






PromptBERT:使用提示改进BERT句子嵌入
Ting Jiang 1 ∗ , Shaohan Huang 3 , Zihan Zhang 4 , Deqing Wang 1 † , Fuzhen Zhuang 2 , Furu Wei 3 , Haizhen Huang 4 , Liangjie Zhang 4 , Qi Zhang 4 1 SKLSDE Lab, School of Computer, Beihang University, Beijing, China 2 Institute of Artificial Intelligence, Beihang University, Beijing, China 3 Microsoft Research Asia 4 Microsoft {royokong, dqwang, zhuangfuzhen}@buaa.edu.cn {shaohanh, zihzha, fuwei, hhuang, liazha, zhang.qi}@microsoft.com
摘要
BERT 算法在句子语义相似度方面表现不佳,这一问题在以往的研究中得到了广泛的讨论。我们发现,令人不满意的性能主要是由于静态token嵌入的偏差和无效的BERT层,而不是句子嵌入的高余弦相似性。
为此,我们提出了一种基于提示的句子嵌入方法,该方法可以减少token嵌入的偏差,并使原来的BERT层更加有效。通过将句子嵌入任务重新表述为填空问题,我们的方法显著提高了原始BERT算法的性能。我们讨论了基于提示的句子嵌入的两种提示表示方法和三种提示搜索方法。此外,我们利用模板去噪技术提出了一种新的无监督训练目标,大大缩短了有监督和无监督设置之间的性能差距。对于实验,我们在非微调和微调设置下评估了我们的方法。在STS任务中,即使是一种非微调方法也能比无监督ConSERT等微调方法表现得更好。我们的微调方法在无监督和有监督的情况下都优于最先进的方法SimCSE。与SimCSE相比,在无监督的情况下,我们分别比BERT和RoBERTa提高了2.29和2.58分。我们的代码在https://github.com/kongds/Prompt-BERT。
1引言
近年来,我们见证了诸如BERT(devlin et al.,2018)和RoBERTa(Liu et al.,2019)等预训练语言模型在句子嵌入方面的成功(Gao et al.,2021;Yan et al.,2021)。然而,原始的BERT在句子嵌入方面仍然表现不佳(Reimers和Gurevych,2019;Li等人,2020)。最常用的例子是,它的性能低于传统的单词嵌入方法,如GloVe(Pennington et al.,2014)。
之前的研究已将各向异性联系起来,以解释原始BERT的不良性能(Li et al.,2020;Yan et al.,2021;Gao et al.,2021)。各向异性使得token嵌入占据了一个狭窄的圆锥体,导致任何句子对之间的高度相似性(Li等人,2020)。(2020)提出了一种归一化流方法,将句子嵌入分布转化为光滑和各向同性的高斯分布和YANN等。(2021)提出了一种转换句子表示的对比框架。这些方法的目标是消除句子嵌入中的各向异性。然而,我们发现各向异性并不是语义相似性差的主要原因。
例如,在语义-文本相似性任务中,平均原始BERT的最后一层甚至比平均其静态token嵌入更糟糕,但最后一层的句子嵌入比静态token嵌入的各向异性更小。
根据这个结果,我们发现原来的BERT第二层实际上损害了句子嵌入的质量。然而,如果我们将静态token嵌入3视为单词嵌入,与GloVe相比,它仍然会产生不令人满意的结果。受(Li et al.,2020)的启发,他发现token频率偏差其分布,我们发现这种分布不仅受频率的影响,还受词条中区分大小写和子词的影响(Wu et al.,2016)。我们设计了一个简单的实验来测试我们的猜测,只需删除这些有偏差的tokens(例如,高频子词和标点符号),并使用剩余的token嵌入的平均值作为句子表示。它的性能优于Glove,甚至可以达到与后处理方法BERT-flow(Li et al.,2020)和BERT-whitening(Su et al.,2021)相当的结果。
基于这些发现,避免嵌入偏见可以提高句子表征的表现。然而,手动消除嵌入的偏差需要耗费大量人力,如果句子太短,可能会导致遗漏一些有意义的单词。受(Brown et al.,2020)的启发,我们提出了一种基于提示的方法,通过使用模板获得BERT中的句子表示,将不同的NLP任务重新表述为通过不同提示来填充空白问题。基于提示的方法可以避免嵌入偏差,并利用原始BERT层。
我们发现,原始BERT算法在句子嵌入中借助模板可以获得合理的性能,甚至优于一些基于BERT算法的方法,这些方法可以在下游任务中微调BERT。
我们的方法同样适用于微调设置。目前的方法利用对比学习帮助BERT更好地学习句子嵌入(Gao等人,2021;Yan等人,2021)。然而,无监督方法仍然存在泄漏适当的正对的问题。Yan等人(2021)讨论了四种数据增强方法,但其性能似乎比直接使用BERT中的dropout作为噪声要差(Gao等人,2021)。我们发现提示可以提供一种更好的方法,通过来自不同模板的不同视点生成正对。为此,我们提出了一种基于提示和模板去噪的对比学习方法,以在无监督环境下利用BERT的能力,显著缩短监督和无监督性能之间的差距。我们的方法在无监督和有监督的环境中都达到了最先进的效果。
2.相关工作
学习句子嵌入作为一个基本的自然语言处理问题已经得到了大量的研究。目前,如何利用BERT在句子嵌入中的力量已成为一种新的趋势。许多作品(Li et al.,2020;Gao et al.,2021)在有监督和无监督的环境中都与BERT取得了很好的表现。在这些作品中,基于对比学习的方法取得了最先进的成果。这些著作(Gao等人,2021;Yan等人,2021)注意力构建正句对。Gao等人(2021)提出了一个新的对比训练目标,即直接使用内部dropout作为噪声来构建正对。Yan等人(2021)讨论了构建正对的四种方法。
