







这篇笔记用来记录 2025年 发表在arxiv上的一篇有关 VLA 领域的论文。这篇文章是英伟达、斯坦福、MIT 三个高校联合发布。其核心思想是用自回归能力生成整个任务过程中的目标子图,然后根据这些目标子图再去生成action chunk,目的是将CoT 引入到VLA中以提升模型整体性能;
虽然该模型在总体性能上提升不大(3%~16%)之间,但其引入视觉思维链的思想与方法可以作为未来工作的参考。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLA, LLM, VLM 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
- 原文链接: https://arxiv.org/abs/2503.22020
- 发表时间:2025年03月27日
- 发表平台:arxiv
- 预印版本号:[v1] Thu, 27 Mar 2025 22:23:04 UTC (20,341 KB)
- 作者团队:Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Ming-Yu Liu, Donglai Xiang, Gordon Wetzstein, Tsung-Yi Lin
- 院校机构:
- NVIDIA;
- Standford University;
- MIT;
- 项目链接: https://cot-vla.github.io
- GitHub仓库: 【暂无】
Abstract
VLA 已展现出使用预训练的VL模型和机器人演示来学习可泛化的感觉运动控制的潜力。虽然这种范式有效地利用了来自机器人和非机器人的大规模数据,但当前 VLA 主要侧重于直接输入输出映射,缺乏对复杂操作任务至关重要的中间推理步骤。因此,现有 VLA 缺乏时间规划或推理能力。本文介绍了一种将显式视觉思路链 (CoT) 推理融入VLA 的方法,通过自回归预测未来图像帧作为视觉目标,然后生成一个简短的动作序列来实现这些目标。文中介绍了 CoT-VLA 一个 7B 参数的 VLA 模型,可以理解和生成视觉和动作标记。实验结果表明,CoT-VLA 性能卓越,在真机操作任务中比最先进的 VLA 模型高出 17%,在仿真基准测试中比最先进的 VLA 模型高出 6%。可以通过这个链接查看演示视频 https://cot-vla.github.io/。
1. Introduction
机器人领域的最新训练策略方面取得了令人瞩目的进展,这些策略可以应用于不同的任务和环境。其中一个有前进的方向是VLA模型,利用预训练 VLM 的理解能力,将自然语言指令和视觉观察映射到机器人动作。通过在机器人演示上训练 VLM,VLA 继承了理解不同场景、物体、自然语言指令的能力,从而在下游针对性测试场景进行微调后获得了更好的泛化能力。虽然这些方法已经显示出令人印象深刻的结果,但它们通常直接从观察映射到动作,而没有明确的中间推理步骤,这可能会提高可解释性并可能提高性能。
在语言领域,思路链 (Chain-of-Thought,CoT) 已成为一种强有力的技术,通过激励循序渐进的思考方式来提升大型语言模型 (LLM) 的推理能力。将该概念应用于机器人技术,将建立在文本、视觉观察、身体动作基础上的推理提供了可能。最近的研究通过加入语言描述、关键点或边界框等中间推理步骤,在这个方向上取得了进展。这些中间表示捕捉场景、物体、任务的抽象状态,通常需要额外的预处理流程。在本文的工作中,作者探索了目标子图像作为动作生成之前的中间推理步骤。这些图像捕捉了模型推理过程的状态,并且在机器人演示数据集中自然可用。虽然先前的研究已经探索了子目标生成和任务条件下的模仿学习,但本文作者是第一个将这些概念与 VLA 相结合作为中间思路链推理步骤的方法。
