







数据探索
pandas的数据可视化
groupby 的使用
转载自链接: 超好用的 pandas 之 groupby
首先介绍一下,data是一个dataframe的一个数据。
什么是groupby
groupby就是按xx分组, 它也确实是用来实现这样功能的. 比如, 将一个数据集按A进行分组, 效果是这样
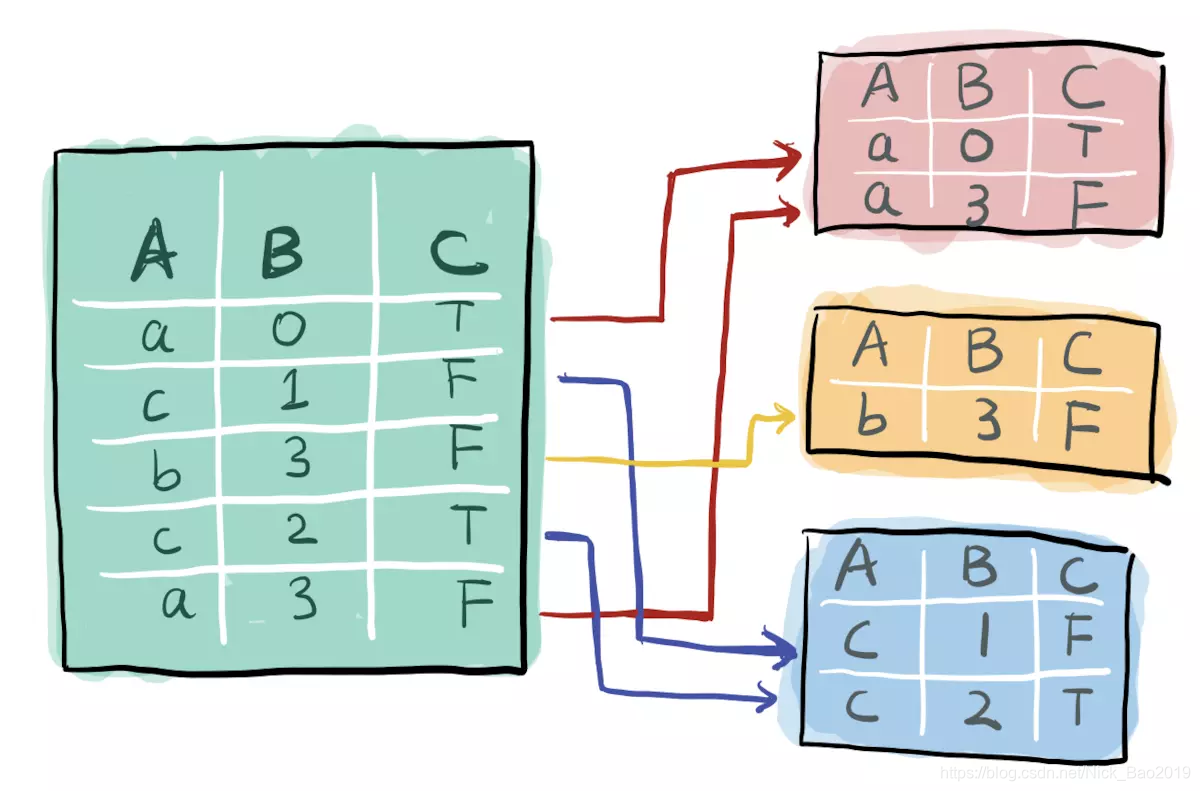
dataframe的groupby函数需要选定一个列作为分组的依据,这里使用A列(“race”)来进行分组。
// group by "race"
data.groupby("race")
<pandas.core.groupby.DataFrameGroupBy object at 0x104fa2208>
这里我们得到了一个叫DataFrameGroupBy的东西, 虽然 pandas 不让我们直接看它长啥样, 但是你将它想象成上面那幅分组后的图(简书多才多艺的小姐姐手绘的)是完全没有问题的.
