






一 题目背景
1.1 实验背景
作家风格是作家在作品中表现出来的独特的审美风貌。通过分析作品的写作风格来识别作者这一研究有很多应用,比如可以帮助人们鉴定某些存在争议的文学作品的作者、判断文章是否剽窃他人作品等。作者识别其实就是一个文本分类的过程,文本分类就是在给定的分类体系下,根据文本的内容自动地确定文本所关联的类别。 写作风格学就是通过统计的方法来分析作者的写作风格,作者的写作风格是其在语言文字表达活动中的个人言语特征,是人格在语言活动中的某种体现。
1.2 实验要求
- 建立深度神经网络模型,对一段文本信息进行检测识别出该文本对应的作者。
- 绘制深度神经网络模型图、绘制并分析学习曲线。
- 用准确率等指标对模型进行评估。
1.3 实验环境
重点使用到的python包:
import numpy as np
import torch
import jieba as jb
from transformers import BertTokenizer
二 实验内容
2.1 数据集
该数据集包含了 8438 个经典中国文学作品片段,对应文件分别以作家姓名的首字母大写命名。
数据集中的作品片段分别取自 5 位作家的经典作品,分别是:
| 序号 | 中文名 | 英文名 | 文本片段个数 |
|---|---|---|---|
| 1 | 鲁迅 | LX | 1500 条 |
| 2 | 莫言 | MY | 2219 条 |
| 3 | 钱钟书 | QZS | 1419 条 |
| 4 | 王小波 | WXB | 1300 条 |
| 5 | 张爱玲 | ZAL | 2000 条 |
2.2 数据预处理
使用 TF-IDF 算法统计各个作品的关键词频率
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索与文本挖掘的常用加权技术。
- TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
- TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
这里我们使用 jieba 中的默认语料库来进行关键词抽取,取出每位作家频率前500的词
# 词频特征统计,取出各个作家前 500 的词
high_words = set()
for label, text in enumerate(fragment): # 提取每个作家频率前500的词汇,不返回关键词权重值
for word in jb.analyse.extract_tags(text, topK=500, withWeight=False):
if word in high_words:
high_words.remove(word)
else:
high_words.add(word) # 将高频词汇存入
-
总共 5 个作者,每个作者的前 500 个最高词频的词作为特征,共 2500 维(或者小于 2500 维)
选用每个作者的前500个高频词汇是因为当选择高频词汇太少的时候,不能充分反映作者的特点,导致各个作者的区分度不高,最终模型准确率较低;但是当高频词汇选择太多的话作家之间的界限会模糊,导致分类失效。通过多次调整,最终确定选择500个高频词。
-
单独计算每个作者每一句话的这 500 维特征
-
去除作家中重复出现的高频词汇
