
0.5
otherwise
Smooth_{L1}= \begin{cases}0.5 x^{2} & |x|<1 \\ |x|-0.5 & \text { otherwise }\end{cases}
SmoothL1={0.5x2∣x∣−0.5∣x∣<1 otherwise

总代价为这两者加权和,如果分类为背景则不考虑定位代价:
L
=
{
L
c
l
s
+
λ
L
l
o
c
u
为前景
L
c
l
s
u
为背景
L= \begin{cases}L_{c l s}+\lambda L_{l o c} & u \text { 为前景 } \\ L_{c l s} & u \text { 为背景 }\end{cases}
L={Lcls+λLlocLclsu 为前景 u 为背景

损失函数的定义是将分类的loss和回归的loss整合在一起,其中分类采用log loss,即对真实分类的概率取负log,而回归的loss和R-CNN基本一样。分类层输出K+1维,表示K个类和1个背景类。最后将分类的loss和回归的loss整合在一起,作者将
λ
λ
λ设为1
3.7 采用SVD分解改进全连接层
如果是一个普通的分类网络,那么全连接层的计算应该远不及卷积层的计算,但是针对object detection,Fast RCNN在ROI pooling后每个region proposal都要经过几个全连接层,这使得全连接层的计算占网络的计算将近一半,如下图,所以作者采用SVD来简化全连接层的计算。
分类和位置调整都是通过全连接层实现的,设前一级数据为
x
x
x 后一级为
y
y
y, 全连接层参数为
W
W
W ,尺寸为
u
∗
v
0
u^{*} v_{0}
u∗v0 一次前向传播即为:
y
=
W
∗
x
y=W * x
y=W∗x
计算复杂度为
u
∗
v
u * v
u∗v
将
W
W
W进行SVD分解,并用前t个特征值近似:
W
=
U
Σ
V
T
≈
U
(
:
,
1
:
t
)
⋅
Σ
(
1
:
t
,
1
:
t
)
⋅
V
(
:
,
1
:
t
)
T
W=U \Sigma V T \approx U(:, 1: t) \cdot \Sigma(1: t, 1: t) \cdot V(:, 1: t) T
W=UΣVT≈U(:,1:t)⋅Σ(1:t,1:t)⋅V(:,1:t)T
原来的前向传播分解成两步:
y
=
W
x
=
U
⋅
(
Σ
⋅
V
T
)
⋅
x
=
U
⋅
z
y=W x=U \cdot(\Sigma \cdot V T) \cdot x=U \cdot z
y=Wx=U⋅(Σ⋅VT)⋅x=U⋅z
计算复杂度变为
u
×
t
+
v
×
t
=
(
u
+
v
)
×
t
u \times t+v \times t= (u+v)\times t
u×t+v×t=(u+v)×t
(
u
+
v
)
×
t
(u+v)\times t
(u+v)×t与原来
u
∗
v
u * v
u∗v相比大大减小
在实现时,相当于把一个全连接层拆分成两个,中间以一个低维数据相连。

3.8 训练
参数初始化
网络除去末尾部分如下图,在ImageNet上训练1000类分类器,结果参数作为相应层的初始化参数。其余参数随机初始化。

在调优训练时,每一个mini-batch中首先加入N张完整图片,而后加入从N张图片中选取的R个候选框。这R个候选框可以复用N张图片前5个阶段的网络特征。
实际选择N=2,R=128。N张完整图片以50%概率水平翻转。R个候选框的构成方式如下:
| 类别 | 比例 | 类别 |
|---|---|---|
| 背景 | 75% | 与某个真值重叠在[0.1,0.5]的候选框 |
| 前景 | 25% | 与某个真值重叠在[0.5,1]的候选框 |
每次更新参数的训练步骤如下
- 2张图像直接经过前面的卷积层获得特征图
- 根据ground truth标注所有建议框的类别。具体步骤为,对每一个类别的ground truth,与它的IoU大于0.5的建议框标记为groud truth的类别,对于与ground truth的iou介于0.1到0.5之间的建议框,标注为背景类别
- 每张图片随机选取64个建议框(要控制背景类的建议框占75%),提取出特征框
- 特征框继续向下计算,进入两个并行层计算损失函数
- 反向传播更新参数

