










论文标题:Expression Flow for 3D-Aware Face Component Transfer
摘要:用于3D感知的面部组件传输的表达流程

图1:将建议的表达流程应用于人脸成分转移的示例。 (a)和(b)是输入图像,用户想要用(b)中的张开嘴代替(a)中的闭合嘴。 (C)系统产生的表情流,使(a)中的整个脸部变形以适应新的嘴形。顶部:水平流场,底部:垂直流场。 (d)我们的系统生成的最终复合材料。(e)使用2D对齐和混合生成的合成。注意嘴和下巴之间不自然的短距离。
摘要:
- 我们解决了通过从具有期望表情的同一个人的另一张脸部照片上转移局部面部成分(例如笑脸)来校正脸部照片上的不良表情的问题。使用现有的合成工具直接复制和混合会导致语义上不自然的合成,因为表情是一种整体效果,而一个表情中的局部成分通常与另一表情中脸部的形状和其他成分不兼容。为了解决这个问题,我们
提出了一种表达流,它是一种二维流场,可以自然地全局扭曲目标脸,从而使扭曲的脸与要复制的新脸部组件兼容。为此,从输入的两个面部照片开始,我们共同构造一对具有相同标识但不同表情的3Dface形状。通过将两个3D形状之间的差异投影回2D来计算表达流。它描述了如何使目标脸部照片变形以匹配参考照片的表情。用户研究表明,我们的系统能够生成比现有方法高得多的保真度的人脸合成。【解决的问题就是矫正照片中的不良表情,借助同一个人的好的表情替换脸部的局部组件】
关键词:面部表情,面部成分,面部造型,面部流动,图像变形
引言
- 每个有为家人和朋友照相的经验的人都知道捕捉完美时刻有多么困难。首先,相机可能在正确的时间没有处于正确的设置。此外,在取景器中看到完美微笑的时间与实际拍摄图像的时间之间总是存在延迟,特别是对于响应速度较慢的低端手机相机而言。由于这些原因,由业余摄影师捕获的面部图像通常包含各种缺陷。一般来说,瑕疵有两种类型。第一种是由于相机设置不当而导致的光度缺陷,因此面部可能显得太暗,粒状或模糊。第二种类型通常更明显,更严重,是对象的不良表情,例如闭眼,半张嘴等。随着图像编辑的最新进展,可以使用现代的后处理工具极大地改善光度缺陷。例如,个人照片增强系统[Joshi等。【合照中每个人的表情不一定是完美的,需要编辑 】
- [2010年]提供了一组调整工具来校正脸部的整体属性,例如颜色,曝光度和清晰度。与光度缺陷相比,表情伪像更难纠正。给定一张不带笑脸的照片,一个人可以简单地从他/她的个人相册中找到同一个人的微笑照片,并使用现有方法将其替换为整个脸部[Bitouk et al.2008]。不幸的是,这种全局交换也替换了用户可能想要保留的面部其他部分。因此,有时更优选在面部图像之间进行局部分量传输。【表情更难调整,以前的方法是交换整个脸部,但是用户如果想保留其余组件,只是想交换部分组件,那就需要局部组件传输】
- 然而,具有不同表情的面部图像之间的局部成分转移是一项非常具有挑战性的任务。在面部表情文献[Faigin 1991]中众所周知,
情绪表情会同时涉及面部的信号密集区域:眼睛区域和嘴巴区域。为了使情感表达真实,两个区域都必须显示出可见且协调的活动模式。真诚的笑容尤为如此,真诚的笑容以其宽阔的形式几乎改变了从下眼睑到脸部下边缘的所有面部形貌。而一般的图像合成工具[Agarwala等。 [2004年]允许用户裁剪一个面部区域并将其无缝混合到另一张面部中,它们无法改善复制的复合图像的兼容性。物体和目标脸,如图1所示。用图1b中的张开嘴代替图1a中的闭合嘴,一个简单的解决方案是裁剪嘴部区域,应用附加的对齐调整并将其无缝地混合到目标脸。但是,最终的合成在语义上是非常不自然的(图1e)。这是因为,当张开嘴时,脸的整个下半部分的形状相应地变形。据您所知,没有现有的工具可以自动处理这些变形以创建逼真的面部合成物。【以前调整局部的方法就是简单的裁剪,但是面部表情会同时涉及面部的其他区域,所以简单裁剪替换后的效果很差。】 - 我们通过呈现Expression Flow来解决此问题,Expression Flow是应用于目标图像的2D流场,用于使面部变形,使其与要复制的面部组件兼容。为了计算表达流,我们首先使用其他人的脸部形状数据集为每个图像重建3D脸部形状,与传统的3D拟合尝试将每个图像的拟合误差最小化的方法不同,我们共同重建一对具有相同形状的3D形状身份,但具有与我们的输入图像对匹配的不同表达式。这被表述为一个优化问题,其目的是通过人的身份约束最小化拟合误差。然后从一对对齐的3D形状中计算出3D流,并将其投影到2D以形成2D表达式流。形状还用于在混合之前扭曲新组件的3D姿势。由于身份约束,表情流主要反映了表情差异引起的变化,并且可以自然地变形脸部,如图1d所示。【提出解决办法】