作者提出用于 VLA 的视觉思路链推理,一种使用子目标生成图像作为机器人任务思路链推理形式的新方法。该方法不是直接预测动作,而是首先生成一个代表机器人在像素空间中的规划状态的子目标图像,然后根据当前观察和生成的子目标图像来调整其动作。这种方法允许模型在采取行动之前“视觉地思考”如何完成任务。通过使用子目标图像作为中间推理步骤,利用机器人操作数据中已有的信息只需极少的预处理。此外,由于子目标图像生成不需要动作注释,这展现了使用视频数据来改进视觉推理和理解的潜力。
同时构建了 CoT-VLA 系统,该系统基于最新的通用多模态基础模型,利用视觉思维链推理,模型可以理解和生成文本和图像。在 Open X-Embodiment 数据集和无动作视频数据集上训练基础模型,然后在下游机器人任务上采集演示对模型进行微调。作者为 CoT-VLA 设计了一种混合注意力机制:将因果注意力与下一个标记预测结合,用于文本和图像生成,并利用完全注意力一次性预测所有动作维度。参考该领域最的新进展,模型预测完整的动作序列action chunk,而不是每个时间步的单个动作。作者证明了 action chunk 块和混合注意力机制均可提升模型性能。
通过在仿真基准测试和真实世界实验中的大量实验,作者证明了视觉思维链推理相比之前的 VLA 方法有助于提升策略性能。主要贡献包括:
- 引入了一种通过子目标图像生成进行视觉思维链推理的方法,作为机器人控制的中间推理步骤;
- 引入了一个系统
CoT-VLA,融合了视觉思维链推理,以及混合注意力机制,包括对像素和文本生成的因果注意力以及对动作预测的完全注意力; - 在仿真和现实世界中进行了全面的评估,证明视觉思路链推理提高了 VLA 性能,系统在多个机器人平台和任务中都达到了SOTA;
2. Related Work
Chain-of-Thought Reasoning
思维链推理在自然语言处理领域已崭露头角,因为它能够将问题分解为连续、可解释的步骤,从而使模型能够执行复杂的多步骤推理。早期关于思维链推理的研究已经证明了 LLM 在得出最终答案之前生成中间推理步骤的有效性。将这一范式扩展到视觉领域,研究人员探索了多模态思维链方法,其中以逐步推进的方式处理视觉信息以推理未来的结果或状态,包括生成bounding box、使用稳定扩散、使用标准 Python 包进行中间图像填充,生成 CLIP 嵌入。近期,思维链推理已在具身应用中得到探索,可以生成多阶段执行的文本、点轨迹、标记物体的bounding box、附加观测值的夹持器位置、用于开环跟踪的未来图像轨迹、用于强化学习的细粒度奖励指导。在本研究中,作者引入了用于机器人操作的 Visual-CoT 推理,将预测的子目标图像作为闭环动作生成的中间推理步骤。该方法使用演示视频作为自然的中间推理状态无需额外的注释。
Vision-Language-Action Models
