







一、核心
句子表征存在不足之处,可能面临各向异性、可能受到词频的影响、可能受到子词、大小写等的影响等等。
Gao et al.(2019)和Wang et al.(2020)指出,对于语言建模,使用最大似然训练通常会产生一个各向异性的词嵌入空间。“各向异性”是指单词嵌入在向量空间中占据一个狭窄的锥体。这种现象也可以在Bert、GPT-2等预训练过的Transformers上观察到。
二、已有的工作
之前的一些工作,也在做相关的校准工作。
比较的好的结果是,词向量具备各项同向性。
已有工作中的一些发现,也很有意思和价值。
we find that anisotropy may not be the primary cause of poor semantic similarity。各项异性并不是弱语义相似度的主要原因。
if we treat static token embeddings as word embedding, it still yields unsatisfactory results compared to GloVe。如果使用bert生成的静态语义向量,产生的结果可能并没有像glove那种令人满意。
the distribution of token embeddings is not only biased by frequency, but also case sensitive and subword in WordPiece
词向量分布不仅受到词频的影响,也受到wordpiece中子词和大小写的影响。
contrastive learning to help the BERT learn better sentence embeddings (Gao et al., 2021b; Yan et al., 2021).
1.BERT-flow
论文:On the Sentence Embeddings from Pre-trained Language Models
这篇论文看下,相似度计算相关的部分。
原文链接:知乎原文
我们提出通过标准化流将BERT句子嵌入分布转换为平滑的各向同性的高斯分布,这是一个由神经网络参数化的可逆函数。具体来说,我们学习了一个基于流的生成模型,以无监督的方式最大化从一个标准高斯潜变量生成BERT句子嵌入的可能性。在训练过程中,只优化了流网络,BERT参数保持不变。然后利用学习的流,即BERT语句嵌入与高斯潜在变量之间的可逆映射函数,将BERT语句嵌入转换到高斯空间。我们将提出的方法命名为BERT-flow。
在不使用任何下游监督的情况下,我们对7个标准语义文本相似度基准进行了广泛的实验。我们的实证结果表明,在cosine嵌入相似度与人标注相似度的Spearman相关性方面,该流变换能够最大提高BERT高达12.70个点,平均提高8.16个点。当与来自自然语言推理任务的外部监督相结合时,我们的方法优于sentence- bert嵌入,得到了最优结果。除了在语义相似性任务上,在问答蕴含任务上也展现了其优越性。
此外,我们进一步的分析表明,bert训练的相似度与词汇相似度过度相关,而不是语义相似度,而我们提出的基于流的方法可以有效地解决这一问题。
Bert在解决语义相似度问题上
Reimers and Gurevych(2019)证明,BERT句子嵌入在语义相似性方面落后于先进的句子嵌入。在STS-B数据集上,甚至落后于几年前简单的、无上下文的GloVe。同时,他们表明使用上下文嵌入的均值要优于[CLS]嵌入。
三、这篇论文
词向量的校准工作,采用的对比学习,PromptBERT,一种用于学习更好的句子表示的新型对比学习方法。我们首先分析了原始 BERT 当前句子嵌入的缺点,发现这主要是由于静态标记嵌入偏差和无效的 BERT 层。然后我们提出了第一个基于提示的句子嵌入方法,并讨论了两种提示表示方法和三种提示搜索方法,以使 BERT 实现更好的句子嵌入。此外,我们通过模板去噪技术提出了一种新颖的无监督训练目标,大大缩短了监督和无监督设置之间的性能差距.
3.1观察一——layers embedding不一定能够改善performance
1.随机选择两个句子,形成句子对,计算句子对彼此之间的相似度。
2.各向异性的评测是计算句子对之间的余弦相似度的平均值。
3.如果值越接近于1,则越具备各向异性。(值越接近于1,余弦相似度越大)
实施环节: randomly sample 100,000 sentences from the Wikipedia corpus to compute the anisotropy.