- 我们的表达流程是3D和2D方法的混合体。一方面,我们依靠粗糙的3D形状来计算具有不同姿势的面孔之间的表情差异。由于典型的表达式流包含的细节(频率)级别比典型的外观细节低得多,因此我们发现,粗略的3D重构足以满足表达式传递的目的。另一方面,我们依靠2D方法使人脸图像变形并在它们之间传递局部细节。因此,与以前的3D和2D表情传递方法(请参阅第2部分)相比,我们的系统具有更大的灵活性和更广泛的应用范围。【我们的方法很好】
- 基于提出的表情流程,我们开发了一种有效的面部合成工具。为了评估该系统的有效性和通用性,我们进行了全面的用户研究。结果表明,由我们的系统创建的面部合成具有比以前的方法生成的那些具有更高的保真度。【我们的方法很好】
相关工作
- 我们的工作与先前有关面部编辑,面部表情贴图,面部对齐,3D形状拟合和图像合成的研究有关。
- 面部图像编辑。面部图像增强已成为广泛工作的主题。较早的方法将通用的人脸图像用作训练数据,用于诸如超分辨率[Liu等人2007]和通过全局人脸变形提高吸引力[Ley-vand等人2007]的训练数据。 2008]。最近乔希等。 [2010]提出了一种系统来使用个人先验调整全局属性,例如面部图像的色调,清晰度和亮度。布兰兹等。 [2004]将变形的3D模型拟合到面部图像,然后使用相同的姿势和照明替换新的面部来渲染它。人脸交换系统[Bitouk等。 [2008]通过构建和使用大型面部图像库实现了类似的目标。一种基于表情和姿势相似性的实时检索和替换人脸照片的系统在[Shlizerman et al。 2010]。所有这些系统都针对全局人脸编辑。但是,个人照片编辑通常不希望替换整个头部或面部,全局变形无法处理较大的拓扑和外观变化,并且生成逼真的纹理头部模型并将其组合到现有照片中仍然是一个难题。我们的方法结合了全局变形和脸部局部局部合成,以进行有效的示例式表情编辑。 【以前的方法都是针对全局人脸编辑的,我们提出局部编辑方式】
- 表情映射:在图像之间传递表达式方面也有大量工作,分为两类:3D方法和2D方法。 3D方法,例如Pighin等人提出的表情合成系统。 (1998年)和Blanz等人提出的面部修复系统。 [2003],请尝试根据照片或视频创建逼真的带纹理的3D面部模型。一旦构建了这些模型,就可以将它们用于表达式插值。但是,创建完全纹理化的3D模型并非易事。为了实现照片逼真,该系统必须准确地建模所有面部组件,例如眼睛,牙齿,耳朵和头发,这在计算上是昂贵且不稳定的。因此,这些系统只能与在受控的室内环境中拍摄的高分辨率面部图像一起使用,并且与我们的系统不同,它们不够坚固,无法用于日常的个人面部照片。【构建3D模型很难】
- 2D表情映射方法[Williams 1990]
从具有不同表情的两幅图像中提取面部特征,计算特征差异向量,并使用它们指导图像变形。Liuet al。 [2001]提出了一种表情比率图像,可以同时捕捉几何变化和表情细节,例如皱纹。但是,由于缺乏3D信息,这些方法无法从不同角度处理人脸。最重要的是,仅这些方法就无法合成原始图像中没有的特征,例如张开嘴巴。【2D表情迁移有缺点】 - 面部特征定位。已经提出了各种技术来在图像以及视频中进行面部特征定位[Decarlo and Metaxas 2000]。它们中的大多数将局部特征检测器与全局几何约束结合在一起。广泛使用的主动形状模型[Cootes等。 [1995]学习了特征点的统计分布,从而允许形状仅在训练集中看到的内部变化。主动外观模型[Cooteset等。 [2001]探索图像强度分布以约束脸部形状。图形结构方法[Felzenszwalb和Hut-tenlocher 2005]通过最大化外观和形状的后验概率来定位特征。在该领域的最新工作还包括基于成分的判别搜索[Liang等,2008],以及子空间约束的均值平移方法[Saragihet等。 2009]。【不懂】
- 3D形状拟合。从单个图像中恢复3D面部形状是许多基于3D的面部处理系统的关键组成部分。Blanz和Vetter [1999]通过梯度下降优化3D可变形模型的参数以渲染图像。尽可能接近输入图像。 Romdhani和Vetter [2003]将逆合成图像对齐算法扩展到3Dmorphable模型。从阴影中提取形状的方法也适用于3D人脸重建[Dovgard and Basri 2004; Shlizer-man和Basri,2011年]。 Kemelmacher-Shlizerman等。 [2010]展示了如何找到不同姿势下表情的相似性,以及如何使用3D感知的面部特征翘曲来弥补姿势差异。【3D方法】
- 图像合成。一般的图像合成工具,例如,蒙太奇系统[Agarwala等。 2004]和即时克隆系统[Farbman等。 2009]通过Pois-son混合[Ṕerezet al。 [2003]或使用重心坐标。Sunkavalli等。 [2010]提出了一种协调技术,可以创建更多的天然复合材料。

