







 这一小节我们将简单的阐述一般贝叶斯分类器设计的方法。分类器流程如下所示。输入:d-dim 特征向量计算决策函数值(针对每个类别)选取最大的值做出决策输出结果如下图可以清楚的表达整个分类器工作的流程。借用《算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)》的一张图来表示整个设计的流程。下面我们将以两个小例子来贯穿...
这一小节我们将简单的阐述一般贝叶斯分类器设计的方法。分类器流程如下所示。输入:d-dim 特征向量计算决策函数值(针对每个类别)选取最大的值做出决策输出结果如下图可以清楚的表达整个分类器工作的流程。借用《算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)》的一张图来表示整个设计的流程。下面我们将以两个小例子来贯穿...
这一小节我们将简单的阐述一般贝叶斯分类器设计的方法。分类器流程如下所示。
- 输入:d-dim 特征向量
- 计算决策函数值(针对每个类别)
- 选取最大的值
- 做出决策
- 输出结果
如下图可以清楚的表达整个分类器工作的流程。
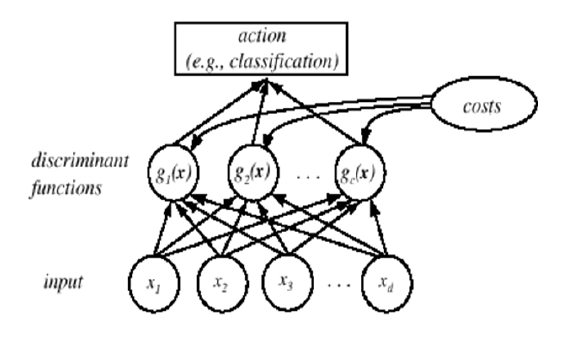
借用《算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)》的一张图来表示整个设计的流程。
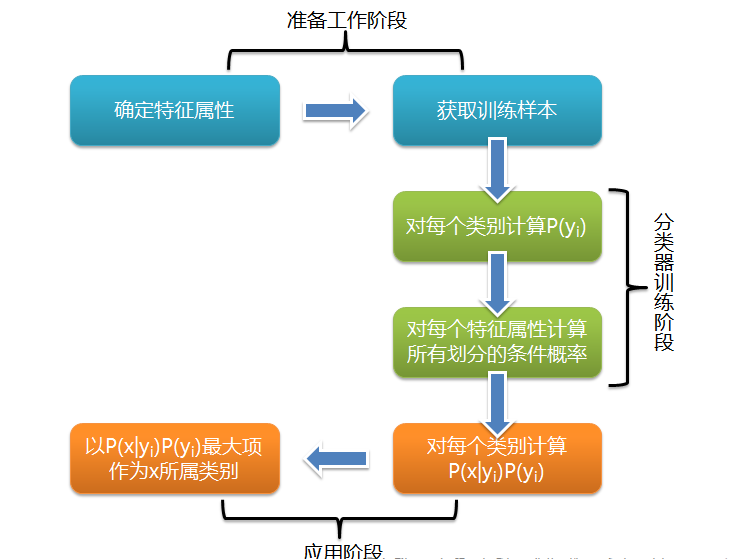
下面我们将以两个小例子来贯穿贝叶斯分类器设计的整个流程。
一、MNIST手写体识别
1.0 数据集简介
MNIST是一个0-9的手写数字数据库。MNIST数据集中包含60000张手写数字图片,10,000 张测试图片。每张图片的大小为28*28,包含一个手写数字。如下图所示。数据集链接:http://yann.lecun.com/exdb/MNIST/。

数据集中包含四个文件。
1. train-images-idx3-ubyte.gz: training set images (9912422 bytes)
2. train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
3. t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
4. t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
整理一下MNIST数据集。
- 四个文件。train_image,train_label,test_image,test_label
- 图像数据。28*28的图像尺寸的灰度图像,所以每张图像为28*28*1
- 标签。针对每个数据给出0-9中一个数字作为类别。
1.1、特征向量准备
搞个三部曲:
- 数据准备
- 模型设计
- 模型训练
贝叶斯决策论也不例外,首要的,我们需要将原始数据经过一系列清洗得到输入的特征向量。
咋输入数据?
MNIST数据集四个文件是用二进制进行编写,详细的格式如下图所示,展示image file 和 label file。

数据的预处理可以分为两部分:第一部分就是读入数据,第二部分就是提取成想要的特征向量。
(1)读入数据。实验中我们采用MATLAB编写,利用文件指针逐个字节读取,得到一个mat,然后reshape到784*N的数据形式,注意这里得到的都是0-255像素。对于label也是同理得到N*1的数据形式。
(2)提取特征向量。 最后我们需要对读入的数据进行处理得到我们想要的特征向量。这里实验做法十分暴力,直接将图像变成二值化(将0-255 resize到0、1),然后向量长度不变。所以得到的形式是784*N的二值化的矩阵。Label不做任何处理。
这里主要是阐述整个设计流程,所以直接用最简单的方式提取特征。感兴趣的同学可以尝试用PCA等特征生成的方式将输入的图像做特征提取。
1.2、决策函数设计
接下来是分类器设计的主要步骤:决策函数设计。首先我们从最顶层开始往下进行推导。贝叶斯分类的核心就是找到最大的后验概率,也就是给出一个样本 x x ,它属于 的概率最大,那么我们就认为样本 x x 是属于第 类的。由此我们的分类器设计的目标就是计算概率值 p(yj|xi) p ( y j | x i ) .
下面我们先给出形式化的定义。
- D=x(i),y(i),i=1,2,3,4……n D = x ( i ) , y ( i ) , i = 1 , 2 , 3 , 4 … … n 表示我们的数据集;
- x(i) x ( i ) 是784维的向量,表示第 i i 个样本;
- 是标注的第 i i 个样本的类别,取值范围是0-9;
- 表示第 i i 个样本的第 维。
决策函数定义
一般情况下,贝叶斯都是采用了最小错分准则,这里也是如此。由此我们可以得到我们的目标决策函数。
也就是说对于一个样本 x x ,我们只需要计算出它们属于每一类的后验概率,并将样本 判定给后验概率大的那一类 j j . 接下来我们就此解释该如何计算出这个后验概率,也就是模型的建立过程。
1.2.1 模型建立
根据最小错分原则,所以我们的目标就是求解最大的后验概率,由此得到结果类别。写成公式如下。
对于一个784维的样本 x x ,它的每一维出现是相互独立的(属性之间相互独立,也被称为朴素贝叶斯)。由此我们可以将我们目标后验概率写成如下公式。
其中:
- xk x k 表示样本 x x 的第 个元素
接下来转换目标为求解每个像素点的相应后验概率(也就是样本每个元素的后验概率)。根据贝叶斯公式,我们得到一个设计模型。该式子的意义为:针对一个样本 x x 的第 个元素出现,属于第 j j 类样本的概率。
这个模型非常好理解。我们要求的就是已知样本第 k k 个元素(像素)情况下,这个样本是属于第j类的概率。这个概率就可以用贝叶斯得到。由此我们通过训练样本可以得到如下概率值(因为我们的特征向量元素取值为0或者1)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3555
3555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









