










1、如何理解神经网络里面的反向传播算法
反向传播算法(Backpropagation)是目前用来训练人工神经网络(Artificial Neural Network,ANN)的最常用且最有效的算法。其主要思想是:
(1)将训练集数据输入到ANN的输入层,经过隐藏层,最后达到输出层并输出结果,这是ANN的前向传播过程;
(2)由于ANN的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层;
(3)在反向传播的过程中,根据误差调整各种参数的值;不断迭代上述过程,直至收敛。
反向传播算法的思想比较容易理解,但具体的公式则要一步步推导,因此本文着重介绍公式的推导过程。
1. 变量定义
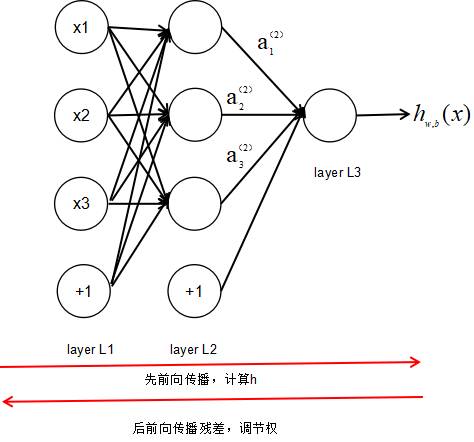
上图是一个三层人工神经网络,layer1至layer3分别是输入层、隐藏层和输出层。如图,先定义一些变量:
表示第层的第个神经元连接到第层的第个神经元的权重;
表示第层的第个神经元的偏置;
表示第层的第个神经元的输入,即:
表示第层的第个神经元的输出,即:
其中表示激活函数。
2. 代价函数
代价函数被用来计算ANN输出值与实际值之间的误差。常用的代价函数是二次代价函数(Quadratic cost function):
其中,表示输入的样本,表示实际的分类,表示预测的输出,表示神经网络的最大层数。
3. 公式及其推导
本节将介绍反向传播算法用到的4个公式,并进行推导。如果不想了解公式推导过程,请直接看第4节的算法步骤。
首先,将第层第个神经元中产生的错误(即实际值与预测值之间的误差)定义为:
本文将以一个输入样本为例进行说明,此时代价函数表示为:
公式1(计算最后一层神经网络产生的错误):
其中,表示Hadamard乘积,用于矩阵或向量之间点对点的乘法运算。公式1的推导过程如下:
公式2(由后往前,计算每一层神经网络产生的错误):
推导过程:
公式3(计算权重的梯度):
推导过程:
公式4(计算偏置的梯度):
推导过程:
4. 反向传播算法伪代码
输入训练集
对于训练集中的每个样本x,设置输入层(Input layer)对应的激活值:
前向传播:
,
计算输出层产生的错误:
反向传播错误:
2、如何理解神经网络里面的反向传播算法
反向传播算法(BP算法)主要是用于最常见的一类神经网络,叫多层前向神经网络,本质可以看作是一个general nonlinear estimator,即输入x_1 ... x_n 输出y,视图找到一个关系 y=f(x_1 ... x_n) (在这里f的实现方式就是神经网络)来近似已知数据。为了得到f中的未知参数的最优估计值,一般会采用最小化误差的准则,而最通常的做法就是梯度下降,到此为止都没问题,把大家困住了很多年的就是多层神经网络无法得到显式表达的梯度下降算法可以参考:一个技术宅的学习笔记!
BP算法实际上是一种近似的最优解决方案,背后的原理仍然是梯度下降,但为了解决上述困难,其方案是将多层转变为一层接一层的优化:只优化一层的参数是可以得到显式梯度下降表达式的;而顺序呢必须反过来才能保证可工作——由输出层开始优化前一层的参数,然后优化再前一层……跑一遍下来,那所有的参数都优化过一次了。但是为什么说是近似最优呢,因为数学上除了很特殊的结构,step-by-step的优化结果并不等于整体优化的结果!不过,好歹现在能工作了,不是吗?至于怎么再改进(已经很多改进成果了),或者采用其他算法(例如智能优化算法等所谓的全局优化算法,就算是没有BP这个近似梯度下降也只是局部最优的优化算法)那就是新的研究课题了。
3、如何理解神经网络里面的反向传播算法
反向传播算法(Backpropagation)是目前用来训练人工神经网络(Artificial Neural Network,ANN)的最常用且最有效的算法。其主要思想是:
(1)将训练集数据输入到ANN的输入层,经过隐藏层,最后达到输出层并输出结果,这是ANN的前向传播过程;
(2)由于ANN的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层;
(3)在反向传播的过程中,根据误差调整各种参数的值;不断迭代上述过程,直至收敛。
反向传播算法的思想比较容易理解,但具体的公式则要一步步推导,因此本文着重介绍公式的推导过程。
1. 变量定义
上图是一个三层人工神经网络,layer1至layer3分别是输入层、隐藏层和输出层。如图,先定义一些变量:
表示第层的第个神经元连接到第层的第个神经元的权重;
表示第层的第个神经元的偏置;
表示第层的第个神经元的输入,即:
表示第层的第个神经元的输出,即:
其中表示激活函数。
4、如何理解神经网络里面的反向传播算法
1.普通的机器学习模型:
其实,基本上所有的基本机器学习模型都可以概括为以下的特征:根据某个函数,将输入计算并输出。图形化表示为下图:
当我们的g(h)为sigmoid函数时候,它就是一个逻辑回归的分类器。当g(h)是一个只能取0或1值的函数时,它就是一个感知机。那么问题来了,这一类模型有明显缺陷:当模型线性不可分的时候,或者所选取得特征不完备(或者不够准确)的时候,上述分类器效果并不是特别喜人。如下例:
我们可以很轻易的用一个感知机模型(感知器算法)来实现一个逻辑与(and),逻辑或(or)和逻辑或取反的感知器模型,(感知器模型算法链接),因为上述三种模型是线性可分的。但是,如果我们用感知器模型取实现一个逻辑非异或(相同为1,不同为0),我们的训练模型的所有输出都会是错误的,该模型线性不可分!
