






一,介绍
卷积网络的主要优势是提供end-to-end解决方案;劣势就是对于标签数据集很贪婪。所以在大的数据集上面取得了很大的突破,但是在小的数据集上面突破不是很大。
ImageNet数据集上的分类图片,物体大致分布在图片中心,但是感兴趣的物体常常在尺寸和位置(以滑窗的方式)上有变化;解决这个问题的第一个想法想法就是在不同位置和不同缩放比例上应用卷积网络。但是种滑窗的可视窗口可能只包涵物体的一个部分,而不是整个物体;对于分类任务是可以接受的,但是对于定位和检测有些不适合。第二个想法就是训练一个卷积网络不仅产生类别分布,还产生一个物体位置的预测和bounding box的尺寸;第三个想法就是积累在每个位置和尺寸对应类别的置信度。
在多缩放尺度下以滑窗的方式利用卷积网络用了侦测和定位很早就有人提出了,一些学者直接训练卷积网络进行预测物体的相对于滑窗的位置或者物体的姿势。还有一些学者通过基于卷积网络的图像分割来定位物体。
二,视觉任务
分类:是啥 预测top-5分类
定位:在哪是啥 预测top-5分类+每个类别的bounding box(50%以上的覆盖率认为是正确的)
检测:在哪都有啥
定位是介于分类和检测的中间任务,分类和定位使用相同的数据集,检测的数据集有额外的数据集(物体比较小)。
三,分类
3.1 参数设置
提取221*221的图片,batch大小,权值初始值,权值惩罚项,初始学习率和Alex-net一样。不同地方时就动量项权重从0.9变为0.6;在30, 50, 60, 70, 80次迭代后,学习率每次缩减0.5倍。
3.2模型设计
作者提出了两种模型,fast模型和accurate模型。
Fast模型:
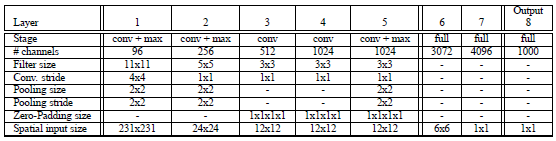
Input(231,231,3)→96F(11,11,3,s=4)→max-p(2,2,s=2)→256F(5,5,96,1) →max-p(2,2,2) →512F(3,3,512,1) →1024F(3,3,1024,1) →1024F(3,3,1024) →max-p(2,2,2) →3072fc→4096fc→1000softmax
Fast模型改进:
1,不使用LRN;
2,不使用over-pooling使用普通pooling;
3,第3,4,5卷基层特征数变大,从Alex-net的384→384→256;变为512→1024→1024.
4,fc-6层神经元个数减少,从4096变为3072
5,卷积的方式从valid卷积变为维度不变的卷积方式,所以输入变为231*231
Accurate模型改进:
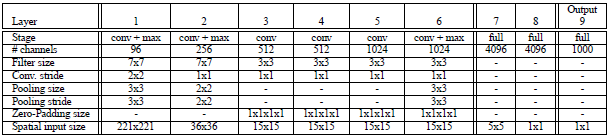
Input(231,231,3)→96F(7,7,3,s=2)→max-p(3,3,3)→256F(7,7,96,1)→max-p(2,2,2) →512F(3,3,512,1) →512F(3,3,512,1) →1024F(3,3,1024,1) →1024F(3,3,1024,1) →max-p(3,3,3) →4096fc→4096fc→1000softmax
1,不使用LRN;
2,不使用over-pooling使用普通pooling,更大的pooling间隔S=2或3
3第一个卷基层的间隔从4变为2(accurate 模型),卷积大小从11*11变为7*7;第二个卷基层filter从5*5升为7*7
4增加了一个第三层,是的卷积层变为6层;从Alex-net的384→384→256;变为512→512→1024→1024.
