







1 LabelImage简介
LabelImg 是一个可视化的图像标定工具。Faster R-CNN,YOLO,SSD等目标检测网络所需要的数据集,均需要借此工具标定图像中的目标。生成的 XML 文件是遵循 PASCAL VOC 的格式的。
2 LabelImg下载安装
(1)打开Anaconda Prompt 终端,输入 conda list 发现已经安装了lxml 和pyqt5.6版本,OK。若未安装,运行 conda install pyqt=5 ,安装。
(2)下载labelImage源代码并运行:
下载地址:https://github.com/tzutalin/labelImg
下载后并解压得到文件夹labelImg-master (记住文件夹位置)。
在labelImg-master文件夹下,shift+右键,打开power shell窗口(‘在此处打开命令窗口’选项),然后输入:
pyrcc5 -o resources.py resources.qrc
python labelImg.py
即可打开窗口。
注:其中第二步可能出现no module named libs.resources的错误

**解决方法:**将生成的resources.py拷贝到同级的libs目录下
(3)窗口如下图所示:

3 LabelImg的使用
3.1 操作过程
单张图片:
“open file ” -----"create rectbox " -----"输入类别名称 "-----“change save dir ”-----“Save”
多张图片:
可以open dir先打开一个文件夹,然后change save dir 选择需要存储的文件夹,其余操作如上,保存后即可Next Image跳下一张。
最后在保存文件的路径下生成.xml文件,.xml文件的名字是和标注照片的名字一样,如果要修改已经标注过的图像,.xml中的信息也会随之改变。得到的.xml 和PASCAL VOC所用格式相同。
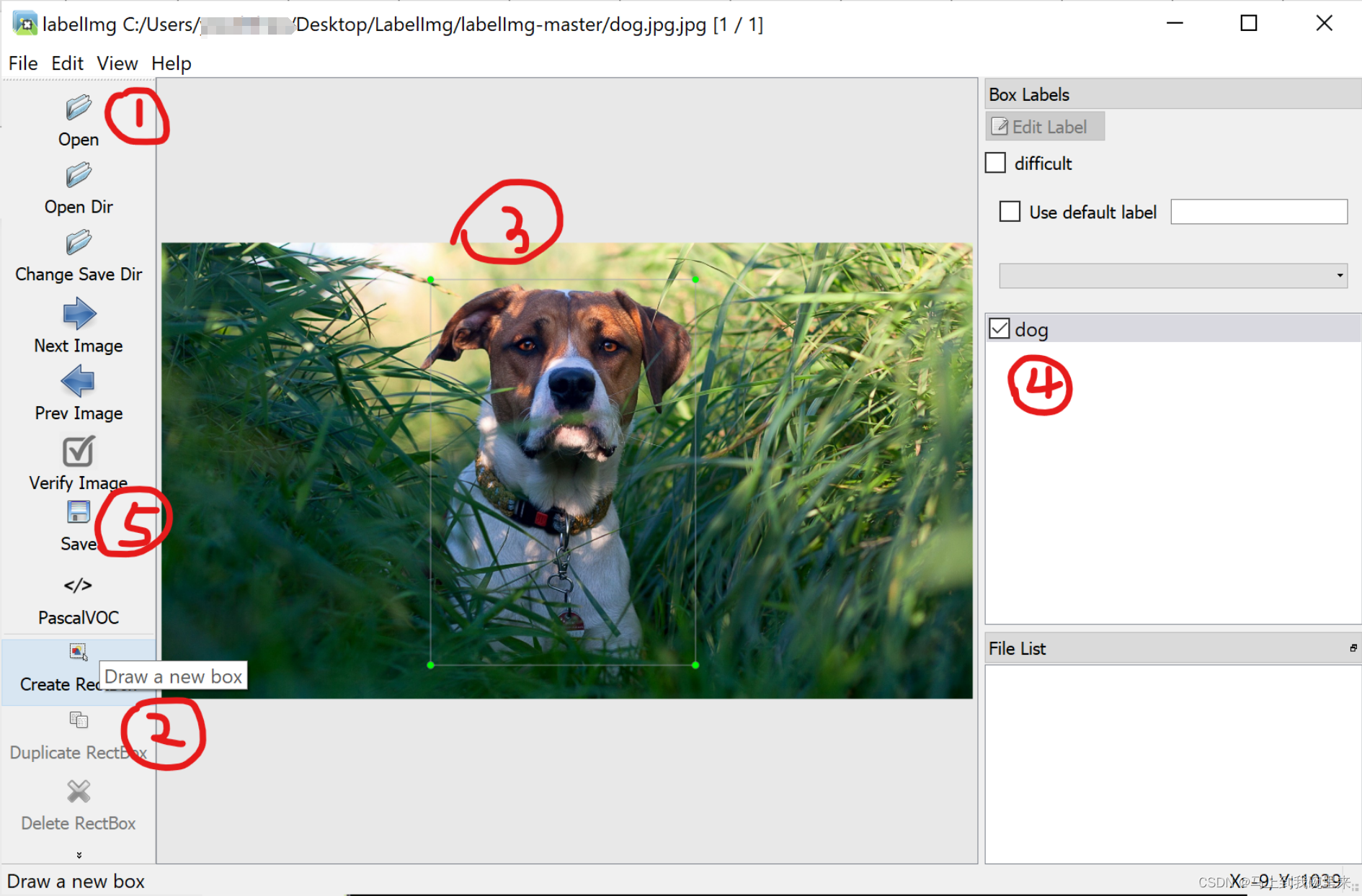

注:修改图中的标签类别内容(如默认的dog、person、cat等)则在主目录下data文件夹中的predefined_classes.txt文件中修改。
3.2 进行快捷标注的设置
点击View显示如下图,然后把如下的几个选项勾上:
Auto Save mode:当你切换到下一张图片时,就会自动把上一张标注的图片标签自动保存下来,这样就不用每标注一样图片都按Ctrl+S保存一下了Display Labels:标注好图片之后,会把框和标签都显示出来Advanced Mode:这样标注的十字架就会一直悬浮在窗口,不用每次标完一个目标,再按一次W快捷键,调出标注的十字架。
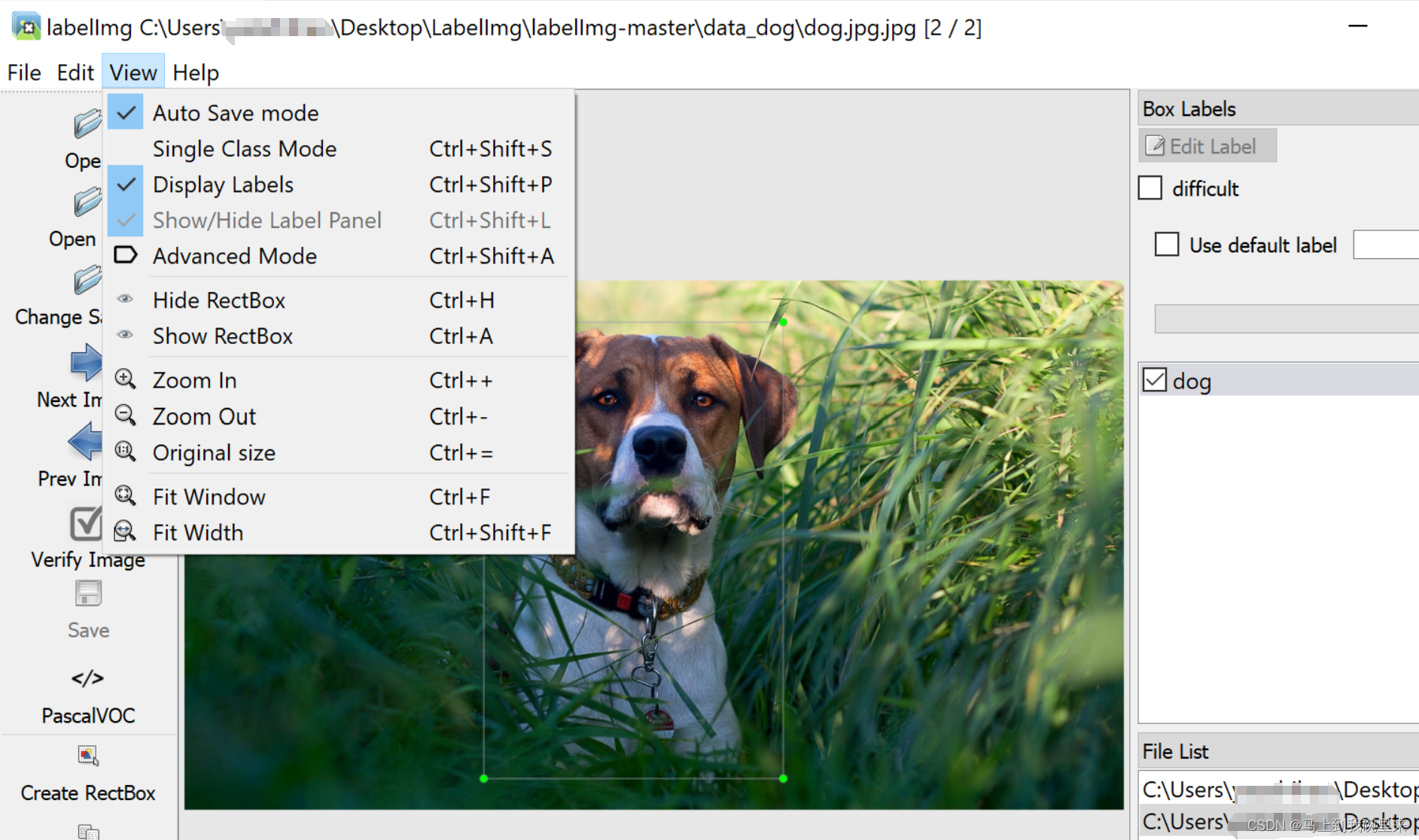
形成如下的格式文件:
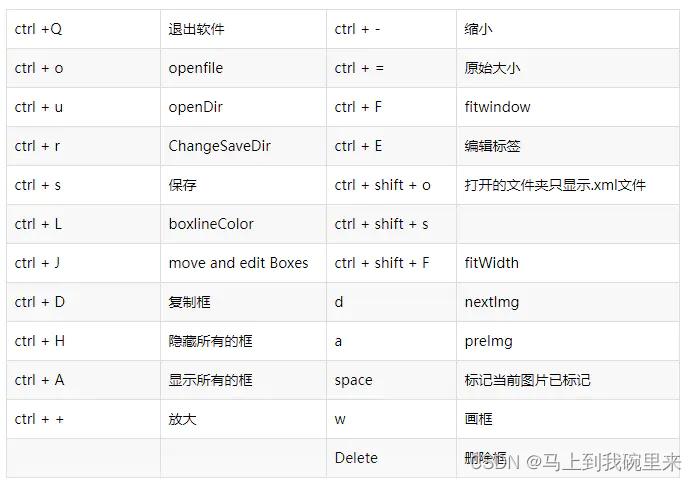
3.3 操作按键和快捷键
功能键:
“Open”是打开单个图像,
“Open Dir” 打开文件夹,
“Change Save Dir” 图像保存的路径,
“Next Image” 切换到下一张图像,
“Prev Image”切换到上一张图像,
“Verify Image”校验图像,
“Save”保存图像,
“Create RectBox”画标注框一个,
“Duplicate RectBox”重复标注框,
“Delete RectBox”删除标注框,
“Zoom In” 放大图像,
“Zoom Out” 缩小图像,
“Fit Window”图像适用窗口,
“Fit Width”图像适应宽度。
快捷键:
4 VOC数据标签格式和YOLO数据标签格式说明
4.1 VOC数据格式
VOC数据格式,会直接把每张图片标注的标签信息保存到一个xml文件中
例如:我们上面标注的JPEGImage/000001.jpg图片,标注的标签信息会保存到Annotation/000001.xml文件中,000001.xml中的信息如下:
<annotation>
<folder>data_dog</folder>
<filename>dog1.jpg</filename>
<path>C:\Users\Desktop\LabelImg\labelImg-master\data_dog\dog1.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>1185</width>
<height>1319</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>dog</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>418</xmin>
<ymin>93</ymin>
<xmax>1000</xmax>
<ymax>1079</ymax>
</bndbox>
</object>
</annotation>
