







Lasso的身世
Lasso全称为The Least Absolute Shrinkage and Selection Operator,是Tibshrani受到Breiman的Non-Negative Garrote(NNG)的启发在1996年提出的一种压缩估计方法,他把NNG的两步合并为一步,即L1-norm regularization。Lasso的巨大优势在于它所构造的模型是Sparse的,因为它会自动地选择很少一部分变量构造模型。现在,Lasso已经家喻户晓了,但是Lasso出生后的头两年却很少有人问津。后来Tibshirani自己回忆时说,可能是由下面几个原因造成的:1. 速度问题:当时计算机求解Lasso的速度太慢;2. 理解问题:大家对Lasso模型的性质理解不够(直到Efron的LAR出来后大家才搞明白);3. 需求问题:当时还没有遇到太多高维数据分析的问题,对Sparsity的需求似乎不足。Lasso的遭遇似乎在阐释我们已经熟知的一些道理: 1.千里马常有,而伯乐不常有(没有Efron的LAR,Lasso可能很难有这么大的影响力)。2.时势造英雄(高维数据分析的问题越来越多,比如Bioinformatics领域)。3.金子总是会闪光的。
Lasso的思想
从线性回归到Lasso
使用最小二乘法(最小化残差平方和(RSS))拟合的普通线性回归是数据建模的基本方法。其建模要点在于误差项一般要求独立同分布(常假定为正态)零均值。
对较复杂的数据建模,普通线性回归会有一些问题:
- * 预测精度的问题 * 如果响应变量和预测变量之间有比较明显的线性关系,最小二乘回归会有很小的偏倚,特别是如果观测数量n远大于预测变量p时,最小二乘回归也会有较小的方差。但是如果n和p比较接近,则容易产生过拟合;如果n小于p,最小二乘回归得不到有意义的结果。
- * 模型解释能力的问题 * 一个多元线性回归模型里的很多变量可能是和响应变量无关时也有可能产生多重共线性的现象:即多个预测变量之间明显相关。这些情况都会增加模型的复杂程度,削弱模型的解释能力。这时候需要进行变量选择(特征选择)。其中一种选择方法称为正则化(又称收缩方法),主要包括:
- 岭回归(ridge regression):在最小化RSS的计算里加入了一个收缩惩罚项(正则化的l2范数),惩罚项的加入有利于缩减待估参数接近于0。
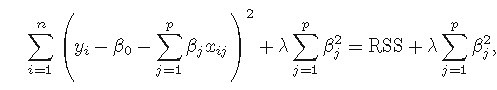
这个惩罚项中lambda大于等于0,是个调整参数。因此重点在于lambda的确定,可以使用交叉验证或者Cp准则。
岭回归优于最小二乘回归的原因在于方差&偏倚选择。随着lambda的增大,模型方差减小而偏倚(轻微的)增加。岭回归缺点:在建模时,同时引入p个预测变量,罚约束项可以收缩这些预测变量的待估系数接近0,但并非恰好是0(除非lambda为无穷大)。这个缺点对于模型精度影响不大,但给模型的解释造成了困难。这个缺点可以由lasso来克服。(所以岭回归虽然减少了模型的复杂度,并没有真正解决变量选择的问题- lasso回归: 通过对最小二乘估计加入罚约束,使某些系数的估计为0。
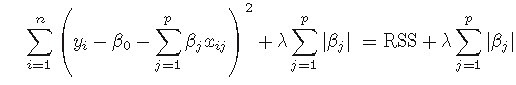
lasso是在RSS最小化的计算中加入一个l1范数作为罚约束。l1范数的好处是当lambda充分大时可以把某些待估系数精确地收缩到0。
关于lasso的发展和一些思想介绍可以参考网上很有名气的一篇文章《统计学习那些事》(http://cos.name/2011/12/stories-about-statistical-learning/)。
认识Lasso
Lasso通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。Lasso 的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0 的回归系数,得到可以解释的模型。将Lasso应用于回归,可以在参数估计的同时实现变量的选择,较好的解决回归分析中的多重共线性问题,并且能够很好的解释结果.
Lasso相关文献
以下是几篇影响比较大的:(转载自http://blog.csdn.net/godenlove007/article/details/11387977)
- 最基本的一篇
http://www-stat.stanford.edu/~tibs/lasso.html - yuan ming 然后提出的 group lasso
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.79.2062 - zou hui的elastic net,可以同时自动选取相关程度比较大的变量(LASSO不能)
http://www-stat.stanford.edu/~hastie/TALKS/enet_talk.pdf - zou hui 提出的adative lasso,试图避免lasso对参数的shrunkage
http://www.stat.umn.edu/~hzou/Papers/adaLasso.pdf
-jianqing fan 2001 年提出的另外一种 nonconvex的惩罚项 – SCAD
http://www.orfe.princeton.edu/~jqfan/papers/01/penlike.pdf
其学生08年时接着解决了SCAD的算法问题 – 实际上就是一种adaptive lasso
http://www.stat.umn.edu/~hzou/Papers/onestep.pdf - 另外,LASSO还被广泛应用在graphical model上,三篇是目前文献里公认的里程碑式的文章–关于gaussian graphical model的:
http://www.stats.ox.ac.uk/~meinshau/consistent.pdf
http://arxiv.org/abs/0811.4463
http://www-stat.stanford.edu/~tibs/ftp/graph.pdf















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