感觉这个调整和上一篇ZF-net的结构调整很像,毕竟他们都是纽约大学里面一个团队的;fast模型使用更小的pooling局域2*2,,增加3,4,5层特征情况下,减少fc-6层的神经元,保持网络复杂度较小的变化;accurate模型感觉有些暴力,缩小间隔,增加网络深度,增加特征数;通过提升计算复杂度,来提取更多的信息,从而提升效果,感觉这个多少有些任性。
两个模型参数和连接数目对比:
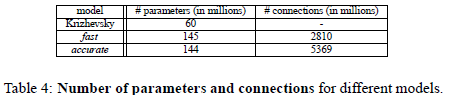
Fast模型比accurate模型的参数还多,这个让我比较意外;感觉fast模型和Alex-net参数应该差不多,而应该和accurate差很多。但是计算结果让我有些意外:
每层参数个数:=特征数M*每个filter大小(filter_x*filter_y*连接特征数(由于本文是全连接,所以连接特征数就等于前一层特征个数))没有把bias计算在内。
|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Fast | 3.5万 | 61 | 118 | 0 | 472 | 944 | 11324 | 1678 | 409 |
| Accurate | 1.4万 | 120 | 118 | 236 | 472 | 944 | 10485 | 1678 | 409 |
通过计算发现,连接方式,特征数目,filter尺寸是影响参数个数的因素;
1连接方式是关键因素,例如主要参数都分布在全连接层;
2最后一个卷基层特征图的大小也是影响参数个数的关键,例如第七层fast模型的特征图为6*6; accurate模型的输入特征为5*5,所以尽管accurate比fast多了1024个全连接神经元,但是由于输入特征图相对较小,多所以本层两个模型的参数差的不多。所以最后一个卷基层特征图大小对参数影响较大。
3.2 多尺寸分类测试
Alex-net中,使用multi-view的方式来投票分类测试;然而这种方式可能忽略图像的一些区域,在重叠的view区域会有重复计算;而且还只在单一的图片缩放比例上测试图片,这个单一比例可能不是反馈最优的置信区域。
作者在多个缩放比例,不同位置上,对整个图片密集地进行卷积计算;这种滑窗的方式对于一些模型可能由于计算复杂而被禁止,但是在卷积网络上进行滑窗计算不仅保留了滑窗的鲁棒性,而且还很高效。每一个卷积网络的都输出一个m*n-C维的空间向量,C是分类的类别数;不同的缩放比例对应不同的m和n。
整个网络的子采样比例=2*3*2*3=36,即当应用网络计算时,输入图像的每个维度上,每36个像素才能产生一个输出;在图像上密集地应用卷积网络,对比10-views的测试分类方法,此时粗糙的输出分布会降低准确率(没想明白,怎么就粗糙了);因为物体和view可能没有很好的匹配分布(物体和view越好的匹配,网络输出的置信度越高)。为了绕开这个问题,我们采取在最后一个max-pooling层换成offset max-pooling,平移pooling;这种平移max-pooling是一种数据增益技术。
offset max-pooling:
平移量△:x,y连个维度平移量都为0,1,2(由于pooling区域为3*3)