基本操作
最基本的就是组内计数, 求和, 求均值, 求方差, 求blablabla…
比如, 要求被不同种族内被击毙人员年龄的均值:
data.groupby('race')['age'].mean()
race
A 36.605263
B 31.635468
H 32.995157
N 30.451613
O 33.071429
W 40.046980
Name: age, dtype: float64
上面我们求得了各个种族中被击毙的人员的平均年龄, 得到的是一个Series, 每一行对应了每一组的mean, 除此之外你还可以换成std, median, min, max这些基本的统计数据。
上面age是连续属性, 我们还可以操作离散属性, 比如对不同取值的计数: .value_counts()
以下尝试求不同种族内, 是否有精神异常迹象的分别有多少人
data.groupby('race')['signs_of_mental_illness'].value_counts()
ace signs_of_mental_illness
A False 29
True 10
B False 523
True 95
H False 338
True 85
N False 23
True 8
O False 21
True 7
W False 819
True 382
Name: signs_of_mental_illness, dtype: int64
注: 这时, 组内操作的结果不是单个值, 是一个序列, 我们可以用.unstack()将它展开
data.groupby('race')['signs_of_mental_illness'].value_counts().unstack()

方法总结
首先通过groupby得到DataFrameGroupBy对象, 比如data.groupby(‘race’)
然后选择需要研究的列, 比如[‘age’], 这样我们就得到了一个SeriesGroupby, 它代表每一个组都有一个Series
对SeriesGroupby进行操作, 比如.mean(), 相当于对每个组的Series求均值
注: 如果不选列, 那么第三步的操作会遍历所有列, pandas会对能成功操作的列进行操作, 最后返回的一个由操作成功的列组成的DataFrame
可视化
场景一: 不同种族中, 逃逸方式分别是如何分布的?
(属性A的不同分组中, 离散属性B的情况是怎么样的 )
- 一种传统做法是:
1、遍历每个组
2、然后筛选不同组的数据
3、逐个子集画条形图 (或者其他表示)
但是使用Groupby能让我们直接免去循环, 而且不需要烦人的筛选, 一行就完美搞定。
data.groupby('race')['flee'].value_counts().unstack().plot(kind='bar', figsize=(20, 4))
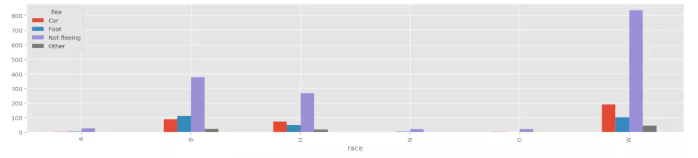
方法总结
- 首先, 得到分组操作后的结果data.groupby(‘race’)[‘flee’].value_counts()
- 这里有一个之前介绍的.unstack操作, 这会让你得到一个DateFrame, 然后调用条形图,
pandas就会遍历每一个组(unstack后为每一行), 然后作各组的条形图
场景二: 按不同逃逸类型分组, 组内的年龄分布是如何的?
(属性A的不同分组中, 连续属性B的情况是怎么样的)
data.groupby('flee')['age'].plot(kind='kde', legend=True, figsize=(20, 5))
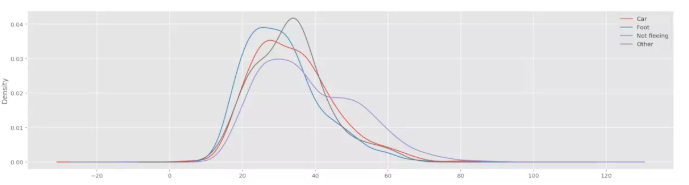
方法总结
这里data.groupby(‘flee’)[‘age’]是一个SeriesGroupby对象, 顾名思义, 就是每一个组都有一个Series. 因为划分了不同逃逸类型的组, 每一组包含了组内的年龄数据, 所以直接plot相当于遍历了每一个逃逸类型, 然后分别画分布图.
