







目录
前言
这里的“学习”是指从训练数据中自动获取最优权重参数的过程。学习的目的就是以损失函数为基准,找出能使它的值达到最小的权重参数。为了找出尽可能小的损失函数的值,本节我们利用函数斜率的梯度法。
一、损失函数
1. 神经网络以某个指标为线索寻找最优权重参数,该指标称为损失函数,一般用均方误差和交叉熵误差等。
2. 损失函数是表示神经网络性能的“恶劣程度”指标,即当前的神经网络对监督数据在多大程度上不拟合。
1. 均方误差
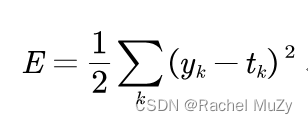
式中,yk表示神经网络的输出,tk表示监督数据,k表示数据的维数。
代码实现:
import numpy as np
def MSE(y, t):
square = (y - t) * (y - t)
E = 0.5 * np.sum(square, axis = 1)
return E
y = np.array([[0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0], [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]])
t = np.array([[0, 0, 1, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]])
output = MSE(y, t)
print(output)结果:

2. 交叉熵误差
公式如下所示:
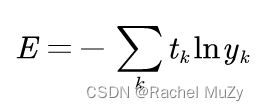
式中,log表示以为底数的自然对数,yk是神经网络的输出,tk是正确解的标签。并且tk中只有正确解标签的索引为1,其他均为0。
代码实现:
import numpy as np
def cross_entropy_error(y, t):
delta = 1e-7
E = -np.sum(t * np.log(y + delta), axis = 1)
return E
y = np.array([[0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0], [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]])
t = np.array([[0, 0, 1, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]])
output = cross_entropy_error(y, t)
print(output)结果:

3. mini-batch学习
计算损失函数时必须将所有的训练数据作为对象。也就是说,如果训练数据有100个的话,就要把100个损失函数的总和作为学习的指标
前面介绍的损失函数的例子中考虑的都是针对单个数据的损失函数。如果要求所有训练数据的损失函数的综合,则要写成下式:
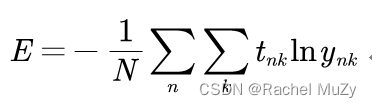
代码实现:
import numpy as np
def dimension(y):
line = len(y)
return line
def cross_entropy_error(y, t, line):
delta = 1e-7
E_pro = np.sum(t * np.log(y + delta), axis = 1)
E = -np.sum(E_pro, axis = 0) / line
return E
y = np.array([[0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0], [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]])
t = np.array([[0, 0, 1, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]])
line = dimension(y)
output = cross_entropy_error(y, t, line)
print(output)结果:

4. mini-batch版交叉熵误差的实现
下面我实现一个可以同时处理单个数据和批量数据(数据作为batch集中输入)两种情况的函数:
(1)t 为one-hot形式的交叉熵误差
import numpy as np
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size
y = np.array([[0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0], [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]])
t = np.array([[0, 0, 1, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]])
output = cross_entropy_error(y, t)
print(output)结果:

分析:
(1)由于one-hot表示中t为0的元素的交叉熵误差也为0,因此针对这些元素的计算可以忽略。换言之,如果可以获得神经网络在正确解标签处的输出,就可以计算交叉熵误差。因此t为one-hot表示时通过t * np.log(y)计算。
(2)ndim
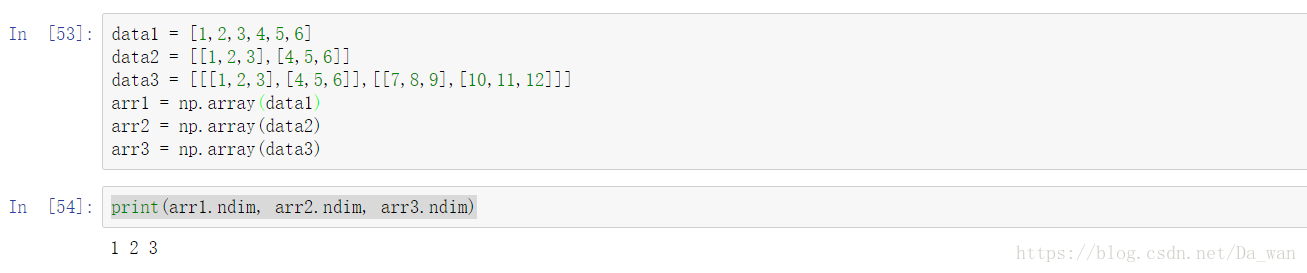
ndim返回的是数组的维度,返回的只有一个数,该数即表示数组的维度。
(3)shape
shape:表示各位维度大小的元组。返回的是一个元组。

对于一维数组:有疑问的是为什么不是(1,6),因为arr1.ndim维度为1,元组内只返回一个数。
对于二维数组:前面的是行,后面的是列,他的ndim为2,所以返回两个数。
对于三维数组:很难看出,下面打印arr3,看下它是什么结构。

先看最外面的中括号,包含[[1,2,3],[4,5,6]]和[[7,8,9],[10,11,12]],假设他们为数组A、B,就得到[A,B],如果A、B仅仅是一个数字,他的ndim就是2,这就是第一个数。但是A、B是(2,3)的数组。所以结合起来,这就是arr3的shape,为(2,2,3)。
(2)t 为非one-hot形式的交叉熵误差
import numpy as np
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7) / batch_size在 t 为标签形式时,可用 np.log(y[np.arange(batch_size), t ])实现相同的处理。np.array(batch_size) 会生成一个从0到batch_size -1的数组。因为 t 中的标签是以 [2, 7, 0, 9, 4]的形式储存的,所以y[np.arange(batch_size), t ]能抽出各个数据的正确解标签对应的神经网络的输出。
5. 为何要设定损失函数
在进行神经网络学习时,不能将识别精度作为指标。因为如果以识别精度作为指标,则参数的导数在绝大多数地方都会变成0,权重参数不会更新。
二、数值微分
(1)梯度法使用梯度的信息决定前进的方向,下一节将介绍梯度是什么、有什么性质等内容。本节先介绍导数。
(2)利用微小的差分求导的过程称为数值微分,下面举一个数值微分的例子
对下式进行求导:
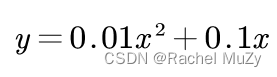
代码实现:
from sympy import diff
from sympy import symbols
import numpy as np
import matplotlib.pylab as plt
def function_1(x):
y = 0.01 * x ** 2 + 0.1 * x
return y
x = np.arange(0.0, 20.0, 0.1)
y1 = function_1(x)
plt.plot(x, y1)
plt.show()
x = symbols("x")
d = diff(function_1(x),x)
y2 = np.array(d)
plt.plot(x, y2)
plt.show代码没跑通,后面再研究。
总结
下一节我将学习偏导数、梯度等实质性的东西,导数的实现有点问题,目前只能停在这里。
















 1665
1665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