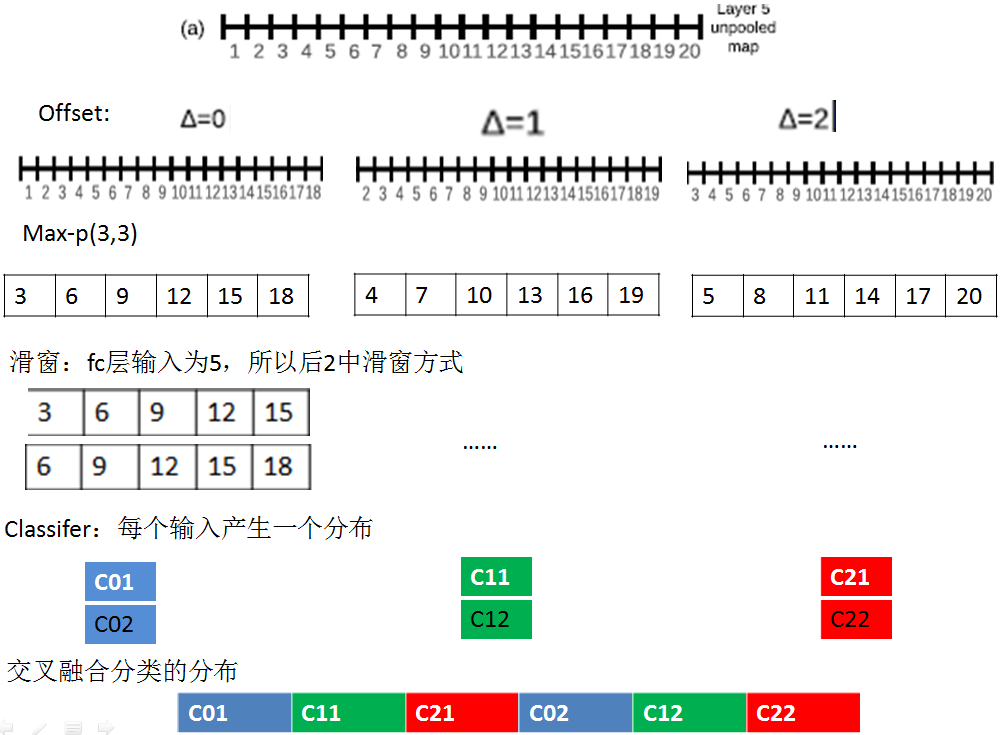
Step1计算特征图:计算layer-5未pooling的特征图unpooling-FM
Step2平移特征图:按照平移量产生不同的平移特征图;本文是x,y连个维度,每个维度平移量为0,1,2.所以每个unpooling-FM,产生9种平移特征图offset-pooling FM(一维的是3种)。
Step3 max-pooling:在每个平移offset-pooling FM图上,进行普通的max-pooling操作产生pooled FM。
Step4滑窗提取输入:由于全连接层fc的输入维数和pooled FM特征维数不同,一般pooled FM较大,例如上图中一维的例子,pooled FM维数为6,而fc的输入维数为5,所以可以采用滑窗的方式来提取不同的输入向量。
Step5 输入分类器:产生分类向量
Step6 交叉融合。
通过上面的这种方式,可以减少子采样比例,从36变为12;因为通过offset,每个维度产生了3个pooled输出。此外,由于每个输入窗口对应不同的原始图像位置,所以通过这种密集滑窗的方式可以找到物体和窗口很好的匹配,从而增加置信度;但是感觉好复杂啊。
实验结果:
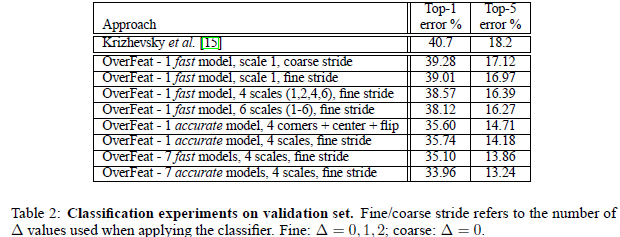
1,fast模型,比Alex-net结果提升了近1%,但是fast模型修改了很多地方,具体哪一个地方的修改其作用,这个不清楚。本文Alex-net模型结果为18.2%比他们自己测试的高2%左右
2,accurate模型单个模型提升了近4%,说明增大网络可以提高分类效果。
3,采用offset max-pooling感觉提升效果很小,感觉是因为卷积特征激活值具有很高的聚集性,每个offset特征图很相似,max-pooling后也会很相似。
4,多个缩放比例测试分类对于结果提升比较重要,通过多个比例可以把相对较小的物体放大,以便于特征捕捉。
3.5 卷积网络和滑窗效率
对比很多sliding-windows方法每次都需要计算整个网络,卷积网络非常高效,因为卷积网络在重叠区域共享计算。
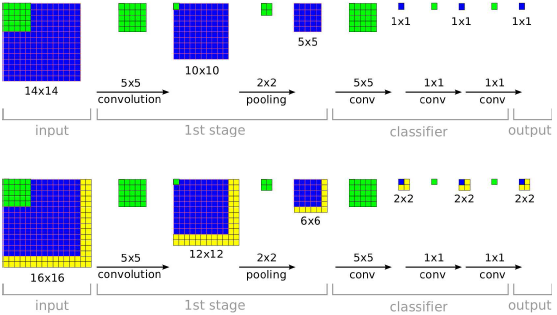
例如训练阶段在小的view(如图,14*14)下,训练网络;测试阶段在多个较大的图片上测试,由于每个14*14的view区域产生一个分类预测分布,上图在16*16的图片上测试,有4个不同的14*14的view,所以最后产生一个4个分类预测分布;组成一个具有C个特征图的2*2分类结果图,然后按照1*1卷积方式计算全连接部分;这样整个系统类似可以看做一个完整的卷积系统。
四 定位
基于训练的分类网络,用一个回归网络替换分类器网络;并在各种缩放比例和view下训练回归网络来预测boundingbox;然后融合预测的各个bounding box。
4.1 生成预测
同时在各个view和缩放比例下计算分类和回归网络,分类器对类别c的输出作为类别c在对应比例和view出现的置信分数;
4.2 回归训练
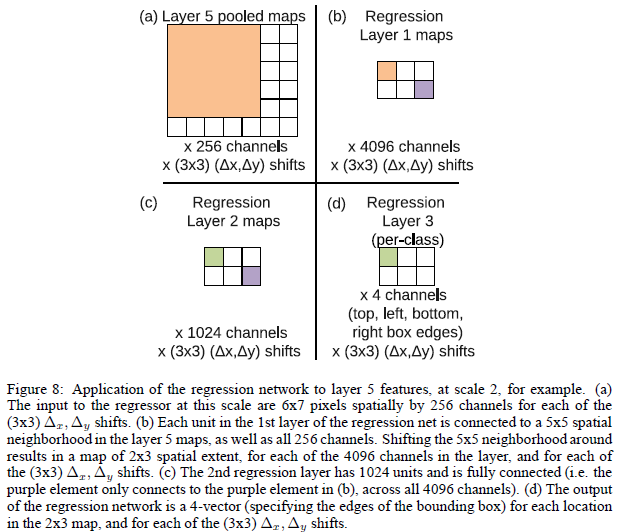