虽然BERT在句子嵌入方面取得了巨大的成功,但原BERT的表现并不令人满意。原文BERT的上下文token嵌入甚至不如GloVe这样的单词嵌入。一种解释是原始BERT的各向异性,这导致句子对具有很高的相似性。根据这一解释,BERT流(Li et al.,2020)和BERT白化(Su et al.,2021)被提议通过对原始BERT的句子嵌入进行后处理来减少各向异性。
3重新思考原始BERT之前作品中的句子嵌入(Yan et al.,2021;Gao et al.,2021)解释了原始BERT的糟糕表现受到学习到的各向异性token嵌入空间的限制,token嵌入占据了一个窄锥。然而,通过研究非对称性和性能之间的关系,我们发现各向异性并不是导致语义相似性差的关键因素。我们认为主要原因是无效的BERT层和静态token嵌入偏差。
观察1:原来的BERT层无法提高性能。在本节中,我们通过比较两种句子嵌入方法来分析BERT层的影响:平均静态token嵌入(BERT层的输入)和平均最后一层(BERT层的输出)。我们报告了句子嵌入的表现及其句子水平的各向异性。
为了测量各向异性,我们遵循(Ethayarakh,2019)的工作来测量句子嵌入中的句子级各向异性。让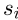 成为出现在语料库
成为出现在语料库 中的句子。各向异性可以如下方式度量:
中的句子。各向异性可以如下方式度量:
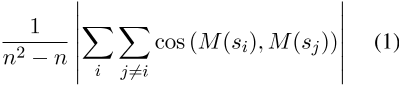
其中M表示句子嵌入方法,该方法将原始句子映射到其嵌入,cos表示余弦相似性。换句话说,M的各向异性是通过一组句子的平均余弦相似性来衡量的。如果句子嵌入是各向同性的(即方向一致),那么均匀随机抽样的句子之间的平均余弦相似性将为0(Arora等人,2016)。它越接近1,句子的嵌入就越各向异性。
我们从维基百科语料库中随机抽取10万个句子来计算各向异性。
我们比较了不同的预训练模型(bertbase uncased、bert base cased和roberta base)和不同的句子嵌入方法(最后一层avgerage,最后一个隐藏层tokens作为句子嵌入的平均值和静态token嵌入的平均值,静态token嵌入的直接平均值)。
我们在表1中展示了这些方法的斯皮尔曼相关性和句子层面的各向异性。
如表1所示,我们发现BERT基uncased和roberta基中的BERT层对句子嵌入性能有显著影响。即使在bert基本情况下,bert层的增益也微不足道,只有0.28的改进。我们还展示了每种方法在句子层面的各向异性。
BERT层的性能退化似乎与句子层次的各向异性无关。例如,最后一层平均值比bert base uncased中的静态token嵌入平均值更各向同性。然而,静态token嵌入平均值实现了更好的句子嵌入性能。
观察2:嵌入偏差会损害句子嵌入的表现。Li等人(2020)发现,token嵌入可能会偏向于token频率。类似的问题已被研究(颜等人,2021)。BERT静态token嵌入的各向异性对token频率敏感。因此,我们研究了嵌入偏差是否会导致句子嵌入的性能不理想。我们观察到,token嵌入不仅受token频率的影响,还受词条中的子词(Wu等人,2016)和区分大小写的影响。
如图1所示,我们在bert base uncased、bert base cased和roberta base的token嵌入中可视化了这些偏差。三个预训练模型的token嵌入受token频率、子词和大小写的影响较大。
token嵌入根据子词和大小写的偏差大致分为三个区域:1)单词tokens的小写开头,2)单词tokens的大写开头,3)子词tokens。对于uncased预训练的模型bert base uncased,token嵌入也可以大致分为两个区域:1)单词tokens的开头,2)子单词tokens。
对于频率偏差,我们可以观察到高频tokens是集群的,而低频tokens在所有模型中都是稀疏分布的(Yan等人,2021)。在BERT中,单词tokens的开头比子单词tokens更容易受到频率的影响。然而,子词tokens在RoBERTa中更容易受到攻击。
之前的研究(Yan等人,2021;Li等人,2020年)经常将“token嵌入偏差”的概念与token嵌入各向异性联系起来,作为偏差的原因。然而,我们认为各向异性与偏压无关。偏差意味着嵌入的分布受到一些无关信息的干扰,如token频率,这些信息可以根据主成分分析直接可视化。对于各向异性,这意味着整个嵌入在高维向量空间中占据了一个狭窄的圆锥体,无法直接可视化。
表2显示了图1中三个预训练模型的静态token嵌入各向异性,根据任意两个token嵌入之间的平均余弦相似性。与之前的结论相反(Yan et al.,2021;Li et al.,2020),我们发现只有bert-base-uncased的静态token嵌入是高度各向异性的。静态token嵌入(如roberta base)是各向同性的,平均余弦相似性为0.0235。对于偏差,这些模型受到静态token嵌入中的偏差的影响,这与各向异性无关。
为了证明偏差的负影响,我们将静态token嵌入平均为句子嵌入(无BERT层),以显示偏差对句子嵌入的影响。在表3中的三个预训练模型上,消除嵌入偏差的结果令人印象深刻。只需删除一组tokens,结果就可以分别提高9.22、7.08和11.76。roberta base的最终结果可以优于仅使用静态token嵌入的后处理方法,如BERT flow(Li et al.,2020)和BERT whitening(Su et al.,2021)。
手动消除嵌入偏差是提高句子嵌入性能的一种简单方法。然而,如果句子太短,这不是一个适当的解决方案,这可能会导致遗漏一些有意义的单词。
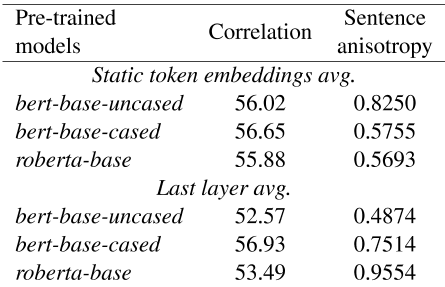
表1:最后一层平均值的斯皮尔曼相关性。和静态token嵌入平均值。斯皮尔曼相关性是STS12-16、STS-B和SICK的平均相关性。