VLM 已成为机器人学习的有力工具,近期的研究探索了将其集成到系统中的各种方法。一些研究利用 VLM 作为感知和控制的中间组件,利用其强大的语义理解和推理能力来分解复杂任务、检测物体、生成奖励或目标;一些方法将 VLM合并到端到端可训练策略中,将其用作预训练的back bone 以获得更好的视觉语言表征。与本文工作最相关的是另一些方法,这些方法在演示数据上对预训练的 VLM 进行微调,以直接预测动作,通过在互联网规模的视觉语言数据集上进行预训练,这些 VLA 展示了对新物体、环境、自然语言指令的更高泛化能力,为将视觉和语言知识迁移到机器人控制任务提供了可行方向。然而,大多数现有的 VLA 并没有利用大型语言模型逐步推理能力,而该能力已被证明可以显著提高各种任务的性能。过去,研究人员将思路链推理应用于语言指令或中间关键点 / bounding box生成,作者则将视觉思路链推理引入 VLA 框架,以子目标图像作为动作生成之前的中间推理步骤。
3. CoT-VLA
本节将介绍用于 VLA 的视觉思维链推理框架。首先阐述方法(3.1),然后详细描述系统架构(3.2),之后解释训练流程(3.3),以及概述下游任务的部署策略(3.3)。
3.1. Visual Chain-of-Thought Reasoning
考虑两种类型的训练数据用于 VLA 预训练:机器人演示数据集 D r D_{r} Dr 和无动作视频数据集 D v D_{v} Dv。机器人演示表示为 D r = { ( l , a 1 … T , s 1 … T ) } D_{r}=\{(l, a_{1\dots T},s_{1\dots T})\} Dr={(l,a1…T,s1…T)} ,其中 l l l 表示自然语言指令, a 1 … T = { a 1 … , a T } a_{1\dots T}=\{a_{1}\dots,a_{T}\} a1…T={a1…,aT} 表示机器人动作序列, s 1 … T = { s 1 , … , s T } s_{1\dots T}=\{s_{1},\dots, s_{T}\} s1…T={s1,…,sT} 表示作为图像序列的视觉观察结果;无动作视频 D v = { ( l , s 1 … T ) } D_{v}=\{(l,s_{1\dots T})\} Dv={(l,s1…T)} 由语言描述和不带动作标注的图像组成。
VLA
Vanilla VLA 方法在
D
r
D_{r}
Dr 上对预训练的 VLM
P
θ
P_{\theta}
Pθ 进行微调,学习直接从当前观察 $s_{t} $和语言指令
l
l
l 预测动作
a
^
t
+
1
\hat{a}_{t+1}
a^t+1 如 Fig.1 所示:
a ^ t ∼ P θ ( a t ∣ s t , l ) \begin{equation} \hat{a}_{t}\sim P_{\theta}(a_{t}|s_{t},l) \end{equation} a^t∼Pθ(at∣st,l)
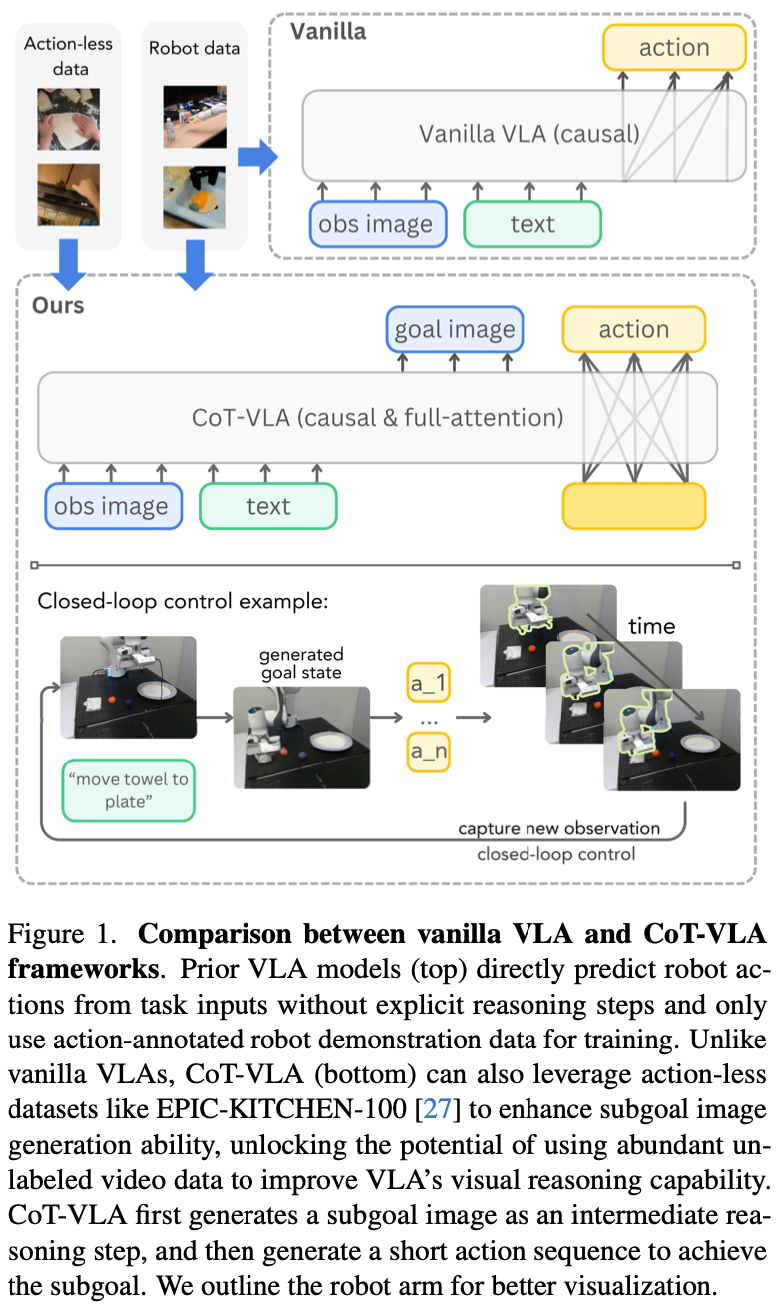
CoT VLA
作者的核心创新点是在动作生成之前融入明确的视觉推理。如Fig.2 所示,方法分为两个连续的阶段:
s ^ t + n ∼ P θ ( s t + n ∣ s t , l ) { a ^ t , … , a ^ t + m } ∼ P θ ( { a t , … , a t + m ∣ s t , l , s t + n } ) \begin{align} \hat{s}_{t+n}\sim P_{\theta}(s_{t+n}|s_{t},l) \\ \{\hat{a}_{t},\dots,\hat{a}_{t+m}\}\sim P_{\theta}(\{a_{t},\dots,a_{t+m}|s_{t},l,s_{t+n}\}) \end{align} s^t+n∼Pθ(st+n∣st,l){a^t,…,a^t+m}∼Pθ({at,…,at+m∣st,l,st+n})
