







引言:dify 与 ragflow
一般来说,如果需要处理特别复杂的文档和非结构化数据,RAGFlow 是优选。而对于需要多模型协作和复杂业务流程的场景,Dify 更为适合。
但这并非是个,非此即彼的问题。
如何将 Dify 作为主框架使用其 agent 和工作流组件,同时通过 API 调用 RAGFlow 的知识库组件。从而将 Dify 的用户友好界面和工作流能力与 RAGFlow 的深度文档处理能力结合起来。
注:除了 Dify+RAGFlow 的组合外,也可以结合具体业务场景选择添加更多开源框架,如 LlamaIndex、LigthtRAG 等。
A: 本文是关于Dify 使用外部知识库对接 RAGflow,那 为什么要 RAGflow 和 Dify 结合呢?
Q: 是因为 RAGflow 可以解决 Dify 在RAG 和 知识库解析和检索短板。
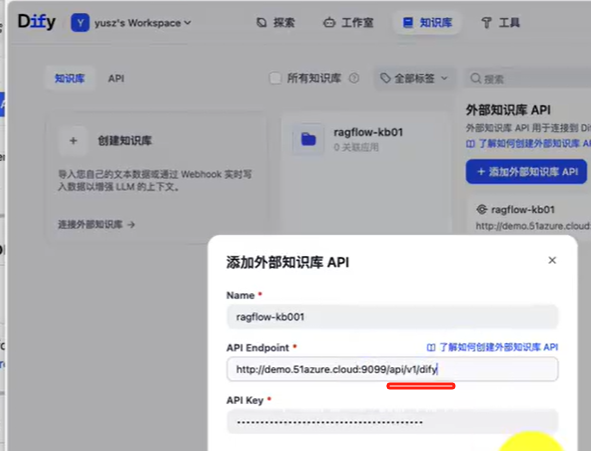
方式一:使用ragflow API 直接连接外部知识库
对接api时,必须的后缀 /v1/dify
1 Ragflow 部分
1-1. 创建 RAGflow 知识库
输入网址:http://192.168.21.24:8880 打开ragflow界面,填入注册的账号和密码登录。然后创建供Dify调用的知识库。
参考:https://blog.csdn.net/nalanxiaoxiao2011/article/details/146986967?spm=1011.2415.3001.5331