3.9 测试
前面和训练差不多,测试中对每个类型采用NMS算法,得到最终结果。


4. Smooth_L1损失函数(拓展)
Smooth_L1为了从两个方面限制梯度:
- 当预测框与 ground truth 差别过大时,梯度值不至于过大;
- 当预测框与 ground truth 差别很小时,梯度值足够小。
考察如下几种损失函数,其中
x
x
x 为预测框与 groud truth 之间 elementwise 的差异:
L
2
(
x
)
=
x
2
L
1
(
x
)
=
∣
x
∣
smooth
L
1
(
x
)
=
{
0.5
x
2
if
∣
x
∣
<
1
∣
x
∣
−
0.5
otherwise
\begin{gathered} L_{2}(x)=x^{2} \\ L_{1}(x)=|x| \\ \operatorname{smooth}_{L_{1}}(x)= \begin{cases}0.5 x^{2} & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise }\end{cases} \end{gathered}
L2(x)=x2L1(x)=∣x∣smoothL1(x)={0.5x2∣x∣−0.5 if ∣x∣<1 otherwise
损失函数对
x
x
x 的导数分别为:
d
L
2
(
x
)
d
x
=
2
x
d
L
1
(
x
)
d
x
=
{
1
if
x
≥
0
−
1
otherwise
d
smooth
L
1
d
x
=
{
x
if
∣
x
∣
<
1
±
1
otherwise
\begin{gathered} \frac{\mathrm{d} L_{2}(x)}{\mathrm{d} x}=2 x \\ \frac{\mathrm{d} L_{1}(x)}{\mathrm{d} x}= \begin{cases}1 & \text { if } x \geq 0 \\ -1 & \text { otherwise }\end{cases} \\ \frac{\mathrm{d} \mathrm{} \operatorname{smooth}_{L_{1}}}{\mathrm{~d} x}= \begin{cases}x & \text { if }|x|<1 \\ \pm 1 & \text { otherwise }\end{cases} \end{gathered}
dxdL2(x)=2xdxdL1(x)={1−1 if x≥0 otherwise dxdsmoothL1={x±1 if ∣x∣<1 otherwise
观察 (4),当
x
x
x 增大时
L
2
L_{2}
L2 损失对
x
x
x 的导数也增大。这就导致训练初期,预测值与 groud truth 差异过于大时,损失函数对预测值的梯度十分大,训练不稳定。
根据方程 (5),
L
1
L_{1}
L1 对
x
x
x 的导数为常数。这就导致训练后期,预测值与 ground truth 差异很小 时,
L
1
L_{1}
L1 损失对预测值的导数的绝对值
a
a
a 仍然为 1 ,而 learning rate 如果不变,损失函数将在稳 定值附近波动,难以继续收玫以达到更高精度。
最后观察 (6),
smooth
L
1
\operatorname{smooth}_{L_{1}}
smoothL1 在
x
x
x 较小时,对
x
x
x 的梯度也会变小,而在
x
x
x 很大时,对
x
x
x 的梯 度的绝对值达到上限 1 , 也不会太大以至于破坏网络参数。
smooth
L
1
\operatorname{smooth}_{L_{1}}
smoothL1 完美地避开了
L
1
L_{1}
L1 和
L
2
L_{2}
L2 损失的缺陷。其函数图像如下:

由图中可以看出,它在远离坐标原点处,图像和 L 1 L_1 L1 loss 很接近,而在坐标原点附近,转折十分平滑,不像 L 1 L_1 L1 loss 有个尖角,因此叫做 smooth L 1 L_1 L1loss。
5. 总结
Fast R-CNN在很大程度上实现了end-to-end(除了生成2K个候选区域的Selective Search算法),并通过只进行一次卷积运算、使用SVD加速全连接层等大大提高了运算效率,但同时Selective Search算法依旧使得Fast R-CNN的运行时间很长,这也是后续Faster RCNN的改进方向之一。
更多Ai资讯:公主号AiCharm

















 1592
1592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