如上图所示,每个回归网络,以最后一个卷积层作为输入,回归层也有两个全连接层,隐层单元为4096,1024(为什么作者没有说,估计也是交叉实验验证的),最后的输出层有4个单元,分别是预测bounding box的四个边的坐标。和分类使用offset-pooling一样,回归预测也是用这种方式,来产生不同的预测结果。
使用预测边界和真实边界之间的L2范数作为代价函数,来训练回归网络。最终的回归层是一个类别指定的层,有1000个不同的版本。训练回归网络在多个缩放比例下对于不同缩放比例融合非常重要。在一个比例上训练网络在原比例上表现很好,在其他比例上也会表现的很好;但是多个缩放比例训练让预测在多个比例上匹配更准确,而且还会指数级别的增加预测类别的置信度。

上图展示了在单个比例上预测的在各个offset和sliding window下 pooling后,预测的多个bounding box;从图中可以看出本文通过回归预测bounding box的方法可以很好的定位出物体的位置,而且bounding box都趋向于收敛到一个固定的位置,而且还可以定位多个物体和同一个物体的不同姿势。但是感觉offset和sliding window方式,通过融合虽然增加了了准确度,但是感觉好复杂;而且很多的边框都很相似,感觉不需要这么多的预测值。就可以满足超过覆盖50%的测试要求。
4.3结合预测
a)在6个缩放比例上运行分类网络,在每个比例上选取top-k个类别,就是给每个图片进行类别标定Cs
b)在每个比例上运行预测boundingbox网络,产生每个类别对应的bounding box集合Bs
c)各个比例的Bs到放到一个大集合B
d)融合bounding box。具体过程应该是选取两个bounding box b1,b2;计算b1和b2的匹配分式,如果匹配分数大于一个阈值,就结束,如果小于阈值就在B中删除b1,b2,然后把b1和b2的融合放入B中,在进行循环计算。
最终的结果通过融合具有最高置信度的bounding box给出。
具体融合过程见下图:
1,不同的缩放比例上,预测结果不同,例如在原始图像上预测结果只有熊,在放大比例后(第三,第四个图),预测分类中不仅有熊,还有鲸鱼等其他物体

2通过offset和sliding window的方式可以有更多的类别预测

3在每个比例上预测bounding box,放大比例越大的图片,预测的bounding box越多
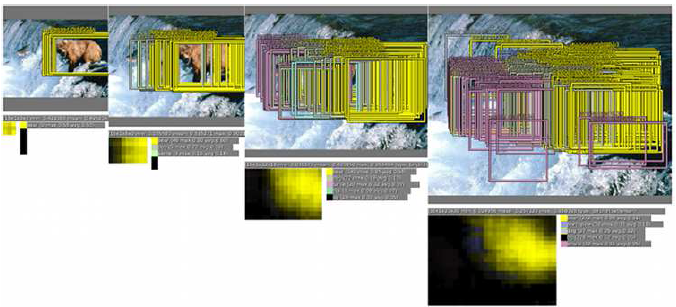
4,融合bouding box

在最终的分类中,鲸鱼预测和其他的物体消失不仅使因为更低的置信度,还有就是他们的bounding box集合Bs不像熊一样连续,具有一致性,从而没有持续的置信度积累。通过这种方式正确的物体持续增加置信度,而错误的物体识别由于缺少bounding box的一致性和置信度,最终消失。这种方法对于错误的物体具有鲁棒性(但是图片中确实有一些鱼,虽然不是鲸鱼;但是系统并没有识别出来;也可能是类别中有鲸鱼,但是没有此种鱼的类别)。
4.4实验
本文多个multi-scale和multi-view的方式非常关键,multi-view降低了4%,multi-scale降低了6%。令人惊讶的是本文PCR的结果并没有SCR好,原因是PCR的有1000个模型,每个模型都是用自己类别的数据来进行训练,训练数据不足可能导致欠拟合。而SCR通过权值共享,得到了充分的训练。