3、我们的系统
3.1 系统概述
- 图2显示了系统的流程图。给定用户想要改善的目标面部图像和包含要复制的所需特征的参考图像,我们的系统首先使用计算机视觉技术
自动在两个图像上提取面部特征点。基于提取的特征点,我们然后使用3D人脸表情数据集为两个图像共同重建3D人脸形状。我们的3D拟合算法可确保两个形状具有相同的标识,因此它们之间的主要区别是由于表情的变化。然后,我们通过减去两个形状来计算3D流并将其投影到2D以创建表情流。表情流程用于扭曲目标面部。我们还使用3D形状将参考面与目标面3D对齐。然后,用户指定要转移的面部特征的区域,然后将其无缝融合到目标图像中以创建最终的合成图像。【1、提取特征点;2、创建3D人脸形状;3、创建表情流;4、对齐;5、融合】
3.2单幅图像拟合 - 我们首先描述如何将3D脸部形状拟合为单幅脸部图像。根据输入图像,首先使用Active Shape Model(ASM)对脸部界标进行局部化[Cootes等。 1995],一种可靠的面部特征定位方法。按照Milborrow和Nicolls [2008]的方法,我们定位了68个特征点,如图2所示。
- 我们用形状矢量=(x1,y1,z1,···,xn, yn,zn)包含其顶点的X,Y,Z坐标。根据Blanz和Vetter的工作[1999],我们在训练数据集上使用主成分分析(PCA)定义了可变形的面部模型。将特征向量asvi,特征值表示为λi并将平均形状表示为̄s,可以从PCA模型生成新形状为:
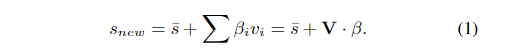
- 通过改变系数β来执行3D拟合,以最小化在3D面部几何形状上的预定地标的投影与由ASM检测到的2D特征点之间的误差。我们应用弱透视投影模型,并将第k个地标的拟合能量定义为:
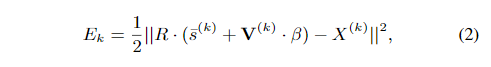