1-2. ragflow API 设置
我们接下来是需要dify调用这个ragflow ,所以我们需要设置一下ragflow api key.
1-2-1. 点击系统右上角头像,选择 API, 显示ragflow 对外提供的IP. 我的显示是 http://192.168.xx.xx:8880
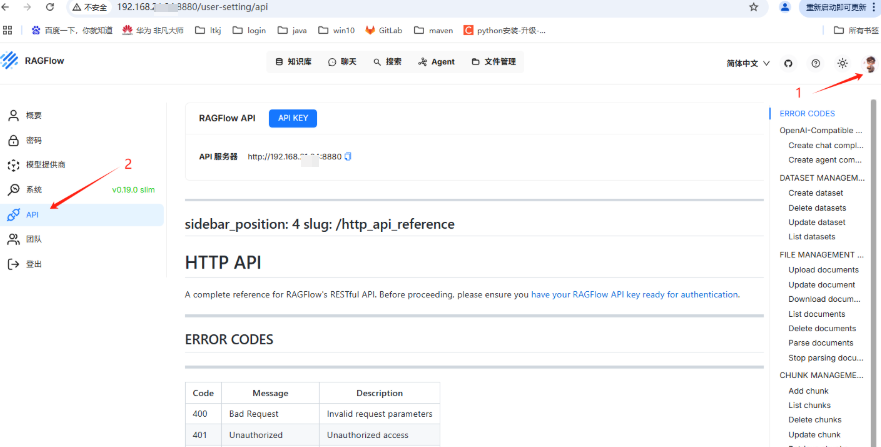
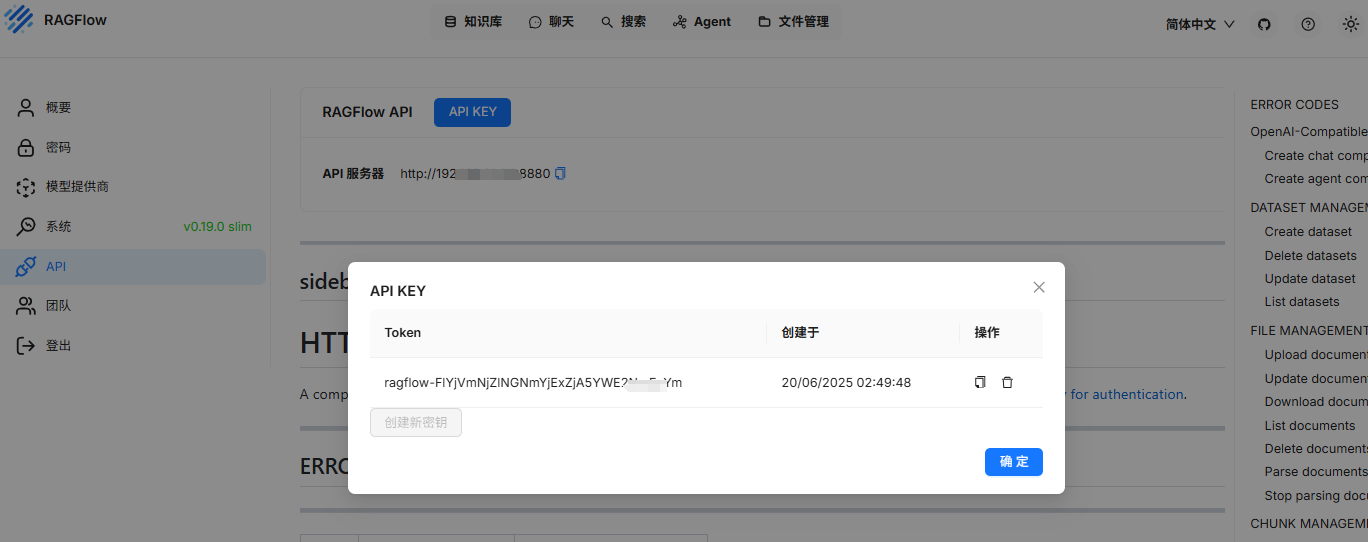
1-2-2. 点击上面key生成ragflow 对外提供的API
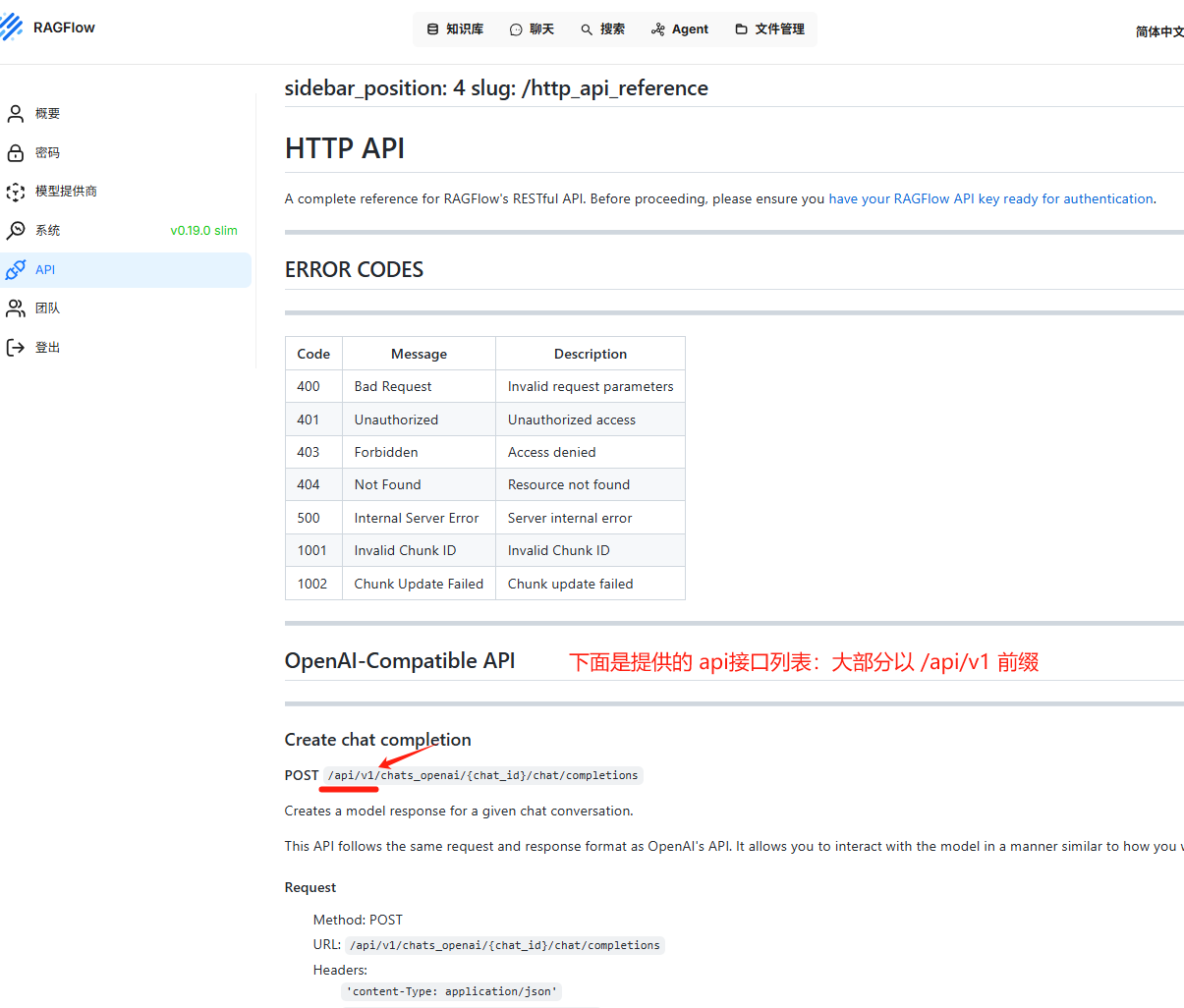
1-2-3. 下面就是ragflow 对外提供的HTTP 请求API接口文档,这里就不详细展开。