pandas 会为不同组的作图分配颜色, 非常方便。
场景三: 有时我们需要对组内不同列采取不同的操作
比如说, 我们按flee分组, 但是我们需要对每一组中的年龄求中位数, 对是否有精神问题求占比
这时我们可以这样做
data.groupby('race').agg({'age': np.median, 'signs_of_mental_illness': np.mean})
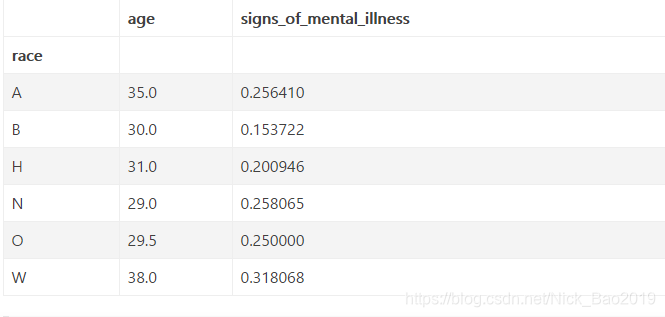
方法总结
这里我们操作的data.groupby(‘race’)是一个DataFrameGroupby, 也就是说, 每一组都有一个DataFrame
我们把对这些DataFrame的操作计划写成了了一个字典**{‘age’: np.median, ‘signs_of_mental_illness’: np.mean}, 然后进行agg**, (aggragate, 合计)
然后我们得到了一个DataFrame, 每行对应一个组, 没列对应各组DataFrame的合计信息, 比如第二行第一列表示, 黑人被击毙者中, 年龄的中位数是30, 第二行第二列表示, 黑人被击毙者中, 有精神疾病表现的占15%
场景四: 我们需要同时求不同组内, 年龄的均值, 中位数, 方差
data.groupby('flee')['age'].agg([np.mean, np.median, np.std])
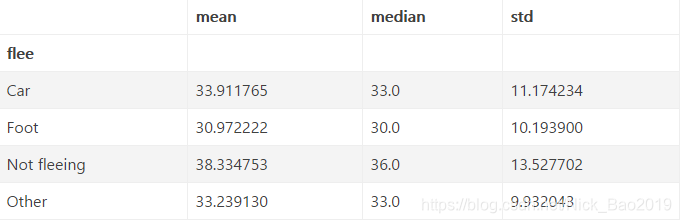
方法总结
现在我们对一个SeriesGroupby同时进行了多种操作. 相当于同时得到了这三行的结果:
data.groupby('flee')['age'].mean()
data.groupby('flee')['age'].median()
data.groupby('flee')['age'].std()
场景五: 结合场景三和场景四可以吗?
答案是肯定的, 请看
data.groupby('flee').agg({'age': [np.median, np.mean], 'signs_of_mental_illness': np.mean})
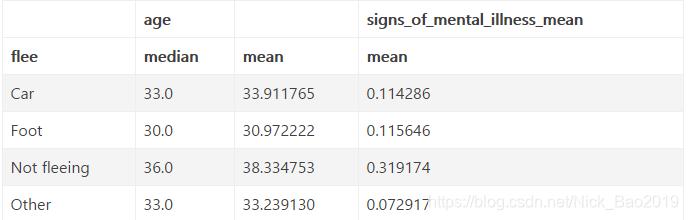
但是这里有一个问题, 这个列名分了很多层级, 我们可以进行重命名:
agg_df = data.groupby('flee').agg({'age': [np.median, np.mean], 'signs_of_mental_illness': np.mean})
agg_df.columns = ['_'.join(col).strip() for col in agg_df.columns.values]
agg_df
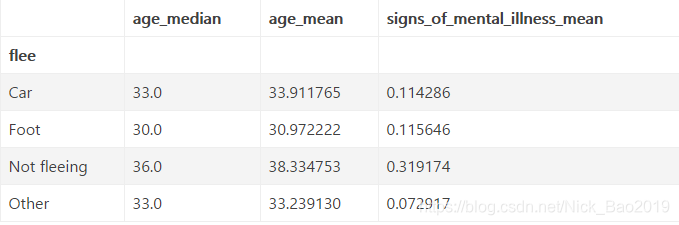
方法总结
注意这里agg接受的不一定是np.mean这些函数, 你还可以进行自定义函数哦