jieba分词后,“我们”、“他们”等等的这类汉语常用词汇会大量的出现,这些词汇使用频率高但是机会所有作家都会大量用到这些词汇,这些词汇并不能够区分开各个作家,反而可能影响分类结果,所以选择将这些重复词汇去掉,只选用每个作家的独有词汇用于训练网络,以获取最大的特征。
-
用这个特征训练神经网络
2.3 搭建模型
详见***算法描述***部分
三 算法描述
3.1 pytorch网络搭建模型
3.1.1 建立number_to_word映射
将五位作者分别对应5个数字,便于后期各种操作。
number_to_word = list(high_words)
word_number = len(number_to_word) # 所有高频词汇的个数
word_to_number = {word: i for i, word in enumerate(number_to_word)} # 建立高频词汇字典,一一对应
3.1.2 划分数据集
在数据预处理的基础上,对读入的数据集进行划分,取出数据中的75%作为训练集,25%作为验证集;之后创建一个***DataLoader*** 对象。
# 划分数据集
valid_weight = 0.25 # 25%验证集
train_size = int((1 - valid_weight) * len(dataset)) # 训练集大小
valid_size = len(dataset) - train_size # 验证集大小
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, valid_size])
# 创建一个 DataLoader 对象
train_loader = data.DataLoader(train_dataset, batch_size=16, shuffle=True) # batch_size=16
valid_loader = data.DataLoader(test_dataset, batch_size=1000, shuffle=True) # batch_size=1000
3.1.3 确定训练模型、优化器、损失函数、学习率(最终确定版本及具体确定过程见4.1)
首先,我们使用Sequential 序贯模型,通过将层的列表传递给Sequential的构造函数,来创建一个Sequential模型。之后,在Sequential 序贯模型中使用`nn.Linear()`设置隐藏层;同时使用`nn.ReLU()`线性整流函数使输入小于0的值输出幅值为0,输入大于零的值幅值不变(激活函数)。
其次,使用`nn.CrossEntropyLoss()`计算交叉熵损失。
最后,构造优化器,使用使用`torch.optim`这一个实现了多种优化算法的包,之后调用`adam`算法,Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。它的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
神经网络结构如图所示:
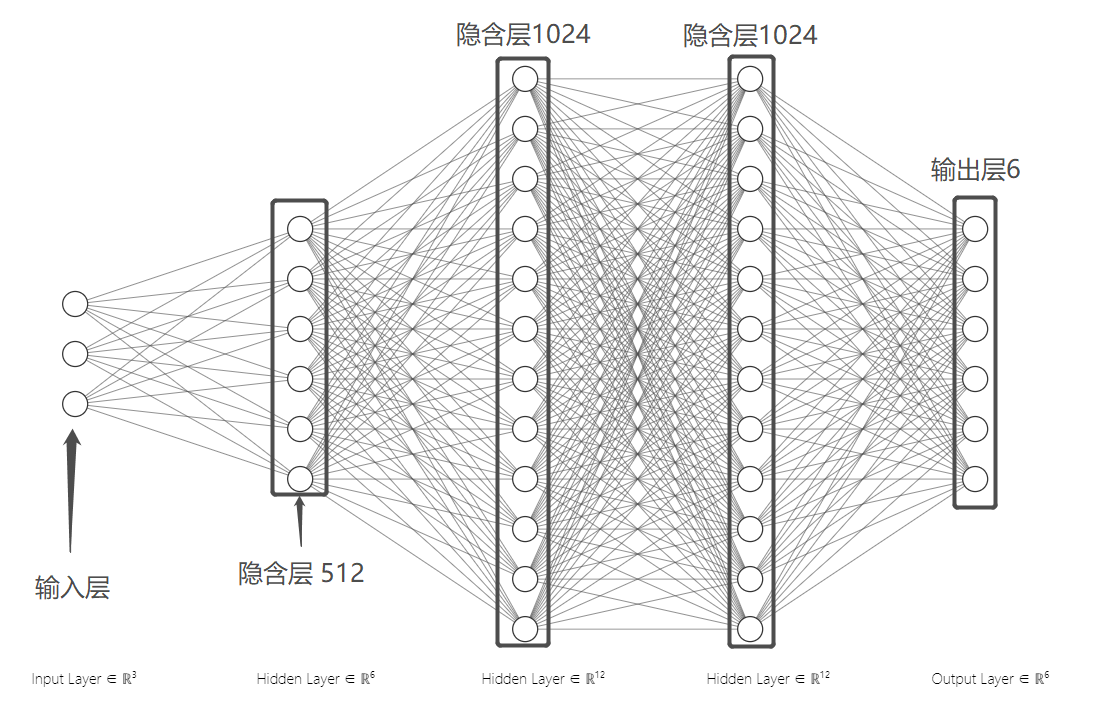

图1 神经网络模型图
神经网络包含三个隐藏层,输出层个数为六,包含五个作者和一个无法识别选项。三个隐含层神经元个数通过多次实验测试最终选定为1024、1024和1024,在此输入输出条件下正确率比其它条件略高。
