








一般意义上的long-tailed distribution 问题指的是样本标签不平衡的问题,具体表现为少量的标签拥有多数的样本,其余大量的标签所拥有的样本数量很少。long-tailed 问题训练与测试的设置为:在训练的时候,数据呈现长尾分布;在测试的时候,数据的标签分布均衡。 目前的研究对于长尾问题的主要思路是:re-sampling and cost-sensitive learning,一般解决方案主要包括:
1、重采样类
这类方法的主要思路是对样本数量较少的类进行过采样(over sampling);对样本数量较多的类进行欠采样(under sampling),从而使样本标签分布尽可能均衡。 重采样的应用方式主要有以下几种:
-
对多数类进行欠采样:如Random under-sampling、Tomek links...
-
对少数类进行过采样:如SMOTE
-
过采样+欠采样结合:如SMOTE+Tomek links
-
将重采样与集成方法结合:如Easy Ensemble classifier
2、损失敏感类方法
在模型训练过程中,对不平衡类别的样本施加不同的惩罚力度,使模型更容易学习到样本数量少的类别信息。 但是,由于数据的高度不平衡性,直接用样本倒数重新加权并不一定能得到令人满意的结果,近年来还有很多工作围绕平衡损失的方式:
-
Class-Balanced Loss这篇文章提出了一种新的理论框架来描述数据重叠,设计了一个在损失函数中加入与有效样本数成反比的类平衡重权项。【paper】【code】
-
Equalization Loss 这篇文章提出了一种简单的均衡损失,通过简单地忽略稀有类别的梯度来解决长尾问题。均衡损失保护稀有类别的学习在网络参数更新过程中处于劣势。因此,该模型能够为稀有类别的对象学习更好的判别特征。【paper】【code】
3、集成方法类
集成学习(boosting or bagging)通过训练多个分类器,然后结合这些分类器输出预测结果。通常与重采样一起使用。在每次训练时,使用tail class的样本,并且随机从head class的样本中抽取,这样反复多次的训练得到多个模型,在应用时,使用集成的方法产生最终的结果。
-
Easy Ensemble Classifier: 分类器是在不同的平衡样本集合上训练得到的AdaBoost学习器集合,平衡样本通过重采样的方法得到;
-
RUSBoost Classifier: 在执行提升迭代之前随机对数据集进行欠采样;
-
Balanced Bagging Classifier: 具有额外平衡的Bagging分类器;
-
Balanced RandomForest Classifier:平衡的随机森林分类器
4、利用异常检测或one-shot的思路
对于样本数量差别悬殊的类别,尤其是负例数量很少的情况,可以考虑利用异常检测算法,或者利用one-shot发的方法。
图上的长尾分布问题
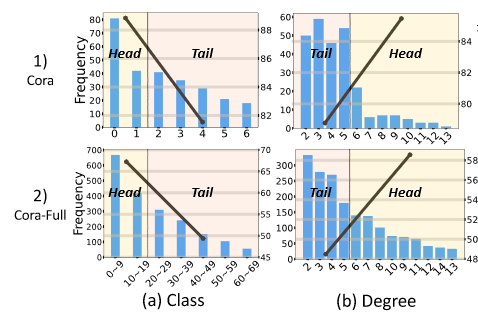
graph数据上的long-tail distribution 问题与常规欧式数据不同,包含了类别分布不均衡与节点度分布不均衡的情况,如下图所示:
下面介绍几个在graph long-tailed问题上的工作:
1、【KDD2021】Tail-GNN: Tail-Node Graph Neural Networks
本文主要解决的是graph上由于节点度分布不均衡带来的模型对tail-node关注度不高,在tail-node set 上表现不佳。
key idea: 本文认为模型在tail-node上学习到的表达相比head-node而言没有达到理想状态,并利用可学习的neighborhood translation model 来量化这种差异,因此目标是学习到这个翻译模型,并且利用它补全tail-node的表达。
toy example
如下图所示: 本文的目标函数综合了task loss/missing information constraint/adversarial constraint,是一个end-to-end的框架,整体框架如下图所示:
首先针对原图,根据预先定义的超参数K,区分tail-node(d_i<=K) 和 head-node (d_i > K),假设模型在head-node上学习到的表示h_v是理想的,
并且:其中r_{v}^{l}表示翻译模型的l层输出。在tail-node上,其与理想表达的差距可以表示为: 在训练的时候,可以对head-node通过随机删减边使其度小于K,变成tail-node,然后利用原来的理想表达来约束翻译模型参数的学习: r^l是对全局节点共享的参数,通过设计一个函数,使其自适应于各节点: 在网络各层可以利用个性化的翻译模型参数使节点表达翻译成理想表达。 整体目标函数包括:
-
Task Loss:如半监督节点分类任务的交叉熵损失
-
missing information constraint:

利用head-node的原始表达为理想表达,修改其连接成tail-node,以此来约束翻译模型的输出
-
adversarial constraint:利用GAN的思想,模型应该具有判别节点属于head/tail-node的能力。

whole loss:
2、【CIKM2022】LTE4G: Long-Tail Experts for Graph Neural Networks 【code】
本文首次将graph上的label imbalance 和 degree imbalance结合在一起考虑。根据节点的度以及所属标签的性质,将节点分为四类:HH(Head-class, Head-degree),HT, TH, TT(Tail-class, Tail-degree)。为了探索label和degree之间的相互影响关系,本文在cora-full数据集上进行了探索性实验,如下图所示:

有如下发现:
-
head-degree node将会取得更好的分类结果,尽管它属于tail-class;
-
head-degree不会一直取得好的结果,如果类别样本数量很少的话。
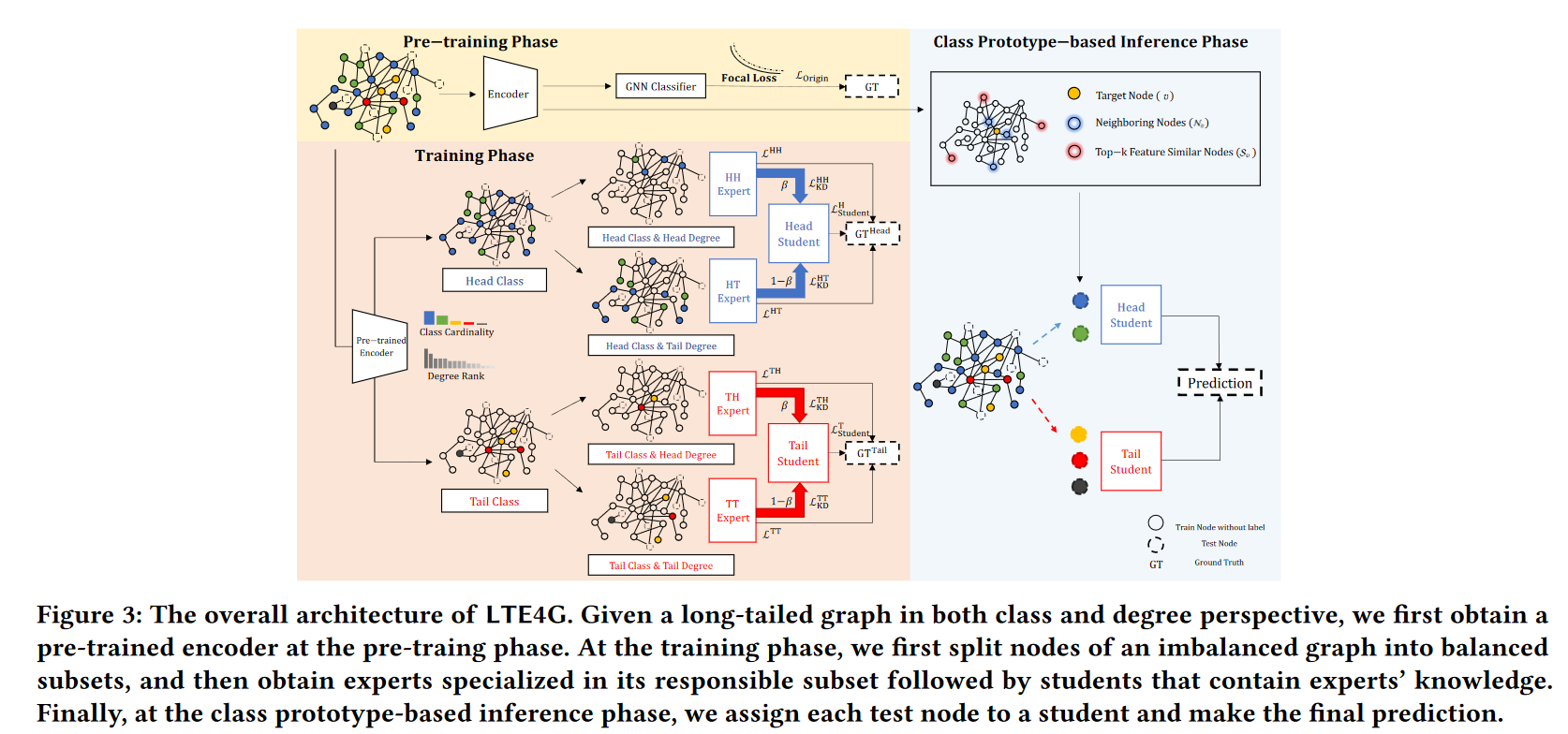
本文利用知识蒸馏的策略,根据划分的四个子集,分别学习到四个teacher model,并将其知识蒸馏给两个学生,分别是:Head-class student, Tail-class student。整体框架如下:
-
首先利用focal-loss预训练一个GNN当作特征提取器,分别提取四个子集的特征;
-
针对四个教师模型,分别使用对应子集的交叉熵损失进行训练;
-
Head-class的教师知识蒸馏给Head-student,Tail-class的教师知识蒸馏给Tail-student(KL),学生模型的目标函数还要加上Task loss,因此学生模型的目标函数为:















 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