- 预测
n
n
n 帧后的子目标图像
s
^
t
+
n
\hat{s}_{t+n}
s^t+n,作为中间视觉推理步骤(
Equation.2); - 生成一系列
m
m
m 个动作来实现该子目标状态(
Equation. 3),使得模型能够通过明确推理期望的未来状态来进行“视觉思考”; - 预测动作;
视觉推理步骤(Equation.2)在机器人演示
D
r
D_{r}
Dr 和无动作视频
D
v
D_{v}
Dv 上进行训练,而动作生成步骤(Equation.3)仅在机器人演示
D
r
D_{r}
Dr 上进行训练。
3.2. The Base Vision-Language Model
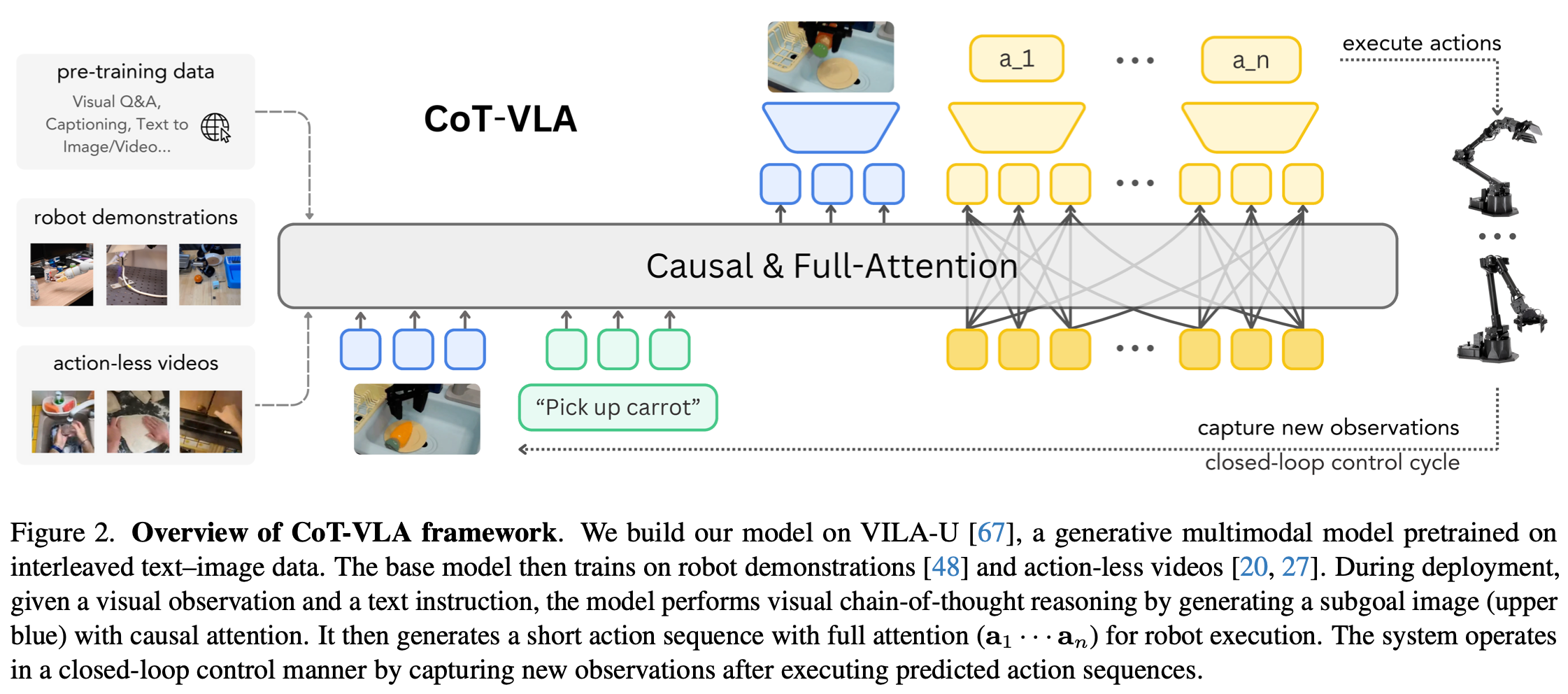
为了实现Equation.2中描述的视觉推理能力,作者在 VILA-U 的多模态基础模型上进行了构建,该模型能够理解和生成图像和文本标记。
VILA-U 通过自回归下一个标记预测统一了视频、图像、语言理解。其核心是一个视觉塔(vision tower),将视觉输入编码为与文本信息对齐的离散标记,让自回归图像和视频生成成为可能,同时显著增强了 VLM 利用离散视觉特征的理解能力。VILA-U 利用残差量化提升离散视觉特征的表征能力,结合depth transformer(类似于 RQ-VAE 中的引导)来逐步预测残差标记。提取出的视觉特征后通过projection传递给 LLM 主干网络处理。基础模型在多模态对上进行训练,包括 [image,text]、[text,image]、[video,text] 和 [text,video]。 VILA-U 模型在 256×256 分辨率图像上进行训练,其中每幅图像被编码为 16×16×4 个 token,残差深度为 4。
3.3. Training Procedures
基于演示
D
r
D_{r}
Dr 和无动作视频
D
v
D_{v}
Dv 对基础 7B VILA-U 模型进行预训练。训练过程优化了三个组件:LLM backbone、projector、depth transformer,同时保持vison tower冻结。训练目标包含两个关键部分:基于因果注意力机制的子目标图像生成 和 基于完全注意力机制的动作生成。
Visual Tokens Prediction
关于子目标图像生成,定义每个训练序列的形式为 ( l , s + t , s t + n ) (l, s+{t}, s_{t+n}) (l,s+t,st+n),在每个视觉位置 j j j,depth transformer P δ P_{\delta} Pδ 基于 LLM 生成的 code embedding h j h_{j} hj 自回归地预测 D D D 个残差 token ( k j 1 , , … , k j , D ) (k_{j1,},\dots,k_{j,D}) (kj1,,…,kj,D)。视觉 token 的训练目标公式如下:
L v i s u a l = − ∑ j ∑ d = 1 D log P δ ( k j d ∣ k j , < d ) L_{visual}=-\sum_{j}\sum_{d=1}^{D}\log{P_{\delta}(k_{jd}| k_{j, < d})} Lvisual=−j∑d=1∑DlogPδ(kjd∣kj,<d)