初始学习率设定为1e-4,这是通过多次调整测试得到的当前情况下的一个最优值。
部分代码如下:
# 设定模型参数,使用ReLU作为激活函数,简单顺序连接模型
model = nn.Sequential(
nn.Linear(word_number, 512), # 三个隐含层神经网络,尝试(512,1024,1024)
nn.ReLU(), # 激活函数尝试ReLU,
nn.Linear(512, 1024),
nn.ReLU(),
nn.Linear(1024, 1024),
nn.ReLU(),
nn.Linear(1024, 6), # 最后一个隐含层不需要激活函数
).to(device)
epochs = 20 # 设定训练轮次
loss_fn = nn.CrossEntropyLoss() # 定义损失函数(尝试nn.CrossEntropyLoss()和nn.NLLLoss(),二者多用于多分类任务)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) # 定义优化器(adam),初始学习率为1e-4
best_acc = 0 # 优化器尝试RMSProp()、Adam()、Adamax()
history_acc = []
history_loss = []
best_model = model.cpu().state_dict().copy() # 最优模型
3.1.4 训练
共训练20轮,训练结束绘制`valid_loss`曲线和`valid_acc`曲线,并输出最佳准确率

图2 valid_loss/valid_acc曲线
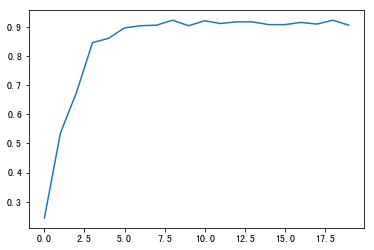
图3 valid_acc曲线
四 求解结果
4.1 pytorch模型
4.1.1 jieba分词选择:精确模式与搜索引擎模式
在其它条件相同的情况下(`epochs=20`,`Adam`,`nn.CrossEntropyLoss()`,`三个隐含层512,1024,1024`)尝试`jb.lcut_for_search()`搜索引擎模式和`jb.lcut()`精确分词模式
jb.lcut_for_search()训练20轮,正确率44/50
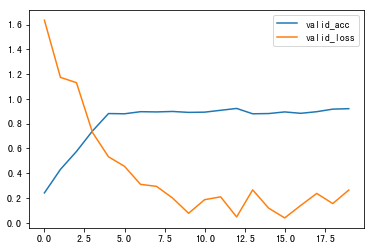
jb.lcut()训练20轮,正确率45/50
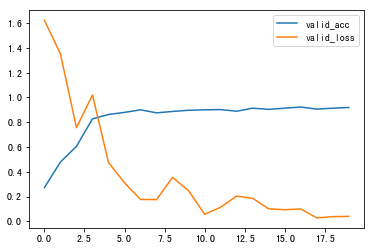
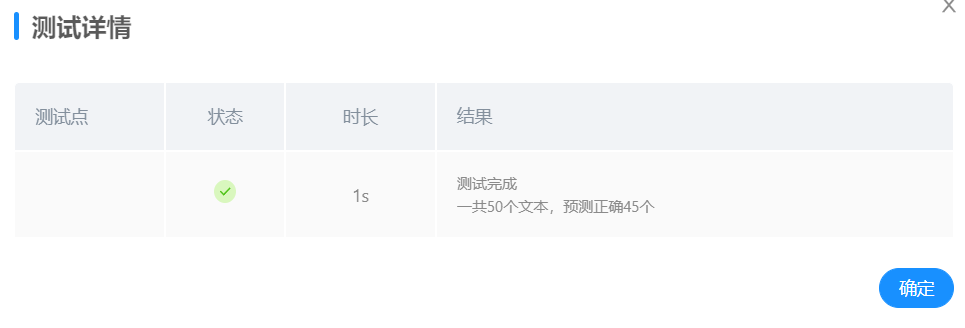
故后续使用精准模式探索最优参数条件。
4.1.2 损失函数选择
尝试`nn.CrossEntropyLoss()`和`nn.NLLLoss()`,二者多用于多分类任务
(Adam,三个隐含层512,1024,1024,jb.lcut())
nn.CrossEntropyLoss()训练20轮,正确率45/50
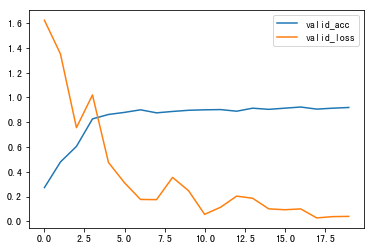
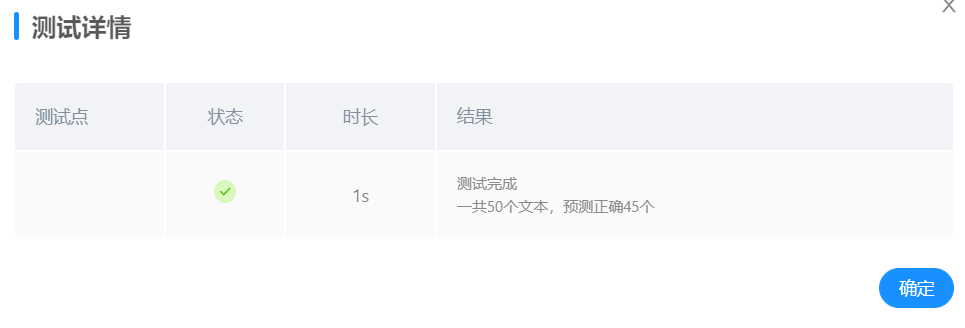
nn.NLLLoss()训练20轮,正确率10/50
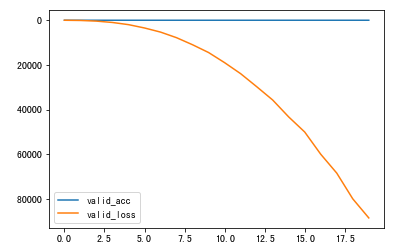
