







目录
前言
文章性质:学习笔记 📖
视频教程:FCN源码解析(Pytorch)- 1 代码的使用
主要内容:根据 视频教程 中提供的 FCN 源代码(PyTorch),对 predict.py 文件进行具体讲解。
Preparation

一、predict.py 代码解析
predict.py 文件的代码截图与相关解析如下:

【代码解析1】对 predict.py 文件代码的具体解析如下(结合上图):
- 在进行预测的过程中,我们不会启用辅助分类器,因此没有必要创建辅助分类器数据,故将 aux 设置为 False
- 这里的 palette.json 文件保存了标签文件对应的 调色板 ,例如预测类别为 0 的目标将用 [ 0 , 0 , 0 ] 颜色来表示
- 根据我们当前的设备,选择一个合适的 device 设备
- 调用 fcn_model.py 文件中的 fcn_resnet50 方法创建模型

【代码解析2】对 predict.py 文件代码的具体解析如下(结合上图):
- 用 torch.load 方法将权重载入至 device 设备,用 for 循环遍历删除与辅助分类器相关的参数
- 用 load_state_dict 方法将权重载入至 model 模型,再将模型执行到对应的设备中
- 用 Image.open 方法根据图片路径读取图片,赋给 original_img
- 进行一系列相应的预处理操作,包括 Resize、ToTensor、Normalize 等
- 用 torch.unsqueeze 方法增加一个 batch dimension
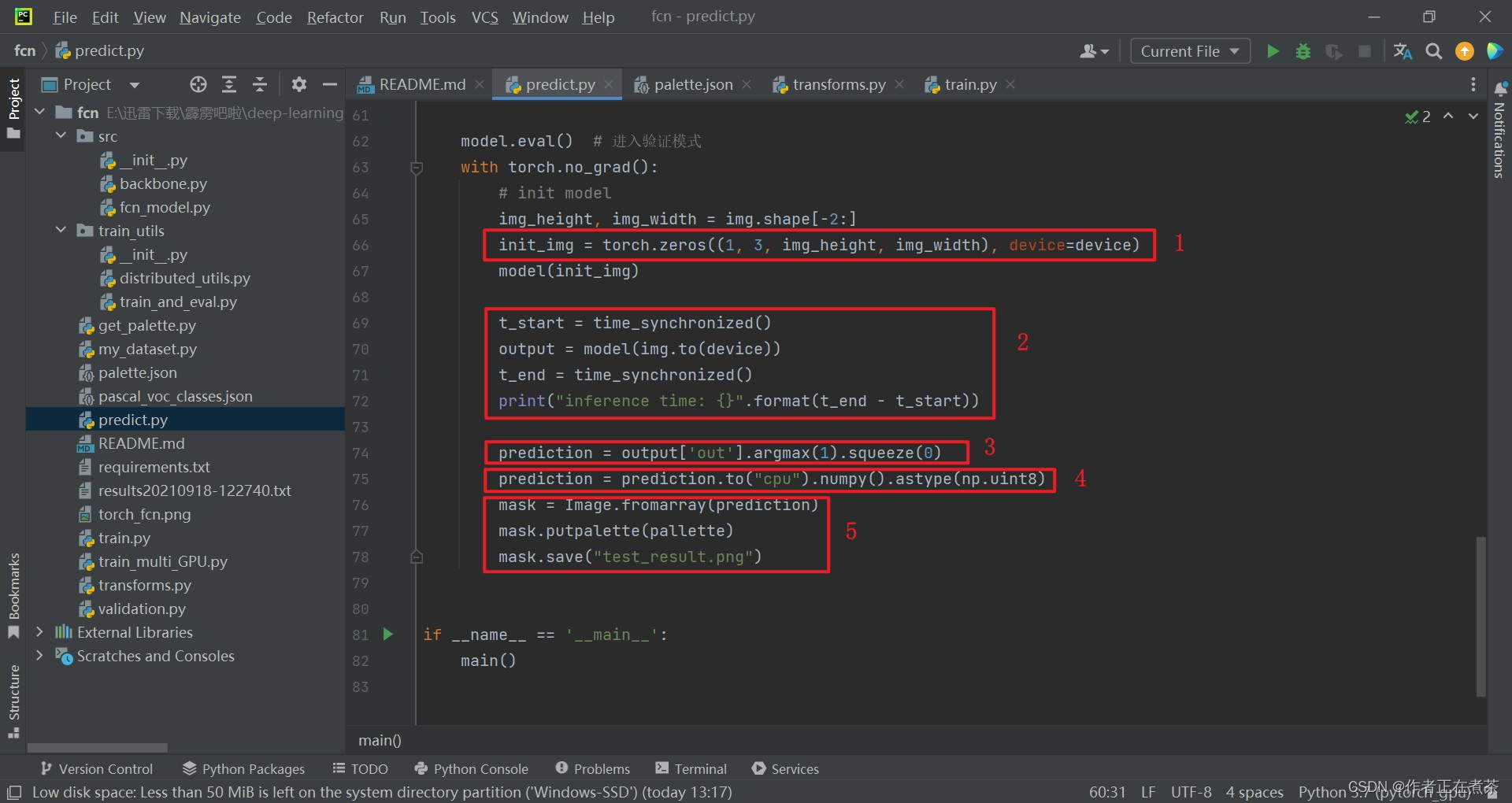
【代码解析3】对 predict.py 文件代码的具体解析如下(结合上图):
- 传入一张像素值全为 0 的图片,初始化模型
- 将待预测的图片载入到设备中,再传入到模型中进行预测
- 将预测结果中对应主输出上的数据解析出来,用 argmax 方法为每个像素指认预测的最终类别,用 squeeze 方法将 batch 维度压缩
- 将预测结果载入到 CPU 设备上,先转化成 numpy 格式,再转化成 int8 格式
- 用 PIL 库中的 Image.fromarray 方法读取 prediction 预测信息,设置调色板
二、predict.py 源代码
predict.py 代码如下:
import os
import time
import json
import torch
from torchvision import transforms
import numpy as np
from PIL import Image
from src import fcn_resnet50
def time_synchronized():
torch.cuda.synchronize() if torch.cuda.is_available() else None
return time.time()
def main():
aux = False # inference time not need aux_classifier
classes = 20
weights_path = "./save_weights/model_29.pth"
img_path = "./test.jpg"
palette_path = "./palette.json"
assert os.path.exists(weights_path), f"weights {weights_path} not found."