xml中的关键信息说明:
- 图片的名字
- 每个目标的标定框坐标:即左上角的坐标和右下角的坐标
- xmin
- ymin
- xmax
- ymax
4.2 YOLO数据格式
YOLO数据格式,会直接把每张图片标注的标签信息保存到一个txt文件中
例如:我们上面标注的JPEGImage/000001.jpg图片,标注的标签信息会保存到Annotation/000001.txt文件中(同时会生成一个classes.txt文件,也保存到Annotation/classes.txt),000001.txt中的信息如下:
0 0.521000 0.235075 0.362000 0.450249
0 0.213000 0.645522 0.418000 0.519900
0 0.794000 0.665423 0.376000 0.470149
txt中信息说明:
- 每一行代表标注的一个目标
- 第一个数代表标注目标的标签,第一目标circle_red,对应数字就是0
- 后面的四个数代表标注框的中心坐标和标注框的相对宽和高(进行了归一化,如何归一化可以参考我的这篇博客中的介绍)
同时会生成一个Annotation/classes.txt实际类别文件classes.txt,里面的内容如下:
circle_red
circle_gray
rectangle_red
rectangle_gray
fingeprint_red
fingeprint_gray
other
5 数据集制作
1.数据集的搜集 → 2.数据集的标注 → 3.数据集的训练 → 4.数据集的应用
5.1 视频处理(视频按帧转换图片)
在OpenCV中,按帧截取,将视频截成一张张照片。
#include"stdafx.h"
#include<iostream>
#include<opencv2\opencv.hpp>
using namespace std;
using namespace cv;
int main()
{
Mat frame;
int num = 0;
int n = 1;
string filename;
string Imagespath = "E:/img/"; // 保存图片的文件夹路径一定要有,因为OpenCV不会自动创建文件夹
VideoCapture capture(0); //读取视频,存放视频的绝对路径
while (true)
{
capture >> frame; //将视频读入mat对象
if (frame.empty())