简单的对各个特征进行绘图操作
features = train.columns[1:-1]
for feature in features:
train[[feature,'Label']].groupby([feature]).mean().plot.bar()
这样可以把一个个特征图进行画出来,有些图不准确,但是只是做个大概的了解。
subplot 的使用
fig, ax_lst = plt.subplots(2,2)
ax_lst[0,0].plot(train.groupby('EnvironmentSatisfaction')["Label"].mean())
ax_lst[0,1].plot(train.groupby('Gender')["Label"].mean())
ax_lst[1,0].plot(train.groupby('WorkLifeBalance')["Label"].mean())
ax_lst[1,1].plot(train.groupby('Department')["Label"].mean())
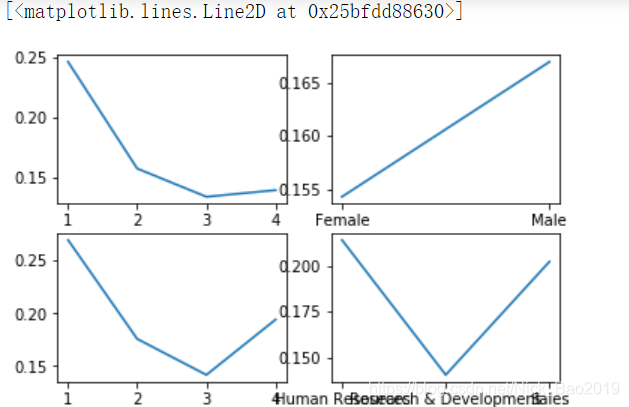
不能分清楚哪个是哪个特征,简单看看这个用法就好。
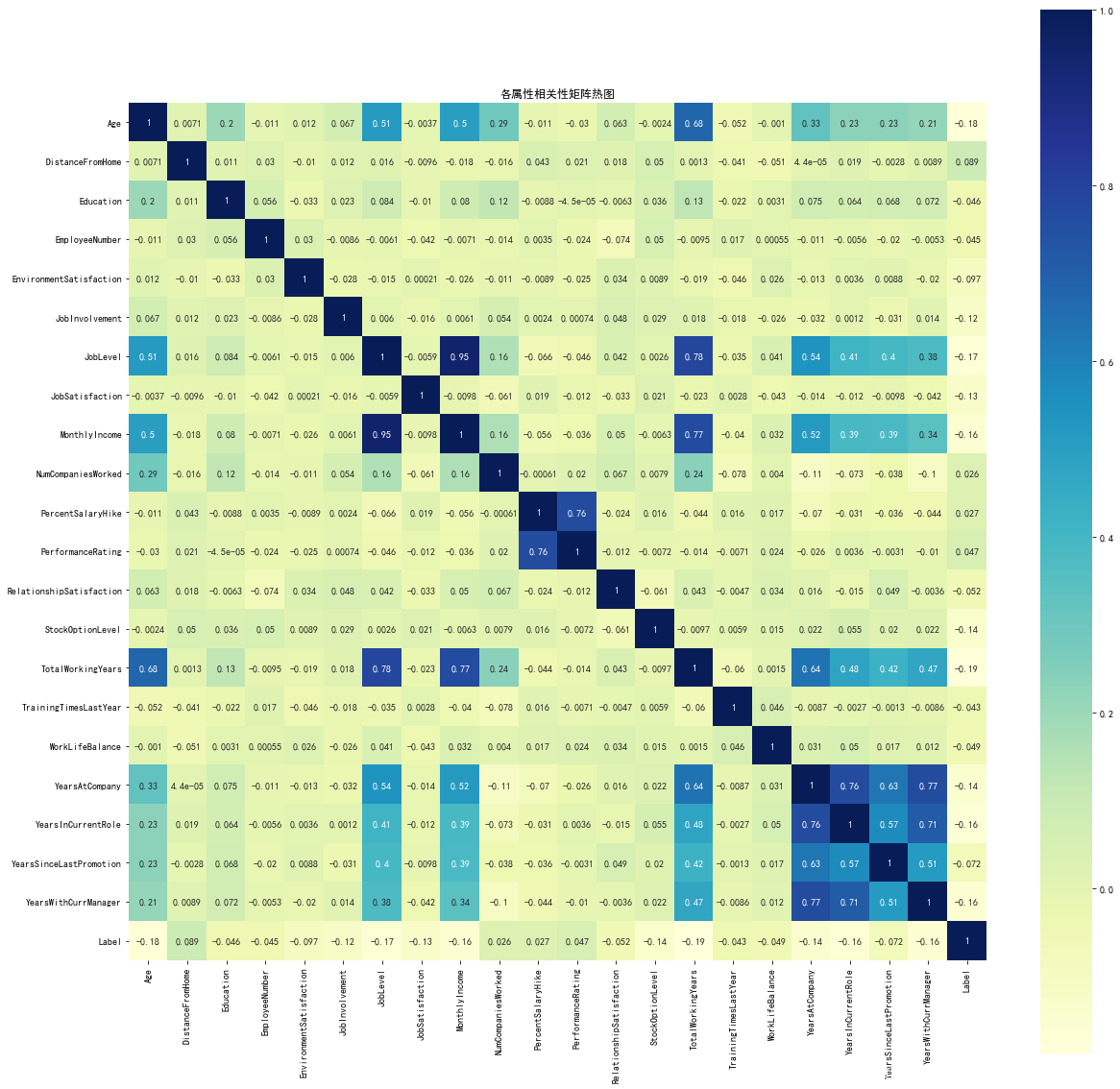
相关矩阵热力图
import seaborn as sns
#其他的我就不解释了
#配置中文显示信息
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
train_corr=train.corr()#得到相关系数
plt.figure(figsize=(20,20))
sns.heatmap(train_corr,annot=True,square=True,cmap="YlGnBu")
#显示相关系数 #正方形 #黄绿蓝
plt.title('各属性相关性矩阵热图')
显示结果如下
小结
Groupby 可以简单总结为 split, apply, combine, 也就是说:
- split : 先将数据按一个属性分组 (得到 DataFrameGroupby / SeriesGroupby )
- apply : 对每一组数据进行操作 (取平均 取中值 取方差 或 自定义函数)
- combine: 将操作后的结果结合起来 (得到一个DataFrame 或 Series 或可视化图像)
pandas 数据预处理
查看读取的数据的基本信息
import pandas as pd
train = pd.read_csv("your path like D:\deeplearning_code_pratice\final_test\data_train.csv")
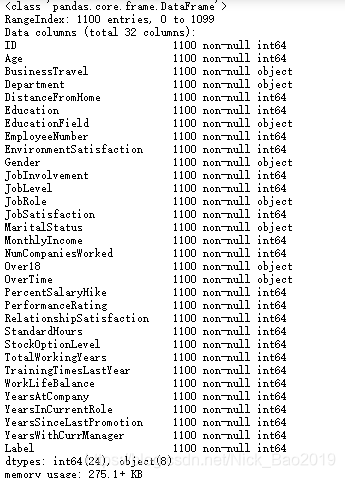
train.info()