其中 j j j 表示包含视觉标记的位置。有关该损失函数的更详细解释,请参阅第 3.2 节。
Action Tokens Prediction
关于动作预测,每个训练序列的形式为
(
l
,
s
t
,
s
t
+
n
,
a
t
,
.
.
.
,
a
t
+
m
)
(l, s_{t}, s_{t+n}, a_{t}, ..., a_{t+m})
(l,st,st+n,at,...,at+m)。每个动作
a
i
a_{i}
ai 由 7 个标记表示,每个动作维度独立离散化。将每个连续动作维度映射到 256 个离散 bin 中,bin widths 由均匀划分训练数据动作分布的 1~99 白分位数之间的间隔来确定;文本标记器词汇表中使用频率最低的 256 个标记重新用作动作 bin 标记。这里采用充分注意力机制来处理和预测动作标记,使所有动作标记能够相互作用。Fig. 3 展示了这种注意力机制,在训练期间最小化动作预测的交叉熵损失:
L
a
c
t
i
o
n
=
−
∑
i
=
1
m
l
o
g
P
θ
(
a
t
,
…
,
a
t
+
m
∣
l
,
s
t
,
s
t
+
n
)
L_{action}=-\sum^{m}_{i=1}log P_{\theta} (a_{t},\dots, a_{t+m} | l, s_{t}, s_{t+n})
Laction=−i=1∑mlogPθ(at,…,at+m∣l,st,st+n)

对于给定一批输入序列,整体训练目标结合动作和视觉损失:
L = L v i s u a l + L a c t i o n L=L_{visual}+L_{action} L=Lvisual+Laction
Pretraining Phase
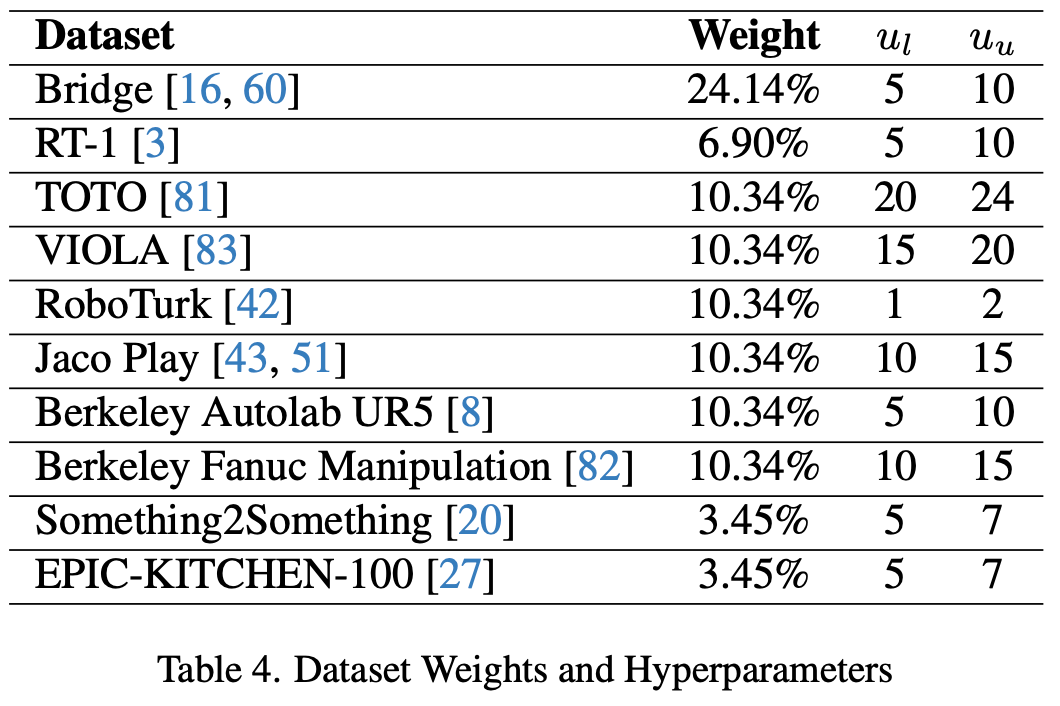
对演示
D
r
D_{r}
Dr 和无动作视频 $D_{v} 进行 CoT-VLA 预训练,如第 3.1 节所述。从 Open X-Embodiment 数据集(OpenX)中选了一个子集,按照 Open-VLA 中的预处理流程,选择并处理含有第三人称摄像机图像和单臂末端执行器控制(7-DoF)的数据集;对于无动作视频
D
v
D_{v}
Dv,结合 EPIC-KITCHENS 和 Something-Something V2 数据集,所有图像均以 256x256 分辨率处理;对于视觉推理,使用在未来时间步
n
n
n 的子目标图像,这些图像是从数据集特定的范围
[
n
l
,
n
u
]
[n_{l} , n_{u}]
[nl,nu] 中均匀采样的,其中
n
l
n_{l}
nl 和
n
u
n_{u}
nu 定义了预测范围的下限和上限,使用的 action chunk size为 10。
Adaptation Phase for Downstream Closed-Loop Deployment
为了适应下游任务,在目标机器人上用特定任务采集的演示数据
D
r
D_{r}
Dr 进行微调预训练模型。此阶段优化 LLM backbone、projector、depth transformer,同时保持vision tower冻结,并与预训练阶段使用相同的训练设置。最终模型可以基于自然语言命令
l
l
l 执行新的操作任务。
A
l
g
o
r
i
t
h