{
printf("read video error");
system("pause");
}
/**************************定位验证**********************************/
rectangle(frame, Point(100,0), Point(580,480), Scalar(0, 0, 255), 1, 8, 0);
imshow("video", frame);
/*********************保存图片*************************************/
//int_to_string
string string_temp;
stringstream stream;
stream << n;
string_temp = stream.str();
filename = Imagespath + string_temp + ".jpg";
num++;
if (num >= 3)//确定多少帧截取一张图片,10就是10帧截取一张
{
//截取指定位置
Rect rect(100, 0, 480, 480);//左上顶点坐标,宽高
Mat image_roi = frame(rect);
//可以在这加入仿射变换
cout << "now is writing:" << string_temp << ".jpg" << endl;
imwrite(filename, image_roi);
num = 0;
n++;
}
waitKey(30);
}//while()
return 0;
}
得到从1开始编号的图片数据集。
到此为止 使用labelImg工具标注自己的数据集完成
5.2 图片标注
将照片一张张进行标注成VOC(xml文件格式)。参考文献
标注完之后,一个文件夹放图片,一个文件夹放标注好的.XML文件,最后将.xml文件转为.txt格式。
(好像yolo有专门的转换程序可以直接将xml文件转换成txt文件)
6 一些思考
自己采集的数据,自己打标签,最终做的数据分析效果怎么样?
通过yolo进行识别,一个类别大概需要多少个样本?大概1000个左右
7 参考资料
参考:yolo中的详细标注过程
参考:labelImg官方网址
参考:COCO数据集
















 1542
1542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