assert os.path.exists(img_path), f"image {img_path} not found."
assert os.path.exists(palette_path), f"palette {palette_path} not found."
with open(palette_path, "rb") as f:
pallette_dict = json.load(f)
pallette = []
for v in pallette_dict.values():
pallette += v
# get devices
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# create model
model = fcn_resnet50(aux=aux, num_classes=classes+1)
# delete weights about aux_classifier
weights_dict = torch.load(weights_path, map_location='cpu')['model']
for k in list(weights_dict.keys()):
if "aux" in k:
del weights_dict[k]
# load weights
model.load_state_dict(weights_dict)
model.to(device)
# load image
original_img = Image.open(img_path)
# from pil image to tensor and normalize
data_transform = transforms.Compose([transforms.Resize(520),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))])
img = data_transform(original_img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
model.eval() # 进入验证模式
with torch.no_grad():
# init model
img_height, img_width = img.shape[-2:]
init_img = torch.zeros((1, 3, img_height, img_width), device=device)
model(init_img)
t_start = time_synchronized()
output = model(img.to(device))
t_end = time_synchronized()
print("inference time: {}".format(t_end - t_start))
prediction = output['out'].argmax(1).squeeze(0)
prediction = prediction.to("cpu").numpy().astype(np.uint8)
mask = Image.fromarray(prediction)
mask.putpalette(pallette)
mask.save("test_result.png")
if __name__ == '__main__':
main()三、train.py 运行效果
下面是霹雳吧啦视频教程中的 train.py 运行截图:



【补充】关于 train.py 文件的代码讲解,大家可以参考我的上一篇博客:
下面是这篇文章中对 train.py 的 main 函数所作的解析:

【代码解析1】对 main 函数代码的具体解析如下(结合上图):
- 使用 torch.cuda.is_available() 判断我们当前的 GPU 设备是否可用,若可用则默认使用第一块 GPU 设备,否则使用 CPU 设备
- 默认 num_classes 会加上 1 ,也就是加上背景类别
- 创建 results.txt 文件,用来保存训练以及验证过程中每个 epoch 的输出信息
- 调用 my_dataset.py 文件中的自定义数据集读取部分
【补充】关于上面第四条的补充说明:
- 关于训练数据集 train_dataset ,其 transforms 采用了 get_transform(train=True) ,在 train.txt 中记录了训练过程中使用的图片
- 关于验证数据集 val_dataset ,其 transforms 采用了 get_transform(train=False) ,在 val.txt 中记录了验证过程中使用的图片
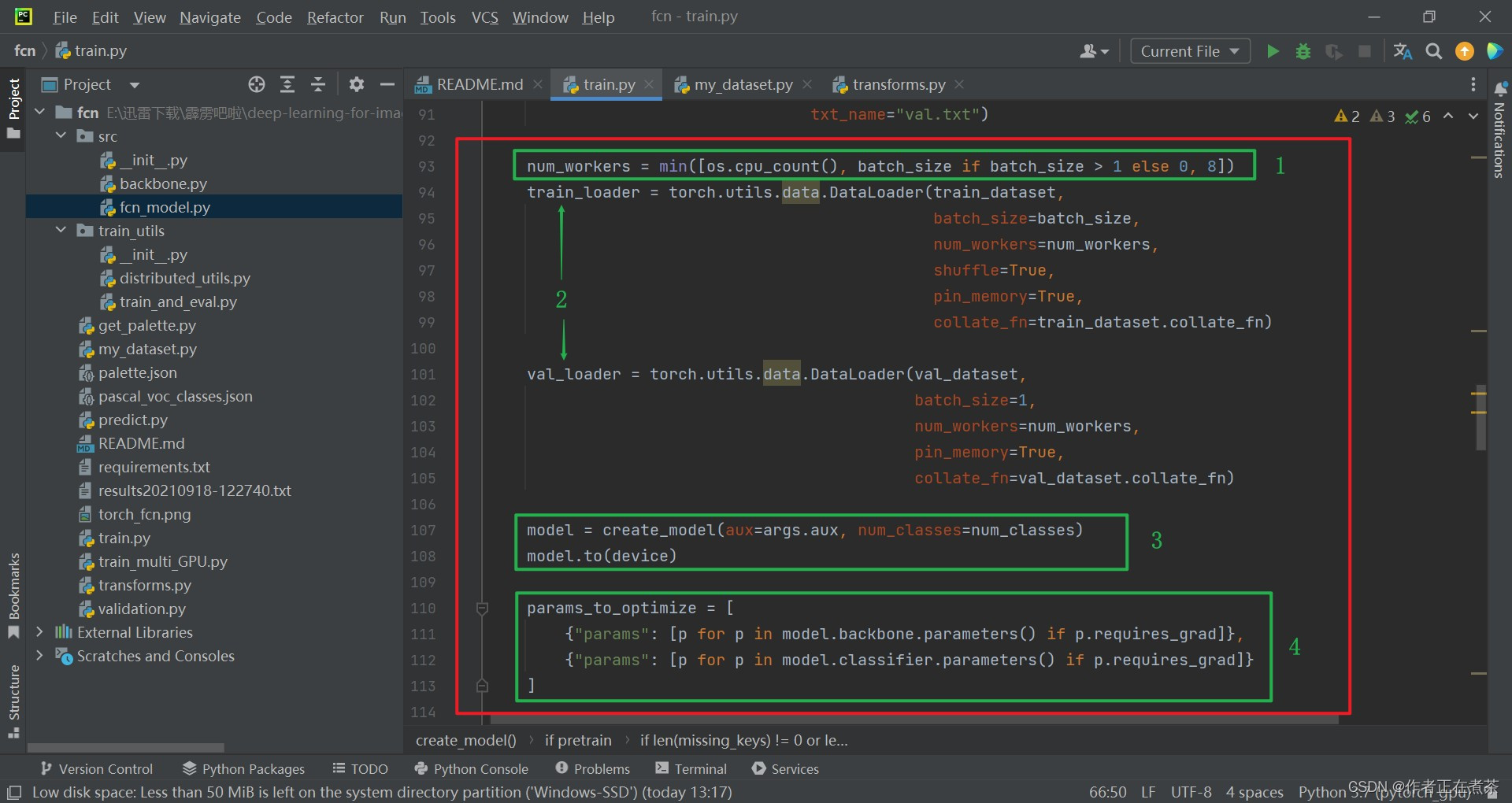
【代码解析2】对 main 函数代码的具体解析如下(结合上图):
- 设置 num_workers 值,在 GPU 的核数、max ( batch_size, 1 ) 和 8 中取最小值,赋给 num_workers
- 使用 torch.utils.data.DataLoader 分别载入训练数据集和验证数据集
- 调用 create_model 方法实例化模型,再将模型执行到对应的设备中
- 遍历 backbone 和 classifier 中的权重,将未冻结的权重提取出来,待会去训练这些权重

【代码解析3】对 main 函数代码的具体解析如下(结合上图):
- 如果使用辅助分类器的话,就将辅助分类器中未冻结的权重也提取出来,注意辅助分类器采用的学习率是初始学习率的 10 倍
- 定义优化器,采用 SGD ,传入我们要训练的参数,并设置初始学习率 lr、momentum、weight_decay 等
- 创建学习率更新策略,设置 warmup 为 True,从很小的学习率开始训练,慢慢增强到我们指定的初始化学习率,然后再慢慢下降
- 判断是否传入 resume 参数,如果是则载入最近一次保存的模型权重,然后去读取对应的模型权重、优化器数据、学习率更新策略

【代码解析4】对 main 函数代码的具体解析如下(结合上图):
- 这个 train_one_epoch 就是训练数据一轮的过程,可用 Ctrl + 左键 的方式点击查看该方法,具体讲解见(2)
- 这个 evaluate 就是验证数据的过程,可用 Ctrl + 左键 的方式点击查看该方法,具体讲解见(3)
- 打印 epoch 信息、训练过程的平均损失、学习率、训练的输出、验证的输出等,并记录到 results_file 中
- 保存 model 模型的参数、optimizer 优化器的参数、lr_scheduler 学习率更新策略的参数、epoch 和 args 等
















 873
873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