故最终选择`nn.CrossEntropyLoss()`作为损失函数
4.1.3 优化器选择
优化器尝试`RMSProp()`、`Adam()`、`Adamax()`
(nn.CrossEntropyLoss(),三个隐含层512,1024,1024,jb.lcut())
Adamax()训练40轮,测试正确率44/50
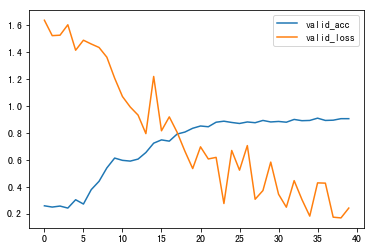
Adam()训练40轮,测试正确率45/50
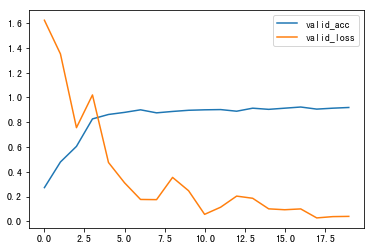
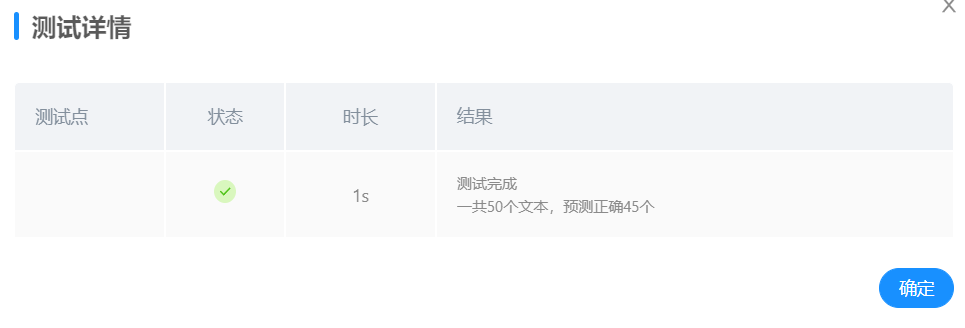
故最终选择`Adam()`作为优化器
4.1.4 分词个数以及batch size调整
由于删去了大量的重复分词,所以可以将分词个数加大以获取更多的特征,调整分词个数到500。同时发现,batch size调整到较小的数量时,最终的效果会更好,故调整batch size 到16,进行测试,结果如下:
http://www.biyezuopin.vip
分词500,batch size 32
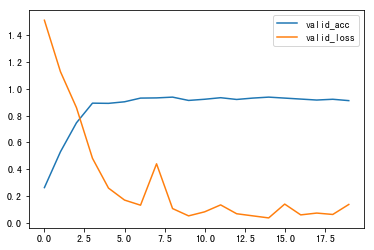
图6 valid_loss/valid_acc曲线
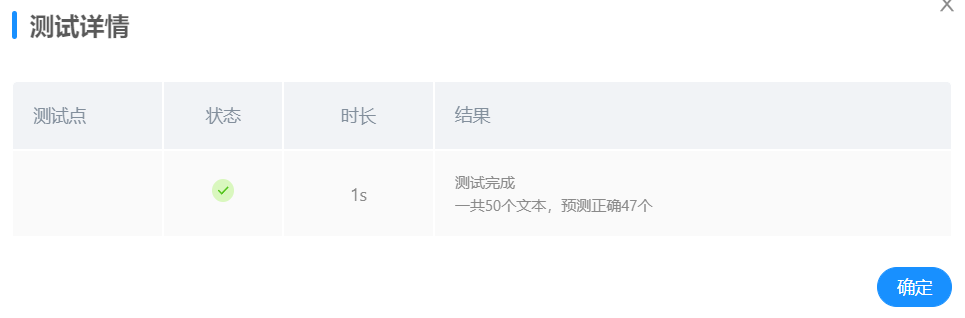
分词500,batch size 16

故最终选择分词个数为500个,batch size 16
4.1.5 model参数调整
通过多次测试对比,发现使用一个隐含层,隐含层单元个数为700的时候,选用ReLU作为激活函数,可以取到最佳的效果。
最终确定最优参数条件下训练40轮输出结果如下:
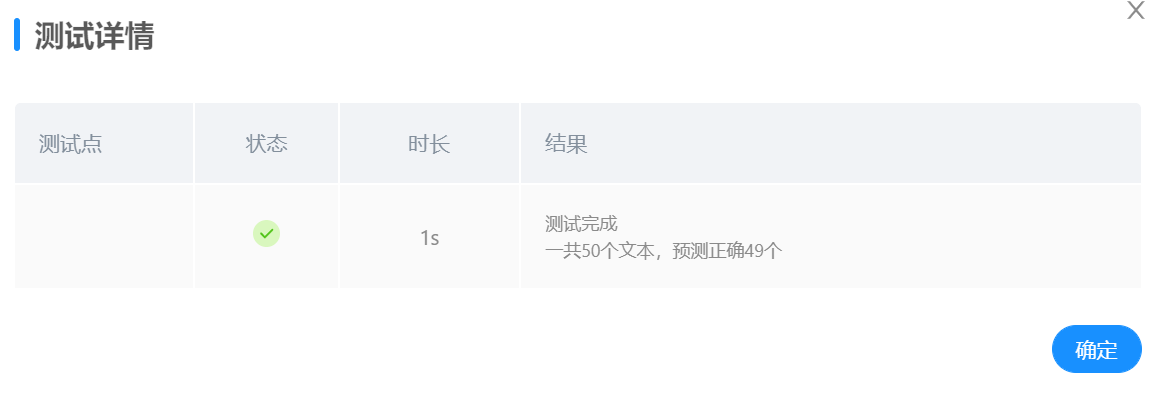
最终确定最优参数条件下训练60轮输出结果如下:
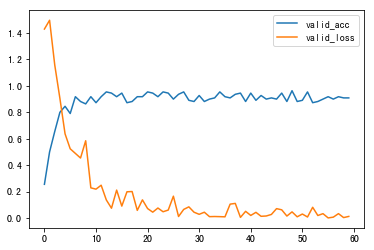
图5 valid_loss/valid_acc曲线
epoch:0 | valid_acc:0.2726
epoch:1 | valid_acc:0.4793
epoch:2 | valid_acc:0.6053
………………………………………………
epoch:58 | valid_acc:0.9435
epoch:59 | valid_acc:0.9592
best accuracy:1.0000
最终最佳准确率为100%,`accuracy`曲线逐渐趋近0.98,`loss`曲线逐渐趋近0,随着训练次数的增加,`loss`不断减小。
故最终确定参数为:
- 损失函数:
nn.CrossEntropyLoss() - 神经网络结构:
一个隐含层700 - 分词模式:
jb.lcut() - 优化器:
Adam() - 验证集占比:25%
- 训练轮次:60
- 分词个数:每个作家500,去除重复分词
- batch size:16
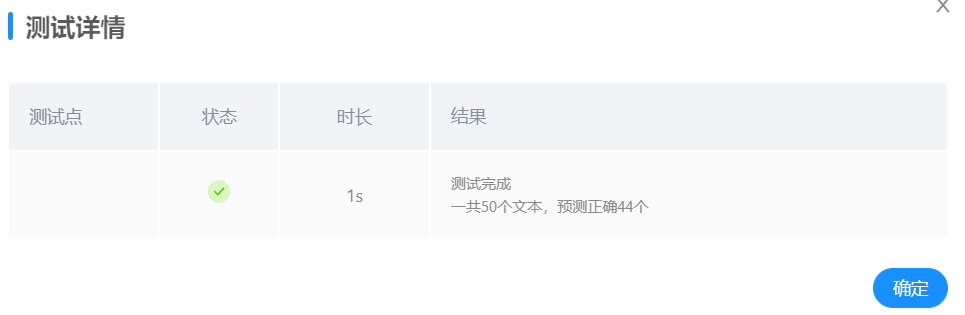
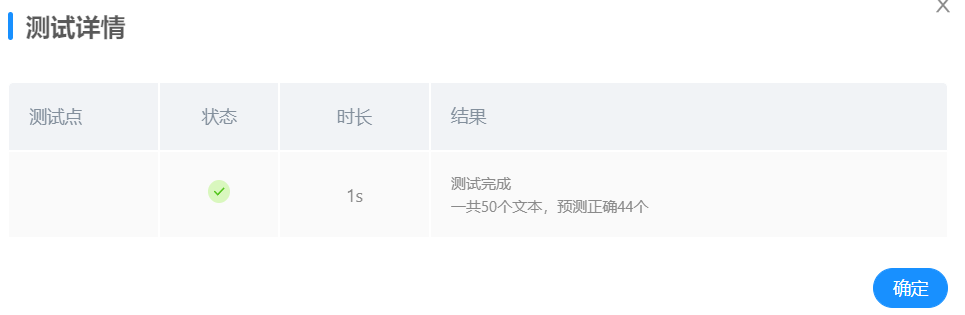
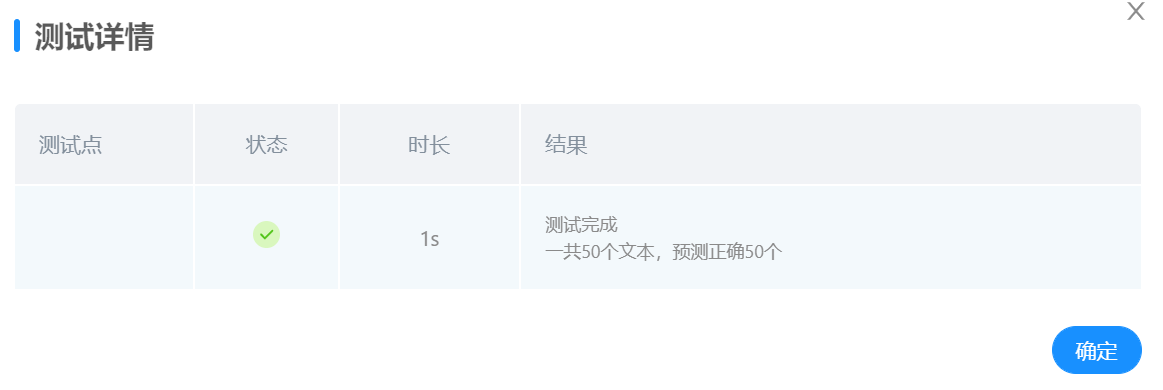
提交测试:
在系统中提交模型,在50个测试文本中,识别正确50个,准确率达到100%,效果与最终最佳准确率相近,效果良好。
