







重点
- Armijo condition的直观理解
背景: In gradient descent algorithms, step size may be too large or too small, as shown in the figures below.
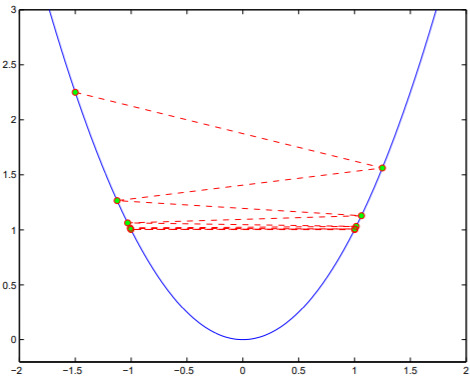
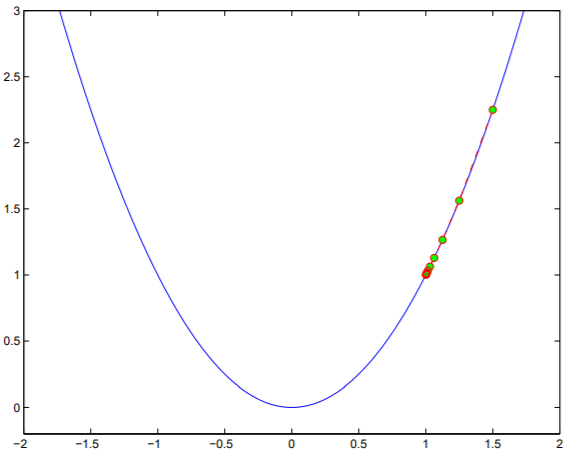
Backtracking line search
- Initialization: alpha (=1), tau (decay rate)
- while f(x^t + alpha p^t) ">" f(x^t)
alpha = tau*alpha
end
- Update x^{t+1} = x^t
- α = α ∗ τ \alpha = \alpha * \tau α=α∗τ的作用是防止step length过小
- f ( x t + α p t ) “ > ” f ( x t ) : prevent steps that are too long relative to the decrease in f ;通过Armijo condition实现 \textcolor{blue}{f(x^t + \alpha p^t) “>” f(x^t): \text{ prevent steps that are too long relative to the decrease in } f \text{;通过Armijo condition实现}} f(xt+αpt)“>”f(xt): prevent steps that are too long relative to the decrease in f;通过Armijo condition实现
Wolfe conditions
Armijo condition
f
(
x
t
+
α
t
p
t
)
≤
f
(
x
t
)
+
α
t
c
1
⋅
[
g
t
]
T
p
k
,
f(x^t + \alpha^t p^t) \leq f(x^t) + \alpha^t c_1 \cdot [g^t]^T p^k,
f(xt+αtpt)≤f(xt)+αtc1⋅[gt]Tpk,
where
g
t
g^t
gt denotes the first derivative of
f
f
f;
p
p
p denotes the direction,
g
T
p
<
0
g^T p <0
gTp<0 (remark: gradient descent
−
g
⇔
p
-g \Leftrightarrow p
−g⇔p).
In practice,
c
1
c_1
c1 is chosen quite small, say
c
1
=
1
0
−
4
c_1=10^{-4}
c1=10−4.
In the case that
p
=
g
p=g
p=g, the Armijo condition in the 2nd step of pseudo-code step can be simplified as follows:
f
(
x
−
α
∇
(
f
)
)
>
f
(
x
)
−
c
1
α
∥
∇
(
f
)
∥
2
2
.
f(x - \alpha \nabla(f)) > f(x) - c_1\alpha \|\nabla(f) \|_2^2 .
f(x−α∇(f))>f(x)−c1α∥∇(f)∥22.
*B&V book,
c
1
∈
[
0.01
,
0.03
]
,
τ
∈
[
0.1
,
0.8
]
c_1 \in [0.01,0.03], \tau \in [0.1,0.8]
c1∈[0.01,0.03],τ∈[0.1,0.8]
直 观 理 解 \textcolor{blue}{直观理解} 直观理解
- require the reduction in f f f to be at least a fixed fraction β \beta β of the reduction promised by the first-order Taylor approximation of f f f at x t x^t xt.
- aka significant decrease condition: require α \alpha α to decrease the objective function by a significant amount.
Curvature condition
The curvature condition rules out small steps.
∇
f
(
x
t
+
α
t
p
t
)
T
p
t
≥
c
2
∇
f
(
x
t
)
T
p
t
,
\nabla f(x^t + \alpha^t p^t)^T p^t \geq c_2 \nabla f(x^t)^T p^t,
∇f(xt+αtpt)Tpt≥c2∇f(xt)Tpt,
where
c
2
∈
(
c
1
,
1
)
c_2 \in (c_1,1)
c2∈(c1,1).
The condition requires that the new slope is at least
c
2
times the original gradient.
\textcolor{gray}{\text{The condition requires that the new slope is at least } c_2 \text{ times the original gradient.}}
The condition requires that the new slope is at least c2 times the original gradient.
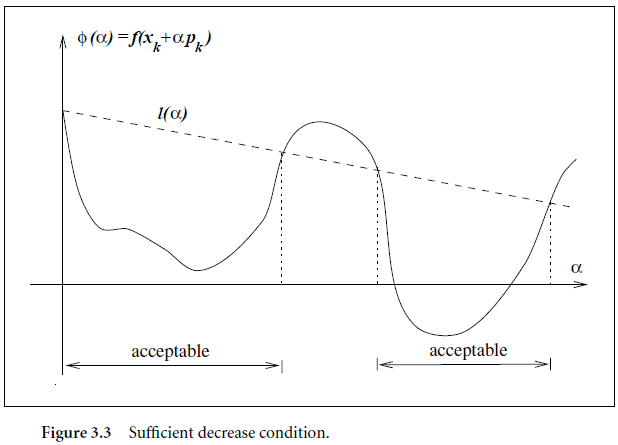
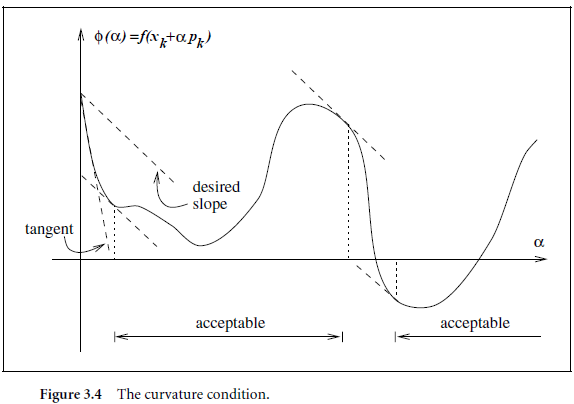
图片来源
- step sizes: https://people.maths.ox.ac.uk/hauser/hauser_lecture2.pdf
- Figs 3.3, 3.4:
Numerical Optimization
参考文献:
- https://people.maths.ox.ac.uk/hauser/hauser_lecture2.pdf
- https://optimization.mccormick.northwestern.edu/index.php/Line_search_methods
- Numerical Optimization















 2401
2401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