m
1.
Algorithm 1.
Algorithm1.描述了测试时的整体流程。

4. Experiments
通过一系列仿真和真实机器人操作实验来评估模型和系统的有效性,旨在解决以下问题:
- 与多个基准测试中的 SOTA 该系统表现如何(第 4.2 节);
- 预训练、视觉思维链推理、混合注意对任务表现有何影响(第 4.3 节);
- 强化视觉推理泛化在多大程度上增强了动作预测能力(第 4.4 节);
4.1. Experimental Setup
作者在三个互补的配置上进行了评估:仿真环境的LIBERO、总计 45k 个机器人演示数据集 Bridge-V2 、Franka-Tabletop 一个固定在桌子上的 Franka Emika Panda 机器人,每个测试场景的机器人演示数量限制为 10 到 150 个。
LIBERO Simulation Benchmark
LIBERO 是一个包含四个不同类型的仿真基准测试:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal、 LIBERO-Long。每个类型包含 10 个不同的任务,每个任务有 50 个人类遥操作演示,旨在评估机器人对空间关系、物体交互、特定任务目标的理解能力。预处理流程为:
- 从轨迹中移除停顿间隔;
- 将图像分辨率标准化为
256×256像素; - 对所有图像进行 180 度旋转;
Bridge-V2 Real-Robot Experiments
使用六自由度 WidowX 机械臂,按照 Bridge-V2 实验设置。训练数据包含来自 Bridge-V2 数据集的 45,000 条带语言注释的各种操作任务轨迹。在预训练阶段,该数据集与 OpenX 一起被送入训练,同时专门在 Bridge-V2 上执行额外的特定任务微调,直到达到 95% 的训练动作预测准确率阈值。评估四个任务以验证 视觉鲁棒性(不同的干扰项)、运动泛化能力(新的物体位置)、语义泛化能力(未见过的语言指令)、语言基础(指令遵循能力)。
Franka-Tabletop Real-Robot Experiments
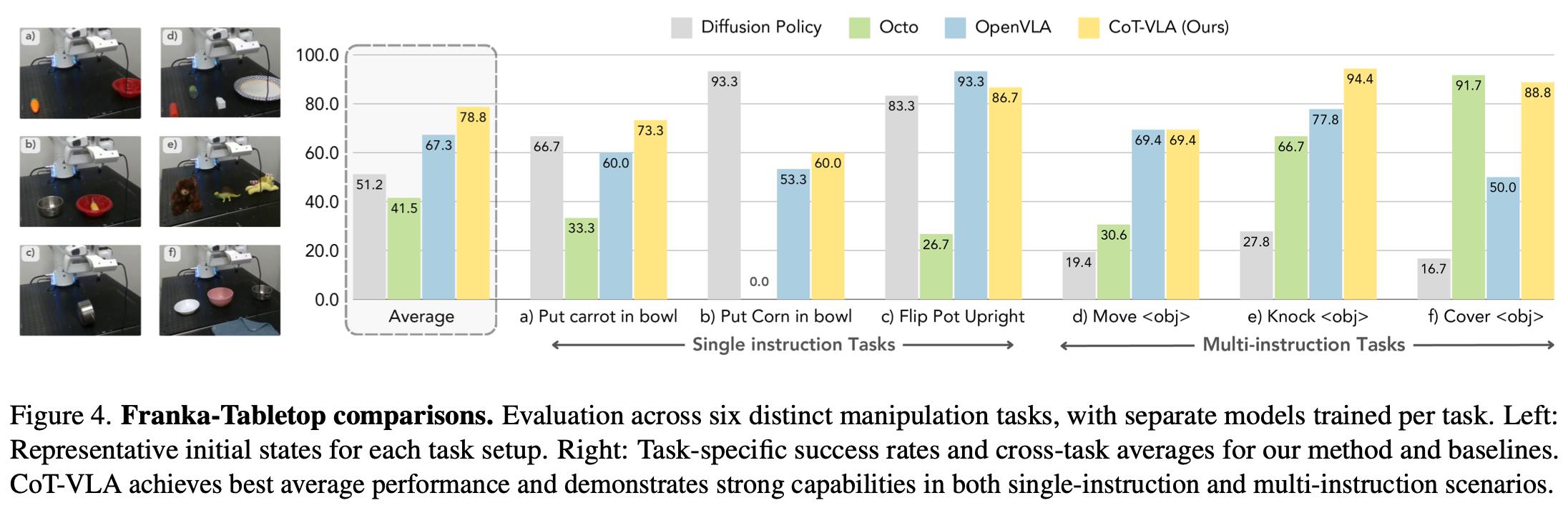
一个固定在桌面的 Franka Emika Panda 7 自由度机械臂,简称为 Franka-Tabletop。该硬件条件在预训练阶段不提供给模型,旨在通过少量机器人演示来评估模型对全新真实环境的适应能力。针对 6 项任务进行评估:3 个窄域单指令任务、 3 个不同的多指令任务(Fig.4 所示),每个任务的数据集包含 10 到 150 个演示。
Baselines
对比四个SOTA基线来评估模型:
Diffusion Policy一种最先进的模仿学习算法,在LIBERO和Franka-Tabletop中针对每个测试场景从头开始训练,该方法结合了动作分块和本体感觉,同时以DistilBERT语言嵌入为条件;OpenVLA一个开源 VLA 模型,可在OpenX数据集上微调预训练的VL;Octo一个在OpenX上预训练的通用模型,无需 VLM 初始化。对于OpenVLA和Octo,都使用它们已发布的checkpoint 进行Bridge-V2评估,并针对LIBERO和Franka-Tabletop对其进行微调;SUSIE是一种两阶段方法,将用于目标生成的指令引导图像内容与用于动作生成的目标条件策略相结合,使用上述在Bridge-V2上发布的checkpoint来评估SUSIE。