图3:使用我们的两阶段优化算法将3D形状拟合到图2中的目标图像。左:形状如何变形。绿线是ASM要素线,粉红色线是根据脸部几何图形投射的脸部轮廓。红色短线表示投影到面部轮廓上的轮廓界标。右:3次迭代后的脸部形状
3、3表情模型

- 为了训练PCA模型,我们使用Vlasic等人提出的面部表情数据集。 [2005]。该数据集包含16个主题,每个主题以5种不同的表达方式执行5个视位素。此数据集已预先对齐,以使形状具有顶点到顶点的对应关系。
- 使用所有训练形状构建单个PCA模型是有问题的,因为训练形状在身份和表达上都不同,单个PCA可能不是表达能力足以捕获两种类型的变化(拟合不足),并且也不允许在两者之间进行区分。因此,我们分别为每个表情构建了PCA模型。我们还可以使用更复杂的非线性方法(例如流形[Wang et al。2004])。但是,由于该脸部形状变化不大,因此我们发现这种近似可提供理想的结果。



计算2D流 - 我们首先对齐两个3D形状以消除姿势差异。由于重建的3D形状具有明确的顶点到顶点对应关系,我们可以计算两个对齐的3D形状之间的3D差异流并将其投影到图像平面上以创建2D表达式流。流量进一步平滑以消除噪音。最终表达流程的示例如图4所示。图4a显示了水平流程,其中红色表示X方向上的正向移动(向右),蓝色表示X方向上的负向移动(向左)。这个数字从本质上描述了当人微笑时嘴如何张大。图4b显示了垂直流,其中红色表示沿Y轴正向运动(向下移动),蓝色表示负向运动(向上移动)。它说明当人微笑时,她的下巴变低,脸颊抬起。

图2中所示的示例计算得出的4:2D表达式流。(a)水平流场。 (b)垂直流场
- 如图2所示,通过将表达式流程应用于目标脸部,我们可以使目标脸部变形以具有兼容的形状,以获得更大的微笑。类似地,基于两个形状的3D对齐,我们可以为参考模型计算3D旋转,然后将其投影到图像平面以形成2D对齐流场,我们将其称为对齐流。使用对齐流程,可以将参考面变形为与目标面相同的姿势(参见图2)。

5:自动裁剪区域生成。 (a)目标图像。 (b)变形目标。 (C)参考图片。 (d)扭曲的参考。 (e)用户点击口腔区域(标记为蓝色)以指定要替换的区域。我们的系统会自动生成显示为黄色的作物区域。 (f)泊松混合后的最终复合结果。
3.6 2D合成
- 在将两个输入的面部图像变形为所需的表情和姿势之后,我们的系统提供了一组编辑工具来帮助用户生成高质量的合成图像。如图5所示,我们的系统采用了交互式特征选择工具,该工具允许用户单击面部特征以生成最适合混合的裁剪区域。这是通过采用类似于数字照片蒙太奇系统中提出的图形切割图像分割工具来完成的[Agarwala等。 2004]。具体来说,我们的图形切割公式中的数据项鼓励用户选择的像素周围的高梯度区域包含在作物区域中。对于pixelp,将其包含在裁剪区域中的可能性定义为:【允许通过单击图像中的区域自定义选择编辑区域】