Let si be a sentence that appears in corpus {s1, …, sn}. n为句子的数量,M为相似度测评函数。
计算公式: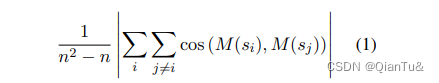
实验结果: last layer的emebedding的各向异性很大。
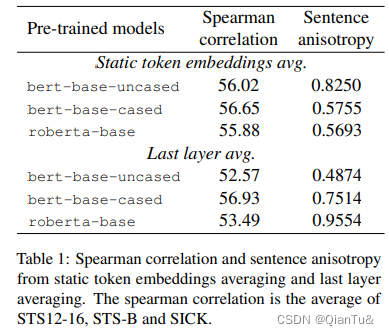
3.2 观察二——Embedding biases harms the sentence embeddings performance
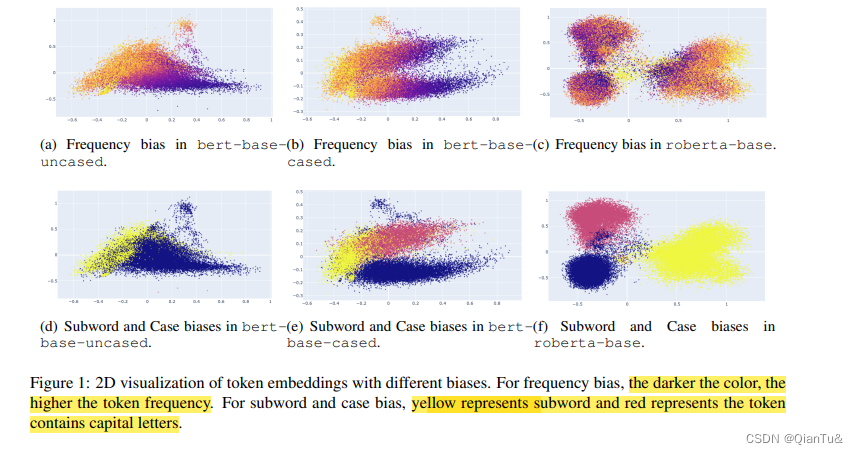
embedding bias不仅包括了token frequency,同时也包括,wordpiece的subwords,case sensitive .(子词和大小写——
对于cased PLM的token embedding大致可以分为3个region: 1 lowercase begin of word tokens 2. the uppercase begin of word tokens 3 the subword tokens .
对于uncased PLM 的token embedding大致可以分为2个region: 1 begin of word tokens 2 the subword tokens
实验结果:对于频率偏差,我们可以观察到高频tokens是聚集的,而低频标记在所有三个模型中都是稀疏分散的(Yan 等人,2021)。 BERT 中的词开头标记比子词标记更容易受到频率的影响(图中怎么看出来的?)。然而,子词标记在 RoBERTa 中更容易受到攻击
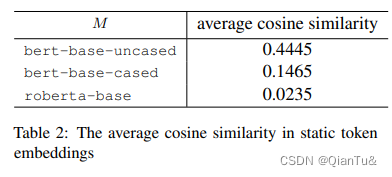
三个预训练模型的静态令牌嵌入各向异性的计算:根据任意两个tokens嵌入之间的余弦相似度的平均值得到的。
实验结果如下,bert-base-uncased具备较强的各向异性。
四、论文中的方法
- how to represent sentences with the prompt, and 2) how to find a proper prompt for sentence embeddings
4.1 sentence representation with prompt
方法一:使用[MASK]的hidden state表示句子。
方法二:使用[mask]得到的top-k的tokens的平均值表示句子。
P表示概率值,Wv表示token的embedding
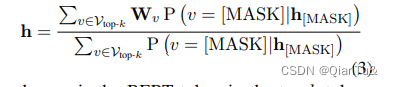
4.2 prompt search
3中方式,mannal search,template search based on T5, OptiPrompt
prompt质量的评测:spearman correlation in the STS-B development set as the main metric to evaluate different templates.
4.3 prompt based denosing
The idea is using the different templates to represent the same sentence as different points of view.
使用不同的template表示同一个句子,得到的句子相似度应该很大,偏差应该很小。
h’和h表示句子x使用不同的模板h’和h^.
训练目标:同一个句子下的embedding的偏差应该尽可能的小。
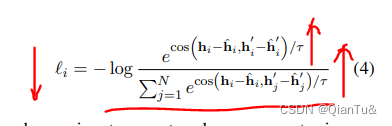

















 1614
1614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