表2:静态token嵌入的平均余弦相似性
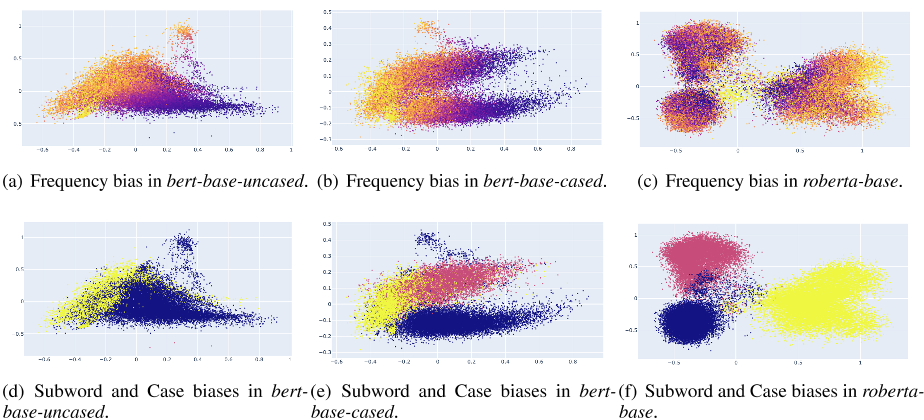
图1:具有不同biases的token嵌入的二维可视化。对于频率偏移,颜色越深,token频率越高。对于子字和大小写偏差,黄色表示子字,红色表示包含大写字母的token。
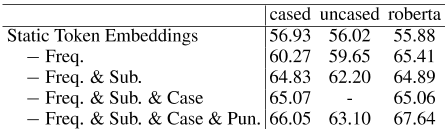
表3:静态嵌入biases对spearman相关性的影响。spearman相关性是STS12-16、STS-B和SICK的平均值。Cased、uncased和roberta代表bert base Cased、bert baseuncased和roberta base。对于Freq.,Sub.,Case,还有双关语。我们分别删除了高频率的tokens、子词tokens、大写tokens和标点符号。更多细节见附录A。
4.基于提示的句子嵌入
受(Brown et al.,2020)的启发,我们提出了一种基于提示的句子方法来获得句子嵌入。通过将句子嵌入任务重新表述为掩码语言任务,我们可以利用大规模知识有效地使用原始BERT层。我们还通过从[MASK] tokens表示句子来避免嵌入biase。
然而,与文本分类或问答任务不同,句子嵌入的输出不是传销分类负责人预测的标签tokens,而是表示句子的向量。我们根据这两个问题来讨论基于提示的句子嵌入的实现:1)如何用提示来表示句子,2)如何为句子嵌入找到合适的提示。在此基础上,我们提出了一种基于提示的对比学习方法来微调BERT的句子嵌入。
4.1用提示语表达句子
在本节中,我们将讨论两种用提示来表示一个句子的方法。例如,我们有一个模板“[X]表示[MASK]”,其中[X]是放置句子的占位符,[MASK]表示[MASK]token。给定中的一个句子x,我们用模板将x映射到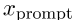 。然后,我们将
。然后,我们将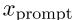 馈送到预先训练的模型中,以生成句子表示h。
馈送到预先训练的模型中,以生成句子表示h。
一种方法是使用[掩码]token的隐藏向量作为句子表示:

对于第二种方法,与其他基于提示的任务一样,我们根据h[掩码]和MLM分类头获得前k个tokens,然后根据概率分布找到这些tokens的加权平均值。h可以表示为:

其中相对于前k个tokens集中的BERT token,W相对于v的静态token嵌入,
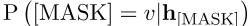
表示MLM头预测token v的概率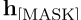 。
。
第二种方法将句子映射到tokens,比第一种方法更为常规。
但它的缺点是显而易见的:1)如前所述,由于静态token嵌入的平均值产生的句子嵌入,它仍然存在偏差。2) 权重平均使BERT难以在下游任务中进行微调。由于这些原因,我们用第一种方法表示带有提示的句子。
4.2提示搜索
对于基于提示的任务,一个关键挑战是找到模板。本节讨论了三种搜索模板的方法:人工搜索、基于T5的模板生成(Gao等人,2020)和optiprompt(Zhong等人,2021)。我们使用STS-B开发集中的斯皮尔曼相关性作为评估不同模板的主要指标。
对于人工搜索,我们需要手工制作模板,鼓励整个句子用h[掩码]表示。为了搜索模板,我们将模板分为两部分:关系tokens(表示[X]和[掩码]之间的关系)和前缀tokens(包装[X])。
然后,我们贪婪地按照tokens和前缀tokens之间的关系搜索模板。
贪婪搜索的一些结果如表4所示。当涉及到句子嵌入时,不同的模板会产生极其不同的结果。
与简单地连接[X]和[MASK]相比,像这样的复杂模板:“[X]”意味着[MASK],可以将斯皮尔曼相关性提高34.10。
对于基于T5的模板生成,Gao等人(2020)提出了一种新的方法,通过使用T5根据句子和相应标签生成模板来自动生成模板。生成的模板可以优于GLUE基准中的人工搜索模板(Wang et al.,2018)。
然而,实现它的主要问题是缺少标签tokens。Tukgasoi等人(2021)通过将字典中的定义句分类为单词,成功地将句子嵌入任务转化为文本分类任务。受此启发,我们使用单词和相应的定义生成了500个模板(例如,橙色:一种巨大的圆形多汁柑橘类水果,果皮坚硬、亮红黄色)。然后我们在STS-B开发集中评估这些模板,最佳spearman相关性为64.75,模板“也称为[MASK].[X]”。也许这是句子嵌入和单词定义之间的差距。
与人工搜索相比,此方法无法生成更好的模板。
OptiPrompt(锺等人,2021)用连续模板代替离散模板。为了优化连续模板,我们根据(Gao等人,2021)中的设置,将无监督对比学习作为训练目标,冻结整个BERT参数,并通过人工tem板的静态token嵌入初始化连续模板。与输入的人工模板相比,连续模板可以将STS-B开发集上的spearman相关性从73.44增加到80.90。