五 比较分析
| best-Accuracy | valid-loss | 结果 | |
|---|---|---|---|
| 初始模型 | 94.55% | 0.065 | 44/50 |
| 优化模型 | 100% | 0.039 | 50/50 |
比较可知,基于各路优化模型效果稍微优于最初模型,最终测试集准确率可达***100%***。
六 心得与感想
本次实验过程中主要使用了基于***pytorch***的方法进行训练,由于初次使用这些方法,所以前期实现的过程相对困难。最初我想通过调用GPU资源来进行训练但是一直没有调用成功,所以退而求其次使用CPU进行训练,这就使得每次的训练时间都很长,调整参数的过程花费了很多的时间。虽然过程非常的辛苦,但最终的结果还是很不错的,最终整体全部正确,准确率还是很高的。总的来说在过程中收获还是很大的,受益匪浅。
源代码如下:
import os
import numpy as np
import jieba as jb
import jieba.analyse
import torch
import torch.nn as nn
from torch.utils import data
import matplotlib.pyplot as plt
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
number_to_author = ['LX', 'MY', 'QZS', 'WXB', 'ZAL'] # 作家集合
author_number = len(number_to_author) # 作家数量
author_to_number = {author: i for i, author in enumerate(number_to_author)} # 建立作家数字映射,从0开始
# 读入数据集
data_begin = [] # 初始数据集合
path = 'dataset/' # 数据路径
# path = 'test_data/test_case1_data/' # 数据路径
for file in os.listdir(path):
if not os.path.isdir(file) and not file[0] == '.': # 跳过隐藏文件和文件夹
with open(os.path.join(path, file), 'r', encoding='UTF-8') as f: # 打开文件
for line in f.readlines():
data_begin.append((line, author_to_number[file[:-4]]))
# 将片段组合在一起后进行词频统计
fragment = ['' for _ in range(author_number)]
for sentence, label in data_begin:
fragment[label] += sentence # 每个作家的所有作品组合到一起
# 词频特征统计,取出各个作家前 500 的词
high_words = set()
for label, text in enumerate(fragment): # 提取每个作家频率前500的词汇,不返回关键词权重值