2. Dify与Ragflow联通
2-1. dify配置外部知识库
我们回到dify 工作流管理界面:http://192.168.21.24/apps,
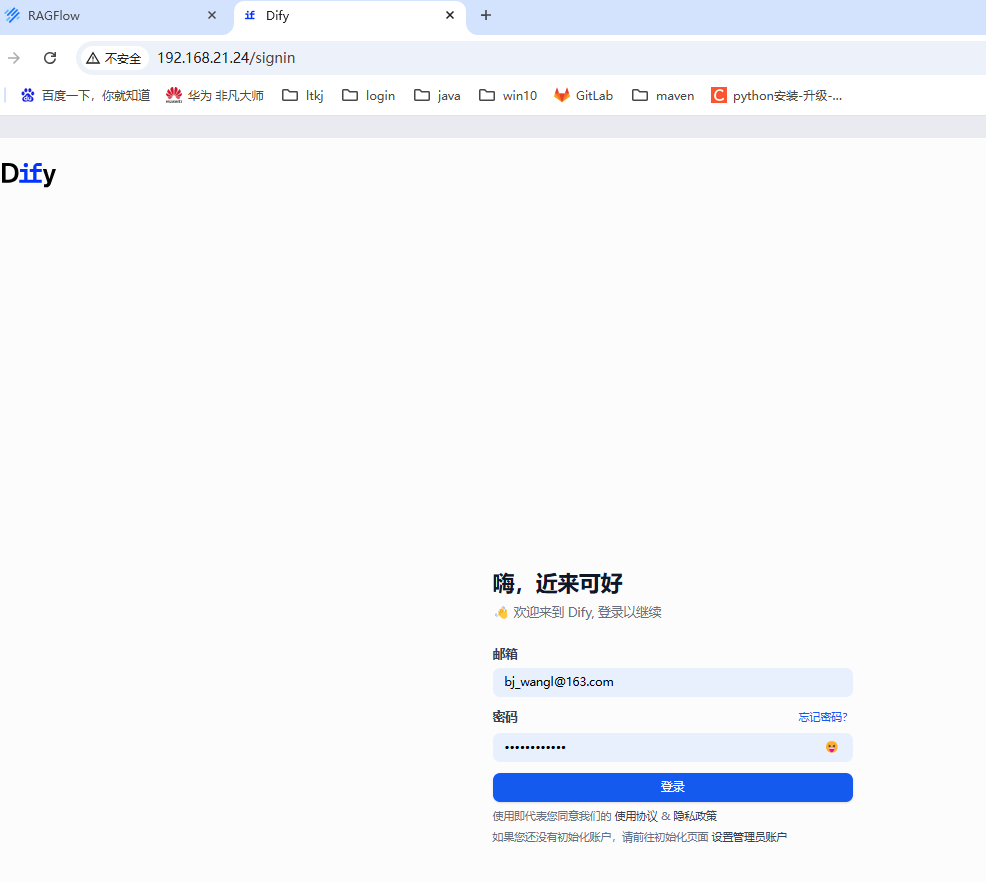
点击上面知识库,点击链接外部知识库。
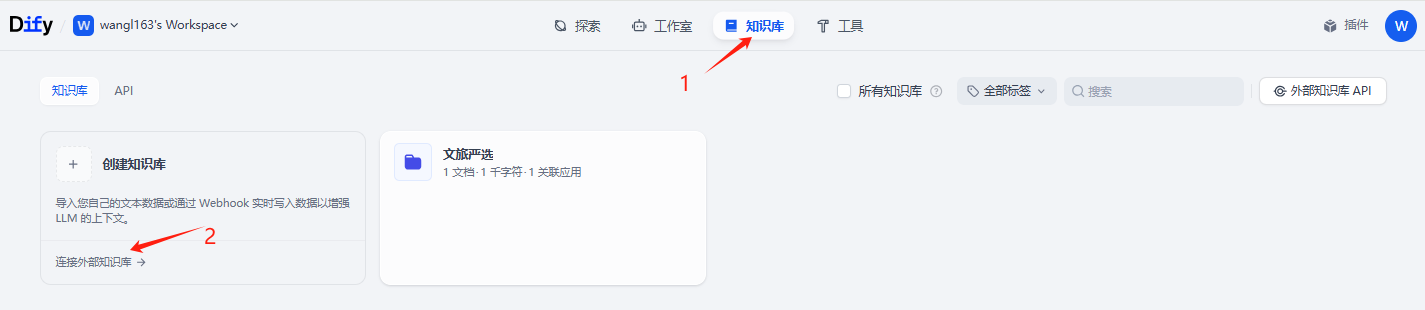
当然了,我们也可以点击右边的外部知识库API 先把外部知识库API 配置好。
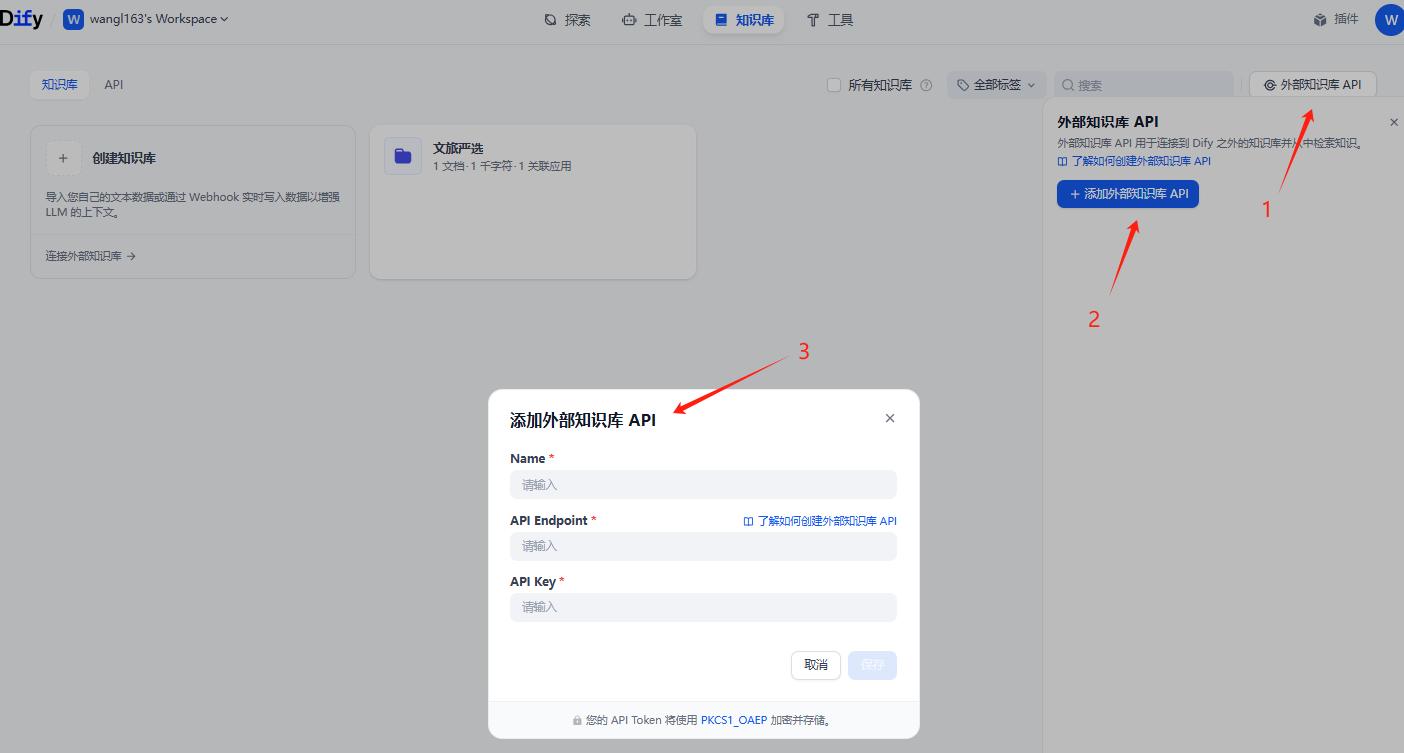
点击知识库,配置外部知识库。
这里我需要添加3个值
-
name 这个可以随便写一个名字
-
API Endpoint 这个就是和ragflow 整合的地址