表4:bert baseuncased上的贪婪搜索模板。
4.3基于提示的对比学习与模板去噪
最近,对比学习成功地利用了BERT在句子嵌入方面的力量。
句子嵌入对比学习面临的一个挑战是如何构建恰当的正实例。
Gao等人(2021)直接将BERT中的dropout作为正实例。Yan et al.(2021)讨论了四种数据增强策略,例如在输入token嵌入中的对抗性攻击、token洗牌、切断和dropout,以构建正实例。受基于提示的句子嵌入的启发,我们提出了一种基于提示合理生成正实例的新方法。
其想法是使用不同的模板将同一个句子表示为不同的观点,这有助于模型生成更合理的正对。为了减少模板本身对句子表示的影响,我们提出了一种新的模板信息去噪方法。
给定句子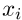 ,我们首先用模板计算嵌入h i的相应句子。然后,我们通过直接向BERT提供模板和相同的模板位置ID来计算模板偏差ĥi。例如,如果
,我们首先用模板计算嵌入h i的相应句子。然后,我们通过直接向BERT提供模板和相同的模板位置ID来计算模板偏差ĥi。例如,如果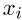 有5个tokens,则在[X]之后的模板tokens的位置ID将添加5,以确保模板的位置ID相同。最后,我们可以直接使用
有5个tokens,则在[X]之后的模板tokens的位置ID将添加5,以确保模板的位置ID相同。最后,我们可以直接使用 作为去噪的句子表示。关于模板去噪,更多细节可以在讨论中找到。
作为去噪的句子表示。关于模板去噪,更多细节可以在讨论中找到。
形式上,让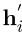 和h i表示
和h i表示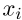 的句子嵌入具有不同模板,
的句子嵌入具有不同模板,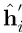 和
和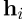 分别表示
分别表示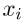 的两个模板偏差,最终的训练目标如下:
的两个模板偏差,最终的训练目标如下:
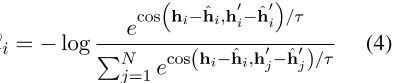
,其中τ是对比学习中的温度超参数,N是小批量的大小。
5 实验
我们在非微调和微调BERT设置的STS任务上进行了实验。对于非微调BERT设置,我们利用了原始BERT在句子嵌入中的性能,这与之前发现的原始BERT性能不佳的结果相对应。对于微调BERT设置,我们通过微调下游任务的BERT来报告无监督和有监督的结果。转移任务的结果见附录B。
5.1数据集
继过去的作品(严等人,2021;高等人,2021;Reimes和GuurvyCH,2019),我们在7个常见STS数据集上进行实验:STS任务2012-2016(AgRRE等人,2012, 2013, 2014,2015, 2016)STS- B(CER等人,2017),患病-R(Marelli等人,2014)。我们使用SentEval工具包(Conneau和Kiela,2018)下载所有7个数据集。每个数据集中的句子对得分从0到5,以表示语义相似性。
5.2基线
我们将我们的方法与启发性和最先进的方法进行比较。为了验证我们的方法在非微调设置下的有效性,我们使用GLoVe(Pennington et al.,2014)和后处理方法:BERT flow(Li et al.,2020)和BERT whitening(Su et al.,2021)作为基线。对于微调设置,我们将我们的方法与IS-BERT(Zhang et al.,2020)、Infresent(Conneau et al.,2017)、Universal Session Encoder(Cer et al.,2018)、SBERT(Reimers and Gurevych,2019)和基于对比学习的方法进行比较:SimCSE(Gao et al.,2021)和ConSERT(Yan et al.,2021)。
5.3实施细节
对于非微调设置,我们报告了BERT的结果,以验证我们的表示方法的有效性。对于微调设置,我们使用BERT和RoBERTa与相同的无监督和有监督训练数据(Gao等人,2021)。我们的方法采用基于即时对比学习的模板去噪训练。
根据表4,人工搜索用于两种设置的模板。更多细节见附录C。
5.4非微调BERT结果
为了与之前对原始BERT较差性能的分析相联系,我们在表5中报告了基于提示的非微调BERT方法。使用模板可以大大改进所有数据集上原始BERT的结果。
与最后一层平均或第一层和最后一层平均等合并方法相比,我们的方法可以将spearman相关性提高10%以上。与后处理方法BERT flow和BERT whitening相比,只有使用人工模板才能超越这些方法。
此外,我们可以使用OptiPrompt的连续模板来帮助原始BERT获得更好的结果,甚至优于表6中的无监督ConSERT。
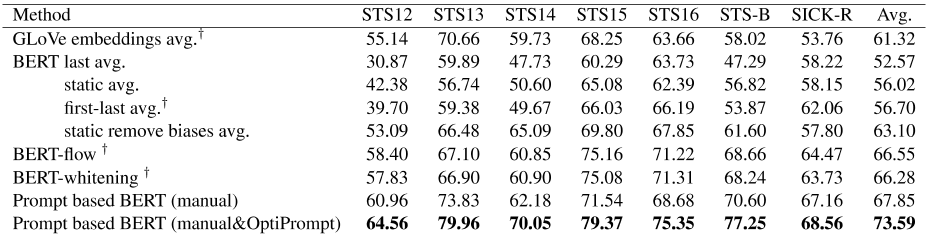
表5:我们的未优化BERT方法在STS任务上的性能比较。†:结果来自(Gao 等人,2021)。bert-flow(Li 等人,2020)和BERT-whitening(SU等人,2021)使用“NLI”设置。所有基于BERT的方法都使用未基于BERT-base的方法。Last avg.表示平均BERT的最后一层。静态平均值表示平均BERT的静态token嵌入。第一个最后的AVG(SU等人,2021)使用第一层和最后一层。Static remove biase avg.表示在Static avg.中移除有偏差的tokens,这是我们之前介绍的。
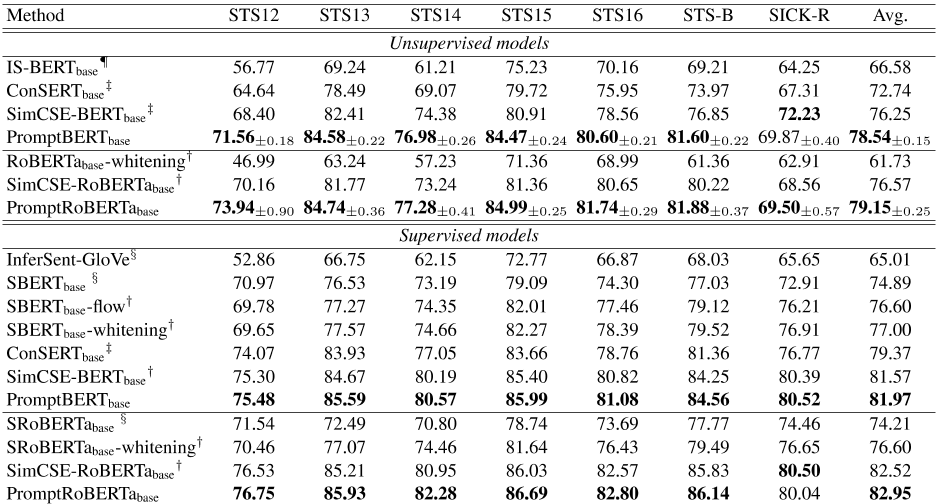
表6:我们微调的BERT方法在STS任务上的性能比较。对于无监督模型,我们发现无监督收缩学习的结果不稳定,我们用10个随机种子训练我们的模型。†:(高等人,2021)的结果:结果来自(严等人,2021)。§:结果来自(Reimers和Gurevych,2019年)。¨:结果来自(Zhang等人,2020年)。
5.5微调BERT结果
微调BERT的结果如表6所示。在之前的工作(Reimers和Gurevych,2019)之后,我们分别运行了无监督和有监督的方法。虽然现有的基于对比学习的方法(高等人,2021;Yun等人,2021)相比以前的方法取得了显著的改进,但我们的方法仍然优于它们。基于提示的对比学习目标显著缩短了无监督和有监督方法之间的差距。这也证明了我们的方法可以利用具有不同模板的未标记数据的知识作为正对。此外,我们报告了10个随机种子的无监督性能,以获得更准确的结果。在讨论中,我们还报告了10个随机种子的SimCSE结果。与SimCSE相比,我们的方法显示出更稳定的结果。

