






首先下载这个备份软件https://sourceforge.net/projects/areca/
这个安装还是比较简单的,就不细说了。
1.打开使用的时候,如果习惯为中文,可以在workspace里修改参数设置,改为中文。再重新开启一次工具就能变为中文界面了。
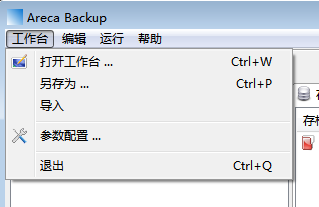
2.选择编辑-新目标任务出现下面的窗口-选择备份地址
目标名称可以随便取,选择本地存储位置(如果有远程备份需要可以选择FTP或SFTP存储)
存储模式之(1)标准:这是默认模式,建议大多数用户使用这个。选择这个模式,会为每个备份创建一个新的文档
(2)Delta:同样会为每个备份创建一个新文档。值得注意的是,它会将自上次备份后修改的部分存储在文档中,所以但当你准备备份一个特别大的文件的时候,建议使用这个模式。
(3)镜像:这个模式会为备份创建和更新唯一的文档
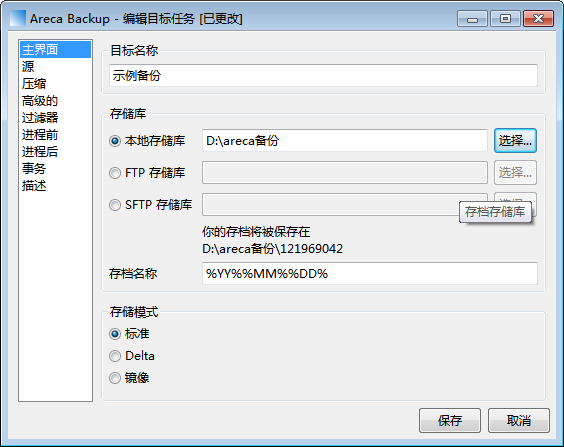
3.源,选择要备份的源文件
4.其余的压缩,高级的……因为我不常使用,所以在这里也就不多说了。
5.选择保存后,窗口中的即为要备份文件的信息,以及一些备份文件信息
需要强调的是,为了备份不出现以外,建议先模拟备份不要直接就备份。另外还有可能出现模拟备份完成,备份为红色发生错误的情况,这个时候可以通过查看日志了解具体错误发生在哪儿。
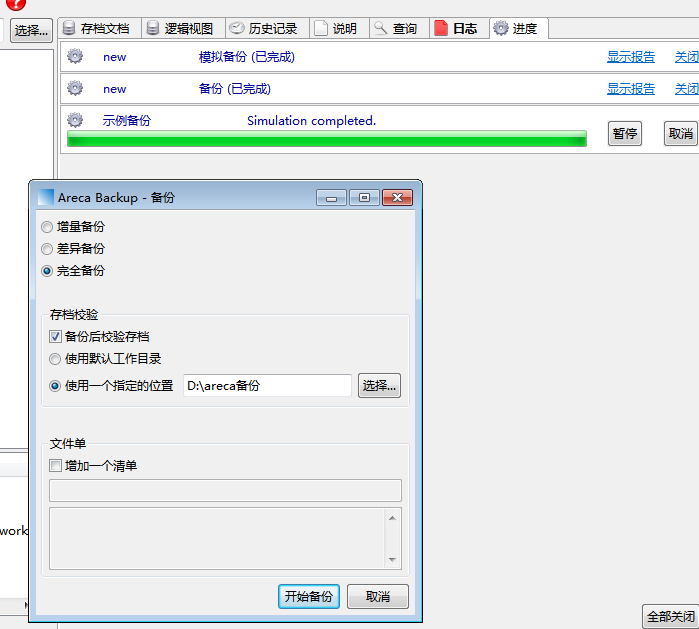
6.模拟备份后,第一次备份建议是完全备份
一般也把完全备份称为初始化备份;
而增量备份与之不同的是,增量备份备份的是在上一次备份之后发生过变化的文件(这个变化是和上一次备份比较)
差异备份:每次文件的变化都是和初始化状态(也就是完全备份时状态)的比较
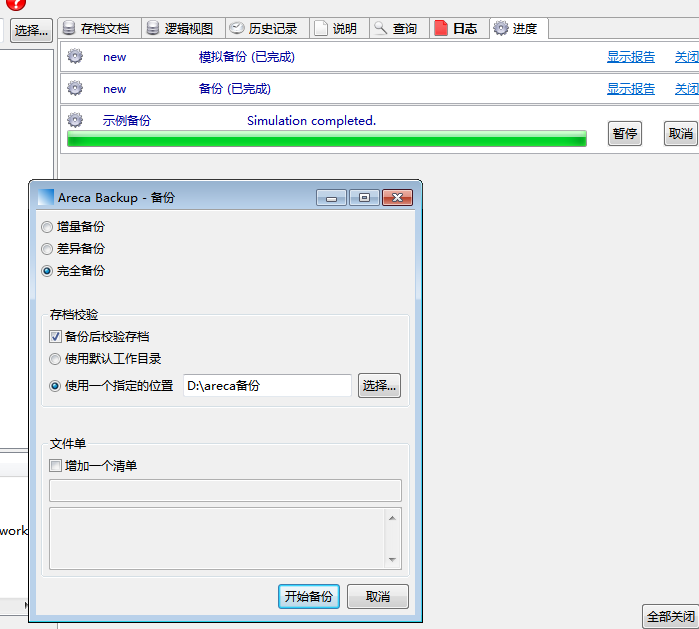
8.选择开始备份,之后就能看到备份成功了

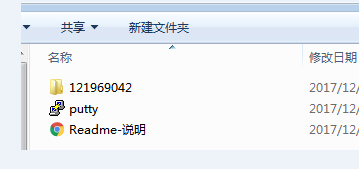
9.同样也能在你的存储位置找到这个备份好的文件了

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









