








现在越来越多的推荐模型开始利用用户的点击序列来发掘用户的兴趣,本文主要是关注用户的如何在序列表征中去噪,并对用户的长期兴趣进行发掘建模,从而提出user-aware memory network (DUMN).
背景
阿里之前已经提出过很多利用用户历史点击序列来建模进行推荐的模型,比如DIEN,DIEN等等。
- 但是这些方法都没有考虑到序列中的噪声对表征的影响,
- 并且通常我们使用用户的短序列建模后可以发掘用户的短期兴趣,而如果想要挖掘用户的长期兴趣则需要更长的序列,而这会导致很大的内存和计算消耗,并且从用户序列中发掘的长期兴趣也不一定是合理的。例子:比如一个用户有宠物猫,那他长期兴趣可能是猫粮;这和他近期点了什么无关。因此,长期兴趣更好的方式是从用户本身特征出发,而这可以和用户的点击序列解耦。
- 系统得到的反馈,包括评分、点击与否、喜欢与否等都能反映用户的兴趣,但是不同的反馈形成的偏好是有区别的。
方法
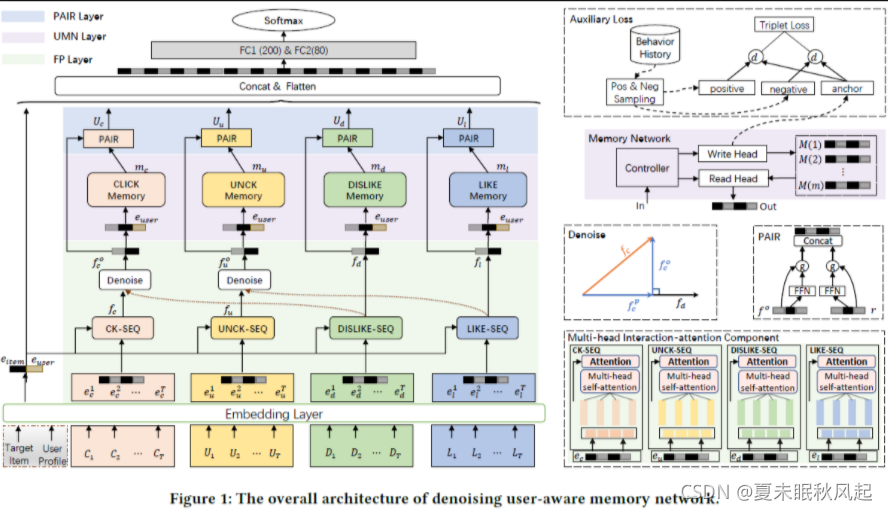
如图所示,DUMN有四个部分组成包括:embedding
layer, FP layer, UMN layer and PAIR layer。
- embedding
layer:将用户、ad和click、unclick、like、dislike四个序列作为输入,然后得到embedding - FP layer:这部分是图中右下部分的多投交互注意力组件(multi-head interaction-attention component)。对隐式和显式反馈进行建模,利用正交映射(orthogonal
mapping)将显式反馈的的表征对隐式反馈去躁。 - UMN:捕获用户细粒度的长期兴趣
- PAIR:将短期兴趣和长期兴趣融合交叉表征,最后进行预测。
Embedding Layer
embedding部分主要就是将上述对的6个部分进行转换,用户,item的profile特征以及用户的行为序列特征click: C = [ C 1 , C 2 , . . . , C T ] C=[C_1,C_2,...,C_T] C=[C1,C2,...,CT],unclick: U = [ U 1 , U 2 , . . . , U T ] U=[U_1,U_2,...,U_T] U=[U1,U2,...,UT]作为隐式反馈,dislike: D = [ D 1 , D 2 , . . . , D T ] D=[D_1,D_2,...,D_T] D=[D1,D2,...,DT],like: L = [ L 1 , L 2 , . . . , L T ] L=[L_1,L_2,...,L_T] L=[L1,L2,...,LT]作为显示反馈。其中T是序列最长长度。根据以往的方法embedding后得到 e u s e r , e i t e m , e c , e u , e d , e l e_{user},e_{item},e_c,e_u,e_d,e_l euser,eitem,ec,eu,ed,el。 e c , e u , e d , e l ∈ R T × E e_c,e_u,e_d,e_l \in R^{T \times E} ec,eu,ed,el∈RT×E
Feature Purification Layer(FP Layer)
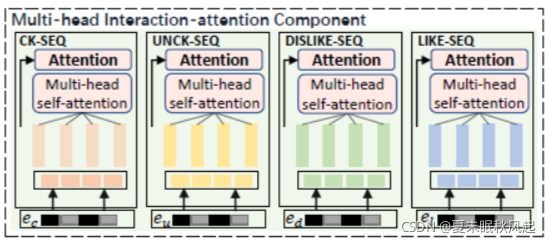
用两个模块来学习用户的短期兴趣,并利用正交映射将显示反馈的表征净化隐式反馈的表征。
Multi-head Interaction-attention Component
**利用多投自注意力网络来捕获用户的细粒度偏好表征。**如图1中右下角。以 e c e_c ec为例,将 e c e_c ec构造为H头, e c = [ e c , 1 , . . . , e c , h , . . . , e c , H ] e_c=[e_{c,1},...,e_{c,h},...,e_{c,H}] ec=[ec,1,...,ec,h,...,ec,H], e c , h ∈ R T × 1 H E e_{c,h} \in R^{T \times \frac{1}{H} E} ec,h∈RT×H1E表示第h个头对应的 e c e_c ec。多投自注意力机制计算方式如下:
head h = softmax ( e c , h W c , h Q ( e c , h W c , h K ) T T ) e c , h W c , h V h = 1 , 2 , … , H , O c = Concat ( h e a d 1 , head 2 , … , head H ) W F \begin{array}{c} \text { head }_{h}=\operatorname{softmax}\left(\frac{\mathbf{e}_{c, h} \mathbf{W}_{c, h}^{Q}\left(\mathbf{e}_{c, h} \mathbf{W}_{c, h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