2.神经网络引入:
我们可以构造以下模型:
(其中,A代表逻辑与,B代表逻辑或取反,C代表逻辑或)
上述模型就是一个简单的神经网络,我们通过构造了三个感知器,并将两个感知器的输出作为了另一个感知其的输入,实现了我们想要的逻辑非异或模型,解决了上述的线性不可分问题。那么问题是怎么解决的呢?其实神经网络的实质就是每一层隐藏层(除输入和输出的节点,后面介绍)的生成,都生成了新的特征,新的特征在此生成新的特征,知道最新的特征能很好的表示该模型为止。这样就解决了线性不可分或特征选取不足或不精确等问题的产生。(以前曾介绍过线性不可分的实质就是特征不够)
神经网络的模型结构如下:
(蓝色,红色,黄色分别代表输入层,影藏层,输出层)
在此我们介绍的神经网络中的每一个训练模型用的都是逻辑回归模型即g(h)是sigmoid函数。
我们可以将神经网络表示如下:
3.神经网络的预测结果(hypothesis函数)的计算和CostFunction的计算
预测结果的计算其实与普通的逻辑回归计算没有多大区别。只是有时候需要将某几个逻辑回归的输出作为其他逻辑回归模型的输入罢了,比如上例的输出结果为:
那么CostFunction的计算又和逻辑回归的CostFunction计算有什么区别呢?
逻辑回归的CostFunction如下:
上述式子的本质是将预测结果和实际标注的误差用某一种函数估算,但是我们的神经网络模型有时候输出不止一个,所以,神经网络的误差估算需要将输出层所有的CostFunction相加:
k:代表第几个输出。
补充:神经网络可以解决几分类问题?
理论上,当输出单元只有一个时,可以解决2分类问题,当输出单元为2时可以解决4分类问题,以此类推...
实质上,我们三个输出单元时,可以解决三分类问题([1,0,0],[0,1,0],[0,0,1]),为什么如此设计?暂时留白,以后解决
ps:面试题:一个output机器,15%可能输出1,85%输出0,构造一个新的机器,使0,1输出可能性相同? 答:让output两次输出01代表0,10代表1,其余丢弃
4.神经网络的训练
这儿也同于logistic回归,所谓的训练也就是调整w的权值,让我们再一次把神经网络的CostFunction写出来!
W代表所有层的特征权值,Wij(l)代表第l层的第i个元素与第j个特征的特征权值
m代表样本个数,k代表输出单元个数
hw(x(i))k代表第i个样本在输出层的第k个样本的输出 y(i)k代表第i个样本的第k个输出
然后同于logistic回归,将所有的W更新即可。难处在于此处的偏导数怎么求?首先得说说链式求导法则:
所以我们可以有:
接下来的问题就是有theta了,当我们要求的错误变化率是最后一层(最后一层既是输出层的前一层)且只看一个输出神经元时则:
多个相加即可
那么中间层次的神经元变化率如何求得呢?我们需要研究l层和了+1层之间的关系,如下图:
第l层的第i个Z与第l层的第i个a的关系就是取了一个sigmod函数,然而第l层的第i个a与和其对应的w相乘后在加上其他的节点与其权值的乘积构成了第l+1层的Z,好拗口,好难理解啊,看下式:
大体也就是这么个情况,具体的步骤为:
1.利用前向传播算法,计算出每个神经元的输出
2.对于输出层的每一个输出,计算出其所对应的误差
3.计算出每个神经元的错误变化率即:
4.计算CostFunction的微分,即:
5、如何理解神经网络里面的反向传播算法
就是利用了链式求导法则,从后往前,逐层计算cost关于该层参数的梯度。详细的退到可参见:
6、循环神经网络的反向传播
可以采用MATLAB软件中的神经网络工具箱来实现BP神经网络算法。BP神经网络的学习过程由前向计算过程、误差计算和误差反向传播过程组成。双含隐层BP神经网络的MATLAB程序,由输入部分、计算部分、输出部分组成,其中输入部分包括网络参数与训练样本数据的输入、初始化权系、求输入输出模式各分量的平均值及标准差并作相应数据预处理、读入测试集样本数据并作相应数据预处理;计算部分包括正向计算、反向传播、计算各层权矩阵的增量、自适应和动量项修改各层权矩阵;输出部分包括显示网络最终状态及计算值与期望值之间的相对误差、输出测试集相应结果、显示训练,测试误差曲线。















 3932
3932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