表7:人工模板与原始BERT预测的前5名tokens。
5.6基于提示的对比学习与模板去噪的有效性
我们报告了不同无监督训练目标在基于提示的BERT训练中的结果。我们使用以下训练目标:1)相同的模板,使用内部dropout噪声作为数据增强(Gao等人,2021)2)不同的模板作为正对3)不同的模板进行模板去噪(我们的默认方法)。此外,我们使用相同的模板和设置进行预测,并且只改变在训练阶段生成正对的方式。所有结果均来自10次随机运行。结果如表8所示。我们观察到,在三个训练目标中,我们的方法可以达到最佳和最稳定的结果。

表8:无监督学习的不同训练目标的比较。
6讨论
6.1模板去噪
我们发现,模板去噪有效地消除了模板的偏差,提高了MLM头在原始BERT中预测的top-k tokens的质量。如表7所示,我们预测了一些句子在[掩码]tokens中的前5名tokens。我们发现模板去噪去除了不相关的tokens,如“nothing,no,yes”,并帮助模型预测更多相关的tokens。为了量化这一点,我们还使用前200个tokens的加权平均值作为句子嵌入来表示等式3中的句子。结果如表9所示。
模板去噪显著提高了传销主管预测的tokens的质量。然而,它不能改善等式2中默认表示方法的性能(表9中的[掩码]token)。在这项工作中,我们仅在对比训练目标中使用模板去噪,这有助于消除不同的模板偏差。

表9:句子嵌入中模板去噪的影响。
6.2无监督对比学习的稳定性
为了证明非监督对比学习在句子嵌入中的不稳定结果,我们还用表10中的10个随机种子复制了非监督simcsebert库的结果。我们的结果比SimCSE更稳定。在SimCSE中,最佳和最差结果之间的差异可能高达3.14%。然而,我们方法中的差距仅为0.53。