五,检测
检测和分类训练阶段相似,但是是以空间的方式进行;一张图片中的多个位置可能会同时训练。和定位不通过的是,图片内没有物体的时候,需要预测背景。
这个地方由于作者叙述的有些简略,没怎么看懂;本文的方法在ILSVRC中获得了19%,在赛后改进到24.3%;赛后主要是使用更长的训练时间和利用“周围环境”(每一个scale也同时使用低像素scale作为输入;介个有点不明白)。
六,总结
1,multi-scale sliding window方式,用来分类,定位,检测
2,在一个卷积网络框架中,同时进行3个任务
本文还可以进一步改进,
1,在定位实验总,没有整个网络进行反向传播训练
2,用评价标准的IOU作为损失函数,来替换L2
3,交换bounding box的参数,帮助去掉结果的相关性(这个有点不明白)。
后来工作2被牛津大学作者做了出来。
一些困惑和理解
感觉卷积网络真的好强大,干啥都行,而且还能相互间共享特征;虽然分类,定位,和检测的难度是递增的,但是感觉分类是最基础的,分类结果的好坏决定了后面两个任务的好坏,因为图片中物体分类准确了,才能进行定位和检测;在分类阶段调整网络部分并没有过多的叙述原因,只是给出了最后的网络结构,通过暴力式的增加复杂度,提取更多信息。
本文multi-scale测试的处理方式和SPP-net(下一篇博文)的方式有些不同,本文是通过multi-view的方式采用滑窗的方式产生多个数据结果,而Spp-net通过改变子采样比例,来得到固定的特征层输出。感觉本文的滑窗方式更适合预测bounding box和detection;因为这种方式可以是物体和view很好的匹配,从而得到很好置信得分,但是还是感觉有些复杂,例如offset是否可以使用两个,sliding window感觉可以像Alex-net那样采用5-view的方式,在特征图中选取上下左右和中间5个view进行预测就可以了,因为pooling的特征具有聚集性,感觉每个view会有很大的相似性。
图中对熊的定位实例中,卷积网络在不同的scale上面会得到不同的分类结果,在联合上一篇博文中两位作者对平移,缩放和翻转不变形的探讨;卷积网络的优势就是对于平移具有不变形,但是感觉对于平移和缩放的识别能力是有限的,对于大的物体能够很好的识别,对于小的物体感觉网络有些乏力,这可能也就是为什作者在multi-scale时,从来都是放大而不是缩小;还有就是感觉和每个高层对应底层的感受野有关,例如才本文中一个layer-5的特征激活值,对应输入层图像36*36的一个小区域,如果物体比36*36区域小,或者稍微大一些;感觉网络就会识别困难。感觉后面GoogLeNet,里面的Inception模型,就和这个有关系,不同的filter和pooling可以对应不同的初始感受野(个人观点)。
(arXiv 201312) OverFeat: Integrated Recognition, Localization and Detection usingConvolutional Networks