4.2. Evaluations Results
LIBERO
Table.1 中展示了定量结果,其中每种方法在每个任务配置中进行了超过 500 次试验,使用了 3 个随机种子。成功率以平均值和标准误差表示。
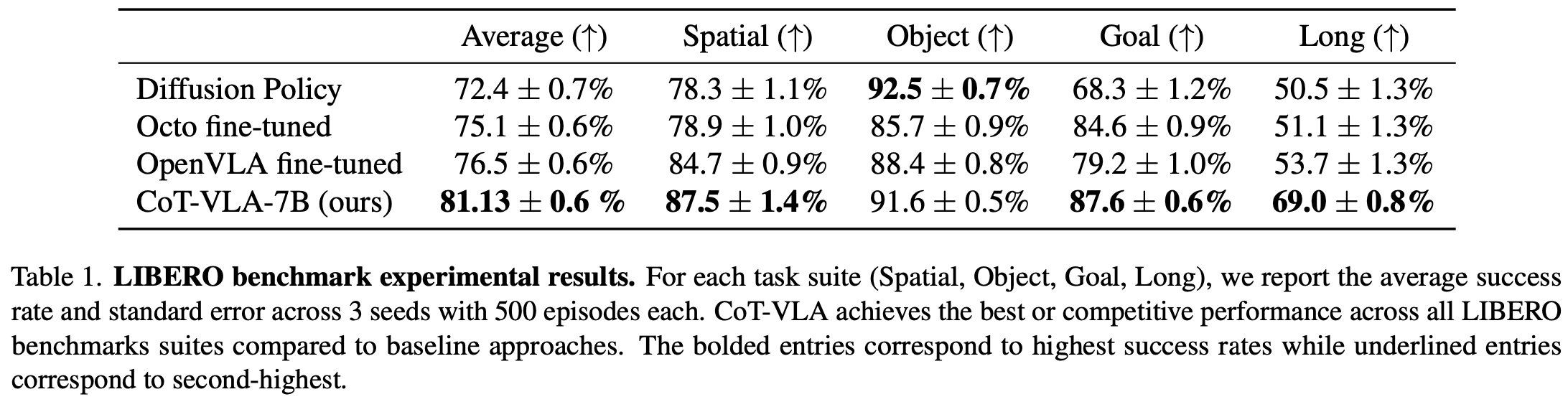
Fig.5 展示了模型的推理和执行轨迹的定性示例。结果表明,CoT-VLA 能够有效适应 LIBERO 模拟环境中的任务,与基线方法相比,取得了最佳或有竞争力的性能。通过分析失败案例的发现基线方法偶尔会过度拟合视觉提示,而忽略语言指令。例如,当初始状态在不同任务中看起来相似时(例如,在 LIBERO-Spatial 中)基线方法在某些场景中执行的任务与指令任务不同。CoT-VLA 通过首先通过基于语言的子目标生成对所需动作进行视觉推理,然后预测实现目标的相关动作,展现出更好的指令遵循能力。
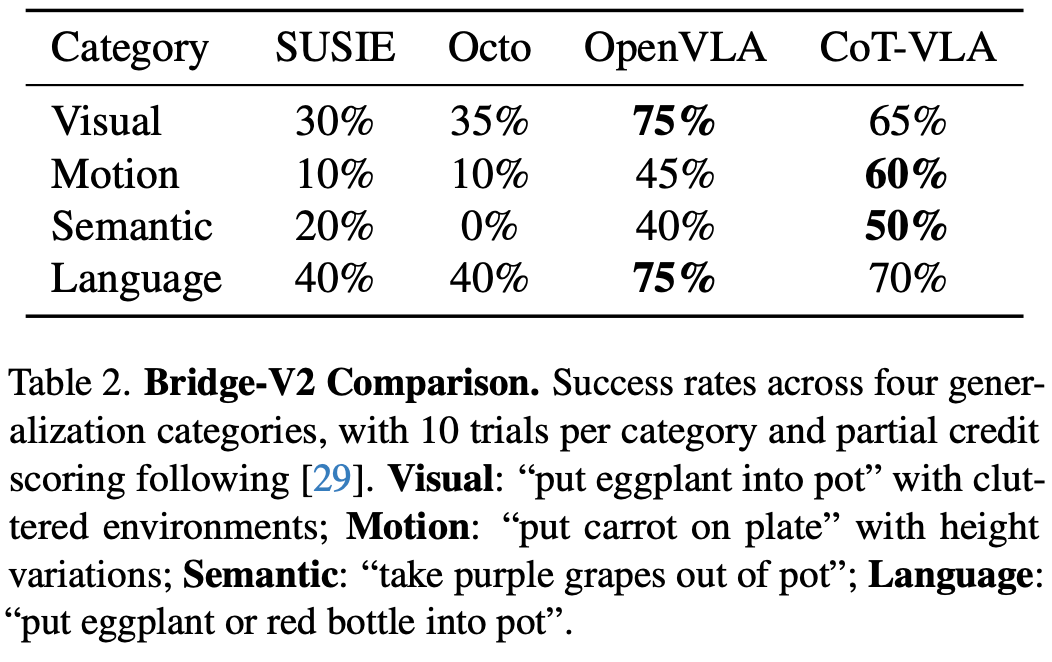
Bridge-V2
Bridge-V2 基准上针对四个泛化类别评估了 CoT-VLA 和基线:视觉泛化(“将茄子放入锅中”,环境杂乱)、运动泛化(“将胡萝卜放在盘子上”,高度变化)、语义泛化(“将紫葡萄从锅中取出”)、语言基础(“将茄子或红瓶子放入锅中”)。Table.2 展示了定量结果,其中每个任务经过 10 次试验。SUSIE 通过其扩散先验生成视觉上质量更高的目标图像,但在涉及新物体或需要复杂语言基础的任务上成功率较低。与 OpenVLA 相比,CoT-VLA 在视觉和语言泛化任务中的成功率略低,这是由于actino chunk 导致的抓取失败,而不是视觉推理中的错误。而CoT-VLA 在所有四个泛化类别中都表现出了竞争力,取得了与基线方法相当或更好的结果。
Franka-Tabletop
Table.4展示了定量结果,Figure.5 展示了评估执行轨迹(建议在其项目官网上查看对应的演示动画)。在本实验中模型在相对较小的演示集上进行了微调。虽然扩散策略在单指令任务(例如“将玉米放入碗中”)上取得了最佳性能,但在涉及多样化对象和复杂语言指令的多指令任务中性能出现下降。在 OpenX 数据集上预训练的模型Octo、OpenVLA 和 CoT-VLA 在语言基础的多指令任务中表现出更好的适应性和性能。总体而言,与基线方法相比 CoT-VLA 实现了最高的平均性能,在单指令和多指令场景中均有所提升。

4.3. Ablation Study
Visual CoT, Hybrid Attention, and Action Chunking
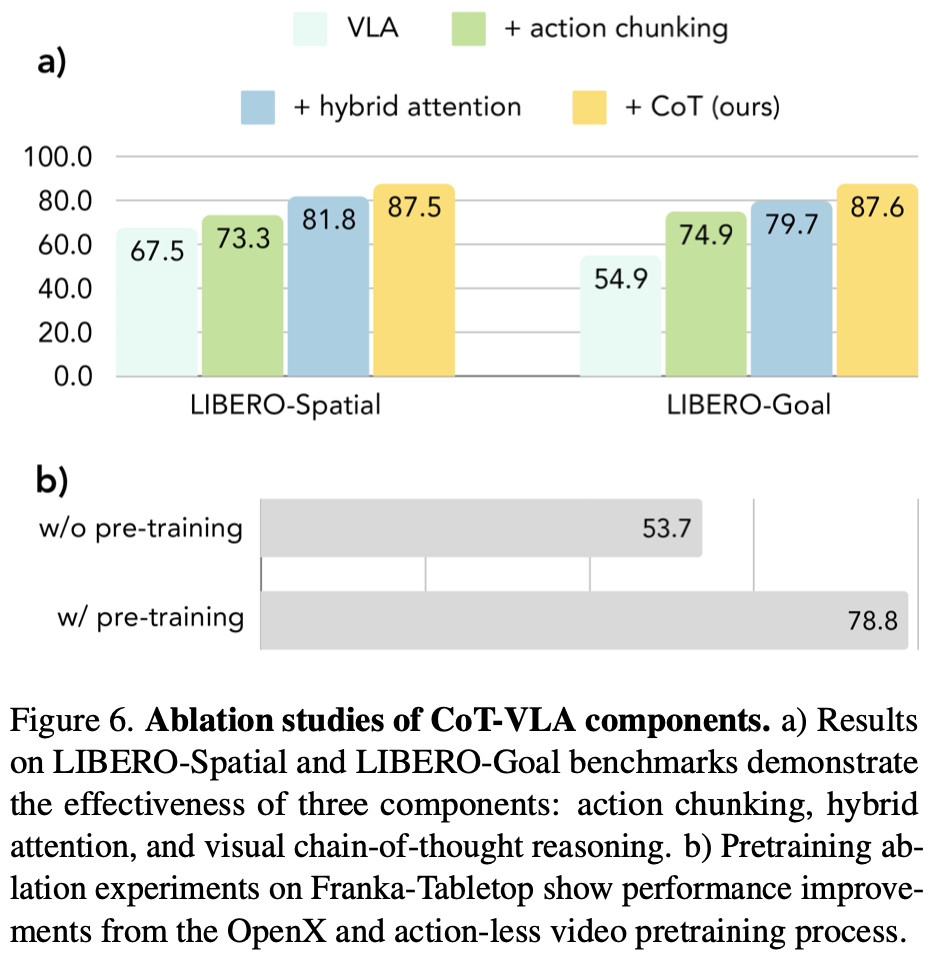
对两个 LIBERO 基准(LIBERO-Spatial 和 LIBERO-Goal)进行了全面的消融研究。评估了四种模型变体:
VILA-Ubackbone,但没有思路链推理和action chunk;- +长度为m的 action chunk 作序列;
- +混合注意,进一步添加用于动作序列预测的完整注意机制,如
Fig.3所示; - +
CoT完整方法,具有混合注意机制和视觉思路链推理;
如Fig.6 所示,两个基准测试均表明动作序列预测始终优于单个动作预测。混合注意力机制的加入进一步提升了性能。CoT-VLA 取得了最佳结果,验证了视觉思维链推理在 VLA 任务中的有效性。
Pretraining
训练流程分为两个阶段:
- 在