表10:无监督对比学习的结果。
7结论
在本文中,我们分析了原始BERT在句子嵌入方面表现不佳的问题。主要原因不是各向异性,而是静态token嵌入了偏差,无法有效地使用原始BERT层。基于这些发现,我们提出了一种基于提示的句子嵌入方法,以避免静态token嵌入偏差,并利用原始BERT层中预先训练的知识。我们的方法显著提高了原始BERT算法的性能。我们还提出了一种新的基于提示的对比学习方法,以缩短无监督和有监督方法之间的差距。
参考文献
Eneko Agirre, Carmen Banea, Claire Cardie, Daniel Cer, Mona Diab, Aitor Gonzalez-Agirre, Weiwei Guo, Inigo Lopez-Gazpio, Montse Maritxalar, Rada Mihalcea, et al. 2015. Semeval-2015 task 2: semantic textual similarity, english, spanish and pilot on interpretability. In Proceedings of the 9th international workshop on semantic evaluation (SemEval 2015) , pages 252–263.
Eneko Agirre, Carmen Banea, Claire Cardie, Daniel Cer, Mona Diab, Aitor Gonzalez-Agirre, Weiwei Guo, Rada Mihalcea, German Rigau, and Janyce Wiebe. 2014. Semeval-2014 task 10: Multilingual semantic textual similarity. In Proceedings of the 8th international workshop on semantic evaluation (SemEval 2014) , pages 81–91.
Eneko Agirre, Carmen Banea, Daniel Cer, Mona Diab, Aitor Gonzalez Agirre, Rada Mihalcea, german Rigau Claramunt, and Janyce Wiebe. 2016. Semeval-2016 task 1: Semantic textual similarity, monolingual and cross-lingual evaluation. In SemEval-2016. 10th International Workshop on semantic Evaluation; 2016 Jun 16-17; San Diego, CA. Stroudsburg (PA): ACL; 2016. p. 497-511. ACL (association for Computational Linguistics).
Eneko Agirre, Daniel Cer, Mona Diab, and Aitor Gonzalez-Agirre. 2012. Semeval-2012 task 6: A pilot on semantic textual similarity. In * SEM 2012: The First Joint Conference on Lexical and computational Semantics–Volume 1: Proceedings of the main conference and the shared task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation (SemEval 2012) , pages 385– 393.
Eneko Agirre, Daniel Cer, Mona Diab, Aitor gonzalezagirre, and Weiwei Guo. 2013. * sem 2013 shared task: Semantic textual similarity. In Second joint conference on lexical and computational semantics (* SEM), volume 1: proceedings of the Main conference and the shared task: semantic textual similarity , pages 32–43.
Sanjeev Arora, Yingyu Liang, and Tengyu Ma. 2016. A simple but tough-to-beat baseline for sentence embeddings. Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165 . Daniel Cer, Mona Diab, Eneko Agirre, Inigo lopezgazpio, and Lucia Specia. 2017. Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation. arXiv preprint arXiv:1708.00055 .
Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, et al. 2018. Universal sentence encoder for english. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages 169–174.
Alexis Conneau and Douwe Kiela. 2018. Senteval: An evaluation toolkit for universal sentence representations. arXiv preprint arXiv:1803.05449 .
Alexis Conneau, Douwe Kiela, Holger Schwenk, Loic Barrault, and Antoine Bordes. 2017. Supervised learning of universal sentence representations from natural language inference data. arXiv preprint arXiv:1705.02364 .
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 .
Kawin Ethayarajh. 2019. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings. arXiv preprint arXiv:1909.00512 .
Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, and tieyan Liu. 2019. Representation degeneration problem in training natural language generation models. arXiv preprint arXiv:1907.12009 .
Tianyu Gao, Adam Fisch, and Danqi Chen. 2020. Making pre-trained language models better few-shot learners. arXiv preprint arXiv:2012.15723 .
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. Simcse: Simple contrastive learning of sentence embeddings. arXiv preprint arXiv:2104.08821 .
Bohan Li, Hao Zhou, Junxian He, Mingxuan Wang, Yiming Yang, and Lei Li. 2020. On the sentence embeddings from bert for semantic textual similarity. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages 9119–9130.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019.
Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 .
Marco Marelli, Stefano Menini, Marco Baroni, Luisa Bentivogli, Raffaella Bernardi, Roberto Zamparelli, et al. 2014. A sick cure for the evaluation of compositional distributional semantic models. In Lrec , pages 216–223. Reykjavik.
Jeffrey Pennington, Richard Socher, and Christopher D Manning. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) , pages 1532–1543.
Nils Reimers and Iryna Gurevych. 2019. sentencebert: Sentence embeddings using siamese bertnetworks. arXiv preprint arXiv:1908.10084 .
Jianlin Su, Jiarun Cao, Weijie Liu, and Yangyiwen Ou. 2021. Whitening sentence representations for better semantics and faster retrieval. arXiv preprint arXiv:2103.15316 .
Hayato Tsukagoshi, Ryohei Sasano, and Koichi Takeda. 2021. Defsent: Sentence embeddings using definition sentences. arXiv preprint arXiv:2105.04339 .
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2018. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461 .
Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. 2016. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144 .
Yuanmeng Yan, Rumei Li, Sirui Wang, Fuzheng Zhang, Wei Wu, and Weiran Xu. 2021. consert: A contrastive framework for self-supervised sentence representation transfer. arXiv preprint arXiv:2105.11741 .
Yan Zhang, Ruidan He, Zuozhu Liu, Kwan Hui Lim, and Lidong Bing. 2020. An unsupervised sentence embedding method by mutual information maximization. arXiv preprint arXiv:2009.12061 .
Zexuan Zhong, Dan Friedman, and Danqi Chen. 2021. Factual probing is [mask]: Learning vs. learning to recall. arXiv preprint arXiv:2104.05240 .
嵌入偏差的静态Token
A、 1通过移除Tokens消除偏差
我们报告了通过删除bert base uncased、bert base cased和roberta base上的tokens来消除静态token嵌入偏差的详细实现。对于Freq.tokens,我们遵循(Yan等人,2021)中的设置,删除前36个常见tokens。删除的频率tokens如表11所示。对于子tokens,我们直接删除所有子词tokens(图2中的黄色tokens)。以防万一。tokens,only SICK(Marelli et al.,2014)的句子有大写和小写,我们将这些句子小写以删除大写的tokens(图2中的红色tokens)。双关语。,我们删除了只包含标点符号的tokens。
A、 2通过预训练消除偏差
根据(Gao et al.,2019),我们发现静态token嵌入中的大多数偏差是梯度移除的高频Tokens bert base uncased。a在,是to of and’on and-s with for“at####s woman是两个你说玩bert base cased an as as from:由传销分类头权重中的white生成,它将[掩码]的最后一个隐藏向量转换为所有tokens的概率。静态token嵌入和传销分类头之间的绑定权重导致静态token嵌入存在偏差问题。
我们以传销预训练为目标,对两个类似BERT的模型进行了预训练。这两个预先训练好的模型之间的唯一区别是在静态token嵌入和传销分类头之间绑定和释放权重。我们已经对这两个模型进行了125k级的预训练,批量为2k。
如图2所示,我们已经显示了解绑模型的静态token嵌入、解绑模型的传销头权重和捆绑模型的静态token嵌入(传销头权重)。
搭售模型的分布和解开模型的头重与图1中bert-base的分布相同,这严重受到嵌入偏差的影响。然而,解开权重模型中嵌入的token的分布受这些偏差的影响较小。我们还在表12中报告了三种嵌入STS任务的平均斯皮尔曼相关性。解构模型的静态token嵌入在三种嵌入之间实现了最佳的相关性。