这是一篇2014.02的文章,作者是LeCun实验室的。这篇文章主要的贡献就是如标题所述的使用同一个卷积网络完成了多个任务。这个体现了CNN特征共享的优点。这样的思想很有用,有一些论文中用到类似的思想:比如说Synergistic face detection and pose estimation with energy-based models就使用了同一个网络做了face detection和pose estimation。再比如我在手势识别的项目中把classification和regression一起做了(思考:网络具备了这样的能力,但是是否要比分开任务的性能更好,就需要各种验证了)。
其实算法的思路很简单:输入一个raw的图像,通过同一个网络,同时完成classification,localization和detection的任务。关于这三者的定义和区别可以参见文中第2页末尾。
亮点1:多尺度-classification
通常的分类是给了一个东西,然后判定类别,但是给了一张图,不知道东西在哪该如何分类?所以一般的方法是“金字塔+sliding window”结构,然后对每一个window做一次分类。这样的算法是非常耗时的,作者认为,不需要sliding window的过程,我们可以在同一个网络里面完成。这里插一句:为什么不用直接输入图像就给出类别呢?那是因为像ImageNet这样的数据,主要的物体是在图像中央,并且大小是填充了图像相当大的部分的,所以就算是有一些variation,那也是CNN能handle的,但是如果在测试中物体只是一个很小尺寸,并且出现在图像的一个角落,那么这个variation对于训练数据来说是完全impossible的。所以直接CNN分类的效果会很差。除非训练数据覆盖了各种尺寸和位置,当然这是non-sense的。那么这篇文章是怎么实现的呢?在原图上滑窗是笨拙的,那么就在输出的feature map上滑。
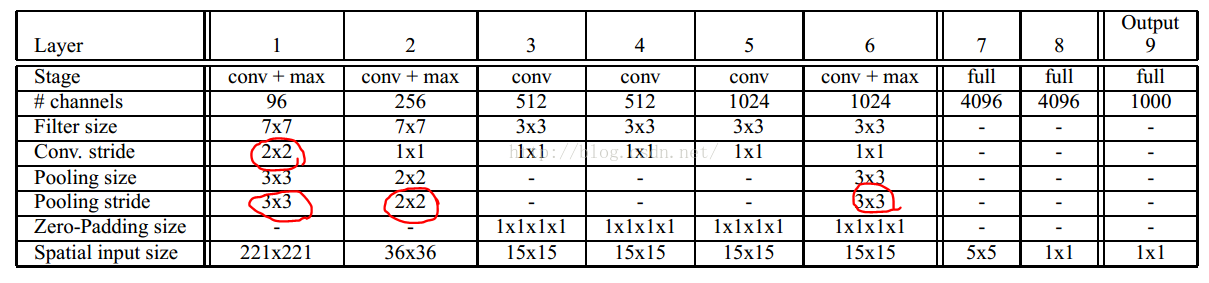
我们从网络入手,红色标记的stride表示的就相当于对原图降采样,所以才会有作者说的:“However, thetotal subsampling ratio in the network described above is 2x3x2x3, or 36.”那么对于221*221的图像来说,通过了前面的conv+pooling就瞬间变成了6*6了。现在可以开心的在这个feature map上做滑动了。可以看到layer7(第一个fc层)的输入是5*5的,也就是说用这个5*5的窗口去6*6的上面滑,就可以得到2*2的窗口了,每一个窗口对应一个位置,将这4个5*5的作为输入,分别输入fc,这样就可以得到4个C向量,C代表要分的1000个类。炫酷吧。这样实现了一个coarse滑窗。
但是作者觉得不够,这样的不够精细,*36倍呢。所以想到了一个offset的方法(灵感来自Ref【9】),参考下面图

然后作者还是觉得不够,就在输入图像就做了手脚,又从Ref【15】里面得到灵感,【15】将图像做了crop,四个corner,加一个中间,总共变成了5个子图像,然后对图像进行翻转,这样就变成了10个图像。本文作者不知道为什么采用的是“We then extract 5 random crops(and their horizontal flips)”不过核心思想是一样的,这样sliding window又变多了。