OpenX数据集上对VILA-U进行预训练(该数据集已添加无动作视频数据); - 在机器人演示数据上进行特定任务的后训练;
为了评估预训练阶段的重要性,在 Franka-Tabletop 数据集上进行了消融研究 (ablation studies) 如Fig.6所示。与直接在 Franka-Tabletop 演示数据集上微调基础 VILA-U 模型相比,预训练阶段的 CoT-VLA 实现了 46.7% 的相对提升,从 53.7% 提升至 78.8%,展现出更佳的下游任务适应性。
4.4. Better Visual Reasoning Helps
与之前的 VLA 在训练期间仅使用演示数据
D
r
D_{r}
Dr 不同,CoT-VLA 还利用无动作标签的视频数据
D
v
D_{v}
Dv 通过其中间视觉思维链推理步骤进行预训练,这使得仅从带字幕的视频中就可以学习动态和指令跟随,而带字幕的视频比机器人演示要丰富得多。为了研究视觉推理能力如何转移到机器人上,在 Franka-Tabletop 上结合两个未见过的长期任务进行了消融研究。设计了两个任务: “将绿色大葱移到苹果封面的书上”和 “将绿色花椰菜移到熊封面的书上” ,这些任务对模型的分布外泛化提出了挑战。对于每个任务,采集一个演示轨迹以获取真实目标图像。对两种条件下对每个任务进行了 5 次试验评估:(1)CoT-VLA 使用其生成的目标图像;(2)CoT-VLA 使用从收集的演示中得到的真实目标图像。如Table.3 所示,使用真实目标图像可将两个任务的绝对成功率提高 40%,表明视觉推理和目标图像生成方面的提升可以直接转化为更好的机器人任务性能。虽然模型在分布外的子目标生成方面仍然有困难,但大规模视频和图像生成模型的进步为视觉推理能力指明了方向。

5. Conclusion, Limitations and Future Work
在本研究中引入了 CoT-VLA,通过添加中间视觉目标作为明确的推理步骤,将VLA与思维链推理连接起来,使用从视频中采样的子目标图像作为可解释且有效的中间表示,而非使用bounding box或关键点等抽象表示。系统基于 VILA-U 构建,并在各种机器人操作任务中展现出强大的性能。
虽然模型证明了其有效性,但也存在以下局限性:
- 与直接动作生成方法相比,在推理过程中生成中间图像标记会带来显著的计算开销;模型需要在动作标记之前生成 256 个图像标记,当action chunk size 为 10 时,平均会导致速度降低 7 倍。虽然动作分块和并行解码提高了推理速度,但图像生成仍然是主要瓶颈;快速图像生成或快速 LLM 推理技术的发展可能会提高模型的吞吐量,并集成到该系统中;
- 与基于扩散的SOTA模型相比,模型自回归图像生成产生的视觉质量较低,统一多模态模型的最新进展为改进指明了方向;
- action chunk 方法虽然有效,但它会在组块之间引入不连续的动作,并且在执行过程中缺乏高频反馈。这些限制可以通过类似时间平滑技术和分步预测方法来解决;
- 虽然
CoT-VLA在预训练期间利用了无动作视频数据,但当前的计算限制限制了其在全新任务中实现视觉推理泛化的能力;
展望未来,作者相信视频/图像生成和世界模型方面的最新进展为通过改进视觉推理和预测模型来增强泛化能力提供了良好的机会。

















 2891
2891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









