







Largest Rectangle in a Histogram
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submission(s): 17068 Accepted Submission(s): 5060
Problem Description
A histogram is a polygon composed of a sequence of rectangles aligned at a common base line. The rectangles have equal widths but may have different heights. For example, the figure on the left shows the histogram that consists of rectangles with the heights 2, 1, 4, 5, 1, 3, 3, measured in units where 1 is the width of the rectangles:
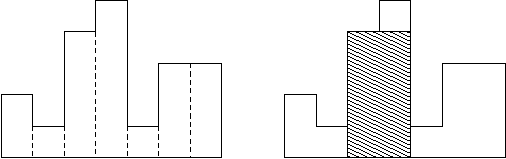
Usually, histograms are used to represent discrete distributions, e.g., the frequencies of characters in texts. Note that the order of the rectangles, i.e., their heights, is important. Calculate the area of the largest rectangle in a histogram that is aligned at the common base line, too. The figure on the right shows the largest aligned rectangle for the depicted histogram.
Usually, histograms are used to represent discrete distributions, e.g., the frequencies of characters in texts. Note that the order of the rectangles, i.e., their heights, is important. Calculate the area of the largest rectangle in a histogram that is aligned at the common base line, too. The figure on the right shows the largest aligned rectangle for the depicted histogram.
Input
The input contains several test cases. Each test case describes a histogram and starts with an integer n, denoting the number of rectangles it is composed of. You may assume that 1 <= n <= 100000. Then follow n integers h1, ..., hn, where 0 <= hi <= 1000000000. These numbers denote the heights of the rectangles of the histogram in left-to-right order. The width of each rectangle is 1. A zero follows the input for the last test case.
Output
For each test case output on a single line the area of the largest rectangle in the specified histogram. Remember that this rectangle must be aligned at the common base line.
Sample Input
7 2 1 4 5 1 3 3 4 1000 1000 1000 1000 0
Sample Output
8 4000
补一下之前写的dp题目吧,也算是总结下,提醒自己。
这题的题意就是找到最大的矩阵面积。
如果时间够的话,暴力很好想,枚举每个点,找到这个点的左边比它大的最左边的位置l,找到这个点的右边比它大的最右边的位置r,这样的话,就能通过(r-l+1)*n,n表示该点的高度,即可。但这里暴力肯定是不行的,于是我们想想优化,每个点肯定是要枚举的,我们就在找每个点的最值上面做文章了。
我们首先考虑,找每个点最左边比它大的位置,如果一个点的坐标为i,且它比i-1位置的值还要大,我们则可以不用找了,为什么呢?因为既然i-1已经比它小了,则高度肯定就是它自己的高度了,如果i-1比它的值大,则我们可以直接找到i-1位置的最左边比它大的位置,用i位置与这个位置比一下,即可。所以可以列出状态转移:
if(dp[l[i]-1]>=dp[i]) l[i]=l[l[i]-1] 即可,由于我们需要在找左边的时候,需要知道左边所有点的状态,所以我们从左至右推一下即可。找右边极值时与之相反。
OK,转化成这样,答案就显而易见了,预处理一下每个点最左边比它大的位置,每个点最右边比它大的位置,就可以了。(有个地方要记住,就是dp[0]和dp[n+1]要小于0,否则会RE,虽然不知道我没写之前为何是TE)
贴上我的AC代码:
#include<cstdio>
#include<cstdlib>
#include<iostream>
#include<stack>
#include<queue>
#include<algorithm>
#include<string>
#include<cstring>
#include<cmath>
#include<vector>
#include<map>
#include<set>
#define eps 1e-8
#define zero(x) (((x>0?(x):-(x))-eps)
#define mem(a,b) memset(a,b,sizeof(a))
#define memmax(a) memset(a,0x3f,sizeof(a))
#define pfn printf("\n")
#define ll __int64
#define ull unsigned long long
#define sf(a) scanf("%d",&a)
#define sf64(a) scanf("%I64d",&a)
#define sf264(a,b) scanf("%I64d%I64d",&a,&b)
#define sf364(a,b,c) scanf("%I64d%I64d%I64d",&a,&b,&c)
#define sf2(a,b) scanf("%d%d",&a,&b)
#define sf3(a,b,c) scanf("%d%d%d",&a,&b,&c)
#define sf4(a,b,c,d) scanf("%d%d%d%d",&a,&b,&c,&d)
#define sff(a) scanf("%f",&a)
#define sfs(a) scanf("%s",a)
#define sfs2(a,b) scanf("%s%s",a,b)
#define sfs3(a,b,c) scanf("%s%s%s",a,b,c)
#define sfd(a) scanf("%lf",&a)
#define sfd2(a,b) scanf("%lf%lf",&a,&b)
#define sfd3(a,b,c) scanf("%lf%lf%lf",&a,&b,&c)
#define sfd4(a,b,c,d) scanf("%lf%lf%lf%lf",&a,&b,&c,&d)
#define sfc(a) scanf("%c",&a)
#define ull unsigned long long
#define pp pair<int,int>
#define debug printf("***\n")
const double PI = acos(-1.0);
const double e = exp(1.0);
const int INF = 0x7fffffff;;
template<class T> T gcd(T a, T b) { return b ? gcd(b, a % b) : a; }
template<class T> T lcm(T a, T b) { return a / gcd(a, b) * b; }
template<class T> inline T Min(T a, T b) { return a < b ? a : b; }
template<class T> inline T Max(T a, T b) { return a > b ? a : b; }
bool cmpbig(int a, int b){ return a>b; }
bool cmpsmall(int a, int b){ return a<b; }
using namespace std;
#define MAX 100010
ll dp[MAX];
ll l[MAX];
ll r[MAX];
int main()
{
// freopen("data.in","r",stdin);
int n;
while(~sf(n)&&n)
{
mem(dp,0);
mem(l,0);
mem(r,0);
int i;
dp[0]=dp[n+1]=-1;
for(i=1;i<=n;i++)
{
sf64(dp[i]);
l[i]=r[i]=i;
}
for(i=1;i<=n;i++)
{
while(dp[l[i]-1]>=dp[i])
l[i]=l[l[i]-1];
}
for(i=n;i>=1;i--)
{
while(dp[r[i]+1]>=dp[i])
r[i]=r[r[i]+1];
}
ll max_num=0;
for(i=1;i<=n;i++)
{
max_num=max(max_num,(r[i]-l[i]+1)*dp[i]);
}
printf("%I64d\n",max_num);
}
return 0;
}















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