作者最后还做了一个scale上的变换,这个就没什么好说的了,把图像放缩到6个尺度上,所以,最终,这个多尺度的滑窗思想就得到实现了。

从结果来看,整体是变好了的,主要应该还是因为sliding window和scale的功劳。至于那个offset的改进,从第3,4行来看,好像并没有什么大的提升,说明差这几个像素,对于不停做convolution的图像来说,真的没啥影响。另外最后看到多模型的融合,这还是王道啊。侧面也说明了,这样的模型的学习和样本的影响在深度学习中还是有很多问题的,不稳定。
亮点2:多任务
上面说完了classification,localization就简单多了,反正就是在刚才那个架构上去regression出四个参数,表达box的四个角。输出了再combine一下,总的来说就没有什么新意了。Detection就更没什么说的了,连作者都懒得说了。
-
同时做了多个任务,这个做法我有一些看法,就是多任务一起做到底是好还是坏?我没有定论,个人感觉是要看任务的相关性,比如说classification和localization,classification会帮助提取物体自身的feature,而打破了纯粹的localization中的combined context的影响,当然这个还是要看样本的选择。当然这个还需要今后进一步的去论证。
-
滑窗,利用feature map来避免大量的sliding window,个人感觉肯定只是在原始图像上做sliding window的一种折衷方案,毕竟太耗时了。不过方法还是有一定的启发的,不知道什么时候能出一个好的解决框架。
-
多模型,多尺度,没什么说的,踏踏实实的好东西
讨论
-
“打破了纯粹的localization中的combined context的影响“?
—— 做localization实际项目时,一般物体都是处于图像的某个小区域,所以对全图做训练很容易把物体和经常出现的context combine在一起,这样一旦样本不够充分,就很容易学出combine在一起的context特征而不是单纯的object特征。 -
如果我是用原图做多scale的滑窗,和现在这个方法在feature map上做sliding window比,哪个性能好?
—— 这个没有具体的对比试验佐证,但是在最后输出的feature map上做sliding window,更像是选取了相应更好的特征区域,所以和在原图上做sliding window是不同的,从感觉上来说,对于classification这个任务来说应该是更好的,因为它打破了bounding box的约束,更好的“包含”了好的特征。另外,因为max pooling的非线性操作,所以不可能往回找到sliding window在原图上的位置 -
再插一句,如果最后出来的36个vector,直接全部fc,而不是做平均,估计效果会更好,只是怕参数量太大了。这样样本的需求也太大。不过如果这样直接连接FC层的话,才会更好的体现end-to-end的精神。















 2146
2146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