4、用户辅助
- 我们系统的计算机视觉组件不能在所有情况下都能完美运行。对于困难的例子,我们的系统要求少量的用户帮助,以生成高质量的结果。需要用户干预的主要步骤是使用
ASM和作物区域规范进行2D对齐。【对于复杂情况需要用户手动辅助】

图 6:用户协助模式。 (a)具有自动提取的地标的参考图像。错误以蓝色箭头突出显示。 (b)手动更正后的地标位置。 (c)目标图像 (d)自动计算的裁剪区域(黄色),并带有用户校正(红色)以添加微笑褶皱。 (e)没有笑脸的合成图像。 (f)带有微笑褶皱的合成图像
图7:用户研究结果,比较原始图像,我们的结果和2D结果。垂直轴是用户对特定类别进行投票的次数

- 我们的ASM实现有时无法为旋转角度较大的侧面生成准确的2D对齐结果,这是一个已知的硬计算机视觉问题。图6a中显示了一个示例,其中一些自动计算的地标不准确,尤其是对于嘴巴和左眼区域。然后使用这些界标进行3D拟合是错误的。在我们的系统中,我们允许用户手动校正不良的界标,从而可以实现准确的3D拟合,如图6b所示。【自动计算地标不正确,允许用户手动矫正】
- 3.6节中描述的作物区域生成工具允许用户快速指定选择蒙版。但是,这种方法有时无法捕获用户想要转移的细微语义表达细节。这样的例子在图6d中示出,其中自动生成的裁剪区域错过了对象的独特笑容褶皱。用户可以将微笑褶皱手动添加到裁剪区域中,从而得到更自然的复合材料,如图6f所示。【用户指定编辑区域时,有时无法捕获细微的语义细节。需要手动操作】
5、结果和评估
5、1 用户研究
- 为了定量和客观地评估我们的系统,我们使用Amazon Mechanical Turk(AMT)进行了用户研究。我们的评估数据集包含14个示例,每个示例包含四个图像:两个原始图像,由我们的系统生成的结果以及由2D方法生成的结果。 2D方法首先仅使用面部区域内的像素,在两个面部之间应用Lucas-Kanade图像配准[Lucas and Kanade 1981],使用检测到的基准点进行初始化,然后使用系统的其余部分创建最终的合成图像。这类似于最先进的局部面部成分转移方法,例如照片蒙太奇系统[Agarwala等。 2004]和Photoshop Elements中的面部替换功能。这些例子涵盖了从小到大的不同年龄段,以及不同的种族群体,包括男人和女人。对于每个用户和每个示例,随机选择三个图像中的两个(原始,我们的结果和2D结果)以并排显示,并要求用户选择看起来更自然的一个。 50个不同的用户,因此将每个结果与原始结果进行比较,另一个结果均重复50次。用户平均花费15秒来评估每对。
- 图7显示了用户研究结果。如我们所见,原始图像通常被评为最自然。这并不奇怪,因为人类对面部的半点瑕疵非常敏感,而且我们不希望我们的结果比自然的面部图像更真实。但是,令人惊讶的是,在示例6、7和13中,我们的结果实际上被评为高于原始结果。我们相信,这是因为我们在这些示例中得到的结果几乎达到了与原件相同的保真度,并且用户基本上在评估他们没有看到明显伪像时哪张脸具有更令人愉悦的表情(请参见图8中的示例7)。【我们的结果很好,甚至优于原始图像】
- 如数据所示,我们的方法在2D结果方面一直受到用户的一致好评,但
示例10(它是眼睛替换示例)除外(图8中的最后一列)。这表明,当两个脸部的姿势大致相同时,有时2D方法足以替代眼睛,因为脸部的上半部更加僵硬,并且睁开或闭上眼睛可能不会对脸部造成任何重大的整体变化。在这种情况下,表情流基本没用。 - 用户案例中使用的一些示例如图1,图5,图6和图8所示。所有其他示例都包含在补充材料中,可从以下网址下载:http://juew.org/projects/expressionflow.htm。
- 为了进一步评估建议的表达式流的有效性,我们进行了另一项用户研究,在该研究中,我们仅将结果与通过禁用目标图像上的表达式流生成的结果进行比较。由于仍会应用3D对齐,因此这些结果比2D结果更自然。我们选择了6个示例,在这些示例中,我们的方法的明显优于2D方法,并在AMT上进行了第二轮比较。每个对由100位用户进行评估。结果如图9所示。这项研究清楚地表明,使用表达流程时,用户始终偏爱结果。