train.describe()
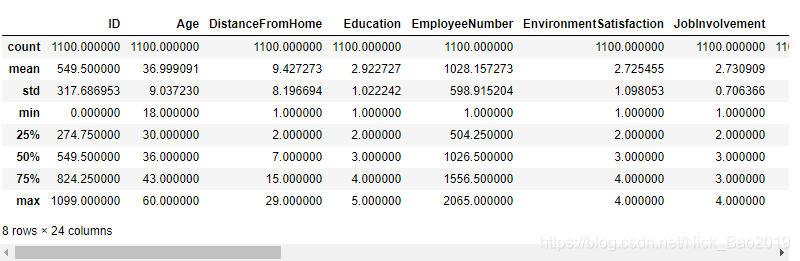
观察上述两个结果,可以知道:
**info()**显示的结果是非缺失个数,以及特征的类型。
**describe()**显示的结果是一些统计指标信息。
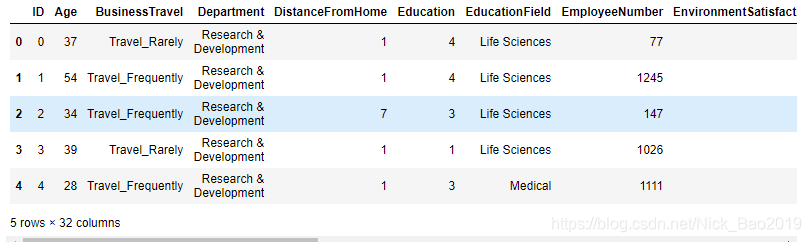
显示前n个样本,默认为5个样本
train.head(n)
for column in train.columns:
print(column)
print(train[column].unique())
print("\n")
遍历出每个column的取值,如果是唯一取值则可以删去
train["Over18"].value_counts().sort_index()
对over18这一列进行取值上的count,有多少不同的类,每类又取多少个值。
删除不必要的列
经过上面的信息查看可以发现ID是无效信息, “Over18”, "StandardHours"是唯一取值的特征也可以删去。
train.drop(["ID", "Over18", "StandardHours"], axis = 1, inplace= True )
axis = 1删除列, axis = 0 删除行。别忘记inplace,是否在元数据上进行操作。
对文本分类进行硬编码
自写了一个函数进行硬编码
def label_encode(train = None, label = None , test = None):
"""
label hard encoded
"""
columnMap = {elem:idx+1 for idx, elem in enumerate(train[label].unique())}
if test is None:
train[label] = train[label].map(columnMap)
print(label + " has been encoded!")
print(train[label].value_counts())
else:
test[label] = test[label].map(columnMap)
print(label + " has been encoded!")
print(test[label].value_counts())
利用info()里面特征类别的信息来使用这个函数进行硬编码。(命名和效率可能不太好,但是只是自用的,仅供参考,大家可以自行设置)
第一次发blog 其实是总结一些东西方便自己查阅,也希望能帮助到大家吧。也希望能慢慢提高自己整理和总结的能力,一起加油。(转载的我标记了出处,如果有什么地方有问题,请及时联系,新手上路多加包含)














 408
408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