for word in jb.analyse.extract_tags(text, topK=500, withWeight=False):
if word in high_words:
high_words.remove(word)
else:
high_words.add(word) # 将高频词汇存入
number_to_word = list(high_words)
word_number = len(number_to_word) # 所有高频词汇的个数
word_to_number = {word: i for i, word in enumerate(number_to_word)} # 建立高频词汇字典,一一对应
features = torch.zeros((len(data_begin), word_number))
labels = torch.zeros(len(data_begin))
for i, (sentence, author_belong) in enumerate(data_begin):
feature = torch.zeros(word_number, dtype=torch.float)
for word in jb.lcut(sentence): # jb.lcut 直接生成的就是一个list,尝试jb.lcut_for_search()搜索引擎模式和jb.lcut精确分词模式
if word in high_words:
feature[word_to_number[word]] += 1
if feature.sum():
feature /= feature.sum()
features[i] = feature
labels[i] = author_belong
else:
labels[i] = 5 # 表示识别不了作者
dataset = data.TensorDataset(features, labels)
# 划分数据集
valid_weight = 0.25 # 25%验证集
train_size = int((1 - valid_weight) * len(dataset)) # 训练集大小
valid_size = len(dataset) - train_size # 验证集大小
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, valid_size])
# 创建一个 DataLoader 对象
train_loader = data.DataLoader(train_dataset, batch_size=16, shuffle=True) # batch_size=16
valid_loader = data.DataLoader(test_dataset, batch_size=1000, shuffle=True) # batch_size=1000
# 设定模型参数,使用ReLU作为激活函数,简单顺序连接模型
model = nn.Sequential(
nn.Linear(word_number, 700), # 一个隐含层神经网络,尝试(700)
nn.ReLU(), # 激活函数尝试ReLU,
nn.Linear(700, 6),
# 最后一个隐含层不需要激活函数
).to(device)
epochs = 60 # 设定训练轮次