图 8:用户研究中使用的示例7、13、11、10。对于每个示例,第一行:目标图像(左)以及在被表情流扭曲后的图像(右);第二行:参考图像(左),并在对齐流程扭曲后(右);第三行:我们的结果; 最后一行:2D结果
5.2 与通用人脸建模器的比较
- 现有的通用面部建模器可以从输入图像构建3Dface模型。有人可能想知道是否可以将它们应用于构建用于计算表达式流的3D模型,而不是使用3.4节中提出的3D拟合方法。为了验证这一想法,我们应用了两种单图像3D拟合方法,即流行的FaceGen Modeller [Singular Inversions Inc. 2009]和本文提出的Al-gorithm 1方法分别应用于示例中的每个面,如图10所示。请注意,使用单一图像拟合计算出的差异流会严重扭曲人脸,并且最终合成效果远比我们的图1和8中所示的结果差。这是因为单一图像拟合方法会改变所有可能的内部参数,从而最适合3D模型因此,两个3D模型不仅包含表情差异,还包含身份差异。使用此差异流扭曲面部会导致明显的伪影。
- 在图10d中,我们还通过在[Bitouket等人的面部替换系统的启发下,]用我们的系统生成的3D校正参考面部替换了整个目标面部,从而显示了比较结果。 2008]。注意下例中头发区域周围的各种伪影,因为全脸置换无法正确处理遮挡,上例中的注视方向发生了变化,这表明全脸合成并不总是可靠的,也不总是很理想。在许多情况下,最好使用本地组件传输。【全脸替换无法正确处理遮挡,所以建议局部替换】
总结和未来工作
- 在本文中,我们解决了在具有不同人物表情的人脸图像之间转移局部人脸成分的问题。为了解决表情差异,我们提出了一种新颖的表情流,即一种二维流场,它可以自然变形目标面,从而使变形后的脸与要混合的新组件兼容。表情流是根据新型关节3D计算得出的拟合方法,可以从两个输入图像中共同重建3D人脸形状,从而使它们之间的身份差异最小,并且仅存在表达差异。进行了全面的用户研究以证明我们系统的有效性。
- 目前,我们的系统依靠用户提供参考图像来改善目标图像。将来,我们计划开发一种参考图像搜索工具,该工具可以在对象的个人相册中自动识别出良好的参考图像以使用给定的目标图像。这将大大提高个人面部编辑工作流程的效率。
- 我们的系统目前使用由Vlasic等人收集的面部表情数据集。 [2005]。虽然我们在本文中证明了我们的系统可以在各种不同种族,年龄和性别的人上可靠地工作,但我们也意识到数据集不够丰富,无法处理所有可能的表达式,尤其是不对称表达式。在未来的工作中,我们计划使用现有的3D人脸捕获方法[Zhang等。 2004; Wang等。 [2004年]捕获更多数据以丰富我们的数据集,并探讨它是否可以提高系统的性能。
- 正如一些用户研究对象所指出的那样,我们的一些结果仍然包含较小但值得注意的光度学伪像。例如,一些受试者指出实施例14,图8中所示的口腔区域是粒状的。虽然修复这些混合伪影不是本文的重点,但我们计划采用更高级的协调方法[Sunkavalli等。 2010]进入我们的系统,以进一步提高最终结果的质量。















 1246
1246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