表11:删除了bert basecased、bert base uncased和roberta base中前36个常见的tokens。

表12:三种嵌入的平均斯皮尔曼相关性。
B.转移任务
我们还评估了以下传输任务的模型:MR、CR、Sub、MPQA、SST-2、TREC和MRPC。我们遵循SentEval 4中的默认配置。结果如表13所示。与SimCSE相比,基于RoBERTa的方法在无监督模型和有监督模型上分别提高了2.52和0.92。

图2:预训练模型中解开和系紧权重的静态token嵌入的二维可视化。对于频率偏移,颜色越深,token频率越高。对于子字和大小写偏差,黄色表示子字,红色表示包含大写字母的token。
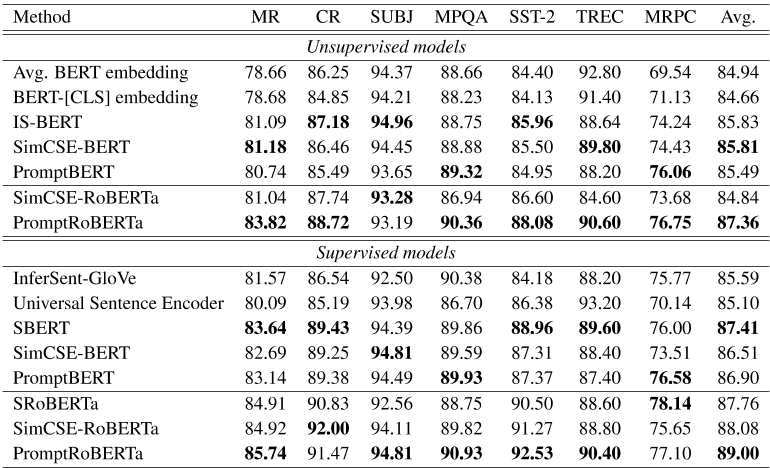
表13:不同句子嵌入模型的迁移任务结果。
C训练详情
对于非微调设置,我们使用的人工模板是这样一句话:“[X]”表示[屏蔽]。对于OptPrompt,我们首先用人工模板初始化模板嵌入,然后用无监督的训练任务冻结BERT,然后(Gao等人,2021)对这些模板嵌入进行训练,批量大小、学习率、历元和有效步数分别为256、3e-5、5和1000。
对于微调设置,所有训练数据与相同(Gao等人,2021)。最大句子序列长度设置为32。对于模板,我们只使用人工模板,在未联网的模型中根据STS-B dev手动搜索。模板如表14所示。对于无监督方法,我们根据基于提示的训练目标,使用两种不同的模板进行无监督训练,并进行模板去噪。在预测中,我们直接使用一个模板,而不进行模板去噪。对于有监督的方法,我们使用相同的模板进行对比学习,因为我们已经监督了负样本。我们还在表15中报告了其他训练细节。

表14:微调设置下的方法模板

表15:我们的方法在微调设置下的超参数
















 9820
9820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