loss_fn = nn.CrossEntropyLoss() # 定义损失函数(尝试nn.CrossEntropyLoss()和nn.NLLLoss(),二者多用于多分类任务)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) # 定义优化器(adam),初始学习率为1e-4
best_acc = 0 # 优化器尝试RMSProp()、Adam()、Adamax()
history_acc = []
history_loss = []
best_model = model.cpu().state_dict().copy() # 最优模型
for epoch in range(epochs): # 开始训练
for step, (word_x, word_y) in enumerate(train_loader):
word_x = word_x.to(device) # 传递数据
word_y = word_y.to(device)
out = model(word_x)
loss = loss_fn(out, word_y.long()) # 计算损失
optimizer.zero_grad()
loss.backward() # 反向传播
optimizer.step()
train_acc = np.mean((torch.argmax(out, 1) == word_y).cpu().numpy())
with torch.no_grad(): # 上下文管理器,被包裹语句不会被track
for word_x, word_y in valid_loader:
word_x = word_x.to(device)
word_y = word_y.to(device)
out = model(word_x)
valid_acc = np.mean((torch.argmax(out, 1) == word_y).cpu().numpy()) # 准确率求平均
if valid_acc > best_acc: # 记录最佳模型
best_acc = valid_acc
best_model = model.cpu().state_dict().copy()
print('epoch:%d | valid_acc:%.4f' % (epoch, valid_acc)) # 展示训练过程
history_acc.append(valid_acc)
history_loss.append(loss)
print('best accuracy:%.4f' % (best_acc, ))
torch.save({
'word2int': word_to_number,
'int2author': number_to_author,
'model': best_model,
}, 'results/test1.pth') # 保存模型
plt.plot(history_acc,label = 'valid_acc')
plt.plot(history_loss,label = 'valid_loss')
plt.legend()
plt.show()

















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