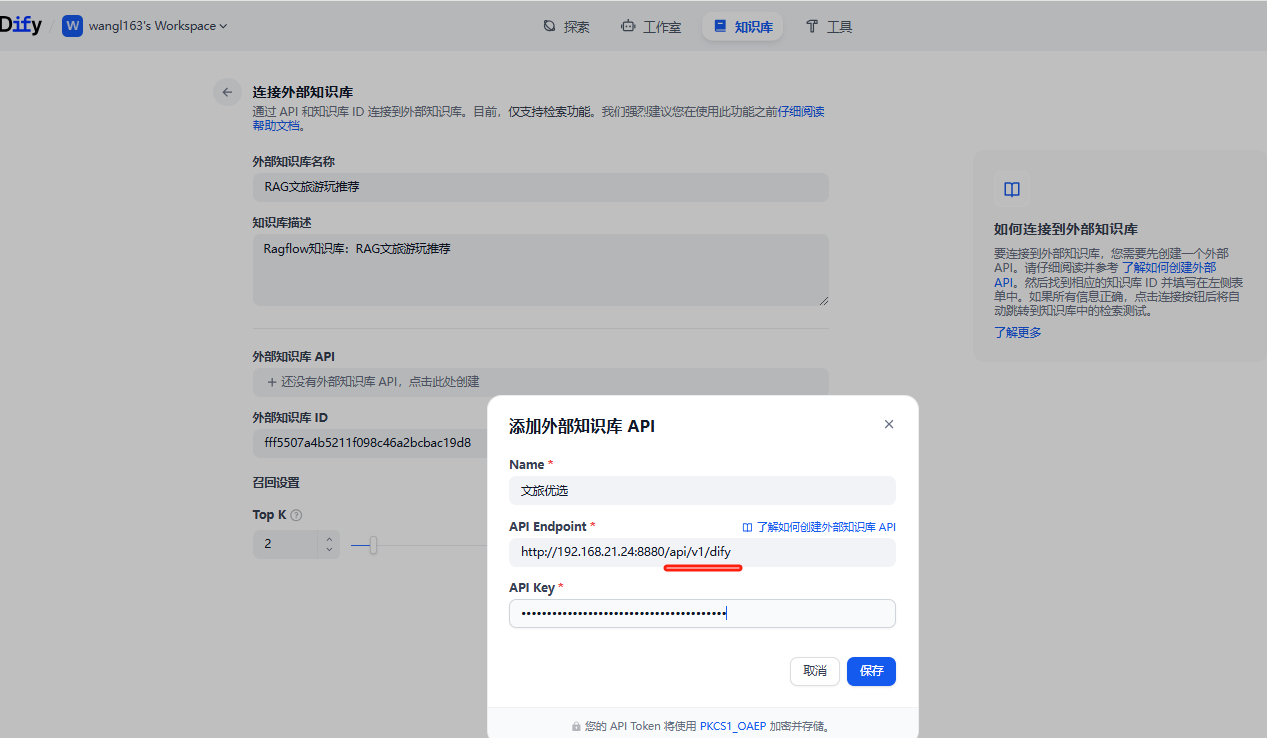
因为我们的RAGflow 对外提供的是192.168.xx.xx 我这里填写
http://192.168.XX.XX:8880/api/v1/difyURL 配置注意 在 Dify 中配置 RAGFlow 的知识库时,需要在 RAGFlow 的基础 Base url 后增加 “api/v1/dify”, 这是 Dify 特定的 API 路径,它承担版本控制、模块划分等作用。当然这也很符合 RESTful 的设计思想。 -
api key 就是上面ragflow-开头的api KEY
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











