







1. 概述
Cochran-Armitage trend test,简称为CAT趋势检验,是由William Cochran和Peter Armitage提出的一种分析两个分类变量(线性)关联性的检验方法,
- 区别于卡方检验,该方法要求
- 其中一个分类变量必须只有两个类别,
- 另外一个变量则是一个有序的分类变量。
简而言之,该方法适用于处理 2 x K 的分类数据,这里的K是一个有序分类变量, K最小值为3。该方法用来探究有序变量在各组中的发生率和对应的排序之间是否存在线性关系,有点类似逻辑回归。
Cochran-Armitage趋势检验是一种线性趋势检验,但线性不是指比率的变化呈线性变化,而是指经过logistic变换后呈现出线性变化趋势。
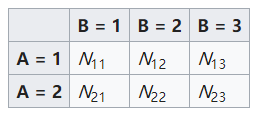
2. 第一个示例:构建卡方统计量,检验显著性
下图所示是一个K=3的例子
CAT检验构建了一个统计量T. 计算过程如下
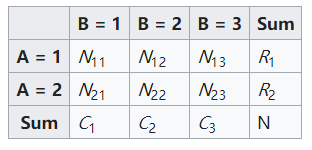

这里的 ti 是指有序变量的赋值,具体赋值方法如下:
在线性趋势检验中,需要运用到变量在卡方检验中没有用到的顺序信息,这就面临着如何对有序分类变量赋值的问题。在列联表中,有很有序分类变量是属于主观评价的顺序,如本文的例子。有序分类变量的相邻等级之间的距离是否相等我们并不清楚,换一句话说就是我们不知道有序分类变量的分布。有人提出了三种赋值方法:
- 等距赋值:即不管相邻等级之间的距离有什么不同,都给它们赋予相同的距离,如本例的四个等级可以为1、2、3、4,也可以是1、3、5、7,也可以是0.1、0.2、0.3、0.4,这些赋值最终的分析结果都是一样的。
- 均秩赋值:即按照每个等级的平均秩次来赋值,如本例的四个等级可以赋值为x1=(1+n1)/2=130,x2=n1+(1+n2)/2=274.5,x3=n1+n2+(1+n3)=965.5,x4=n1+n2+n3+(1+n4)/2=1306 (见示例2)。
- MERT法:采用极大极小效率原理进行赋值的一种方法,比较复杂,本文不做展开。
对该统计量进行卡方检验,计算公式如下
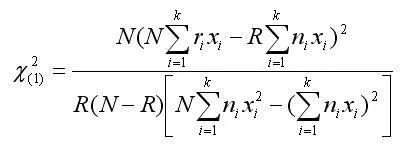
该方法常用于case/control的基因型关联分析,示意如下
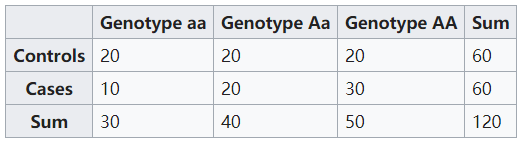
在进行分析时,可以根据遗传模型对基因型进行加权。对于case/control的关联分析而言,遗传模型是未知的,通常采用加性模型,也称之为共显性模型进行分析。包含的突变Allel的个数需要相加,对应的系数为(0,1,2)。
和卡方检验相比,其检验效能更佳,上述示例在R中分析的代码如下
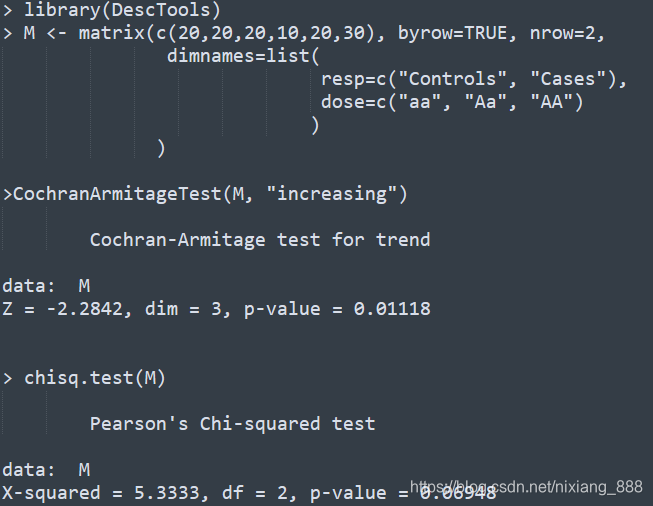
卡方检验p值不显著,而CAT趋势检验的p值显著。CAT检验称之为趋势卡方检验,作为传统卡方检验的一种有效补充,在关联分析中广泛使用,加强了检验的效能,可以更好的挖掘关联信号。
3. 第二个示例:正态近似法,检验显著性
对于其中k×2的一类单向有序表,其结果是二分类的,我们可以用卡方检验来比较各组率的差异。但如果你还想看看各组率是否呈现某种趋势的变化,比如下面这张表,我们希望知道是不是员工星级越高,投诉率就越低,投诉率与员工星级之间存在什么样的关系,这时常用的卡方检验就不太适用了,而Cochran-Armitage趋势检验可以帮助我们做出判断。
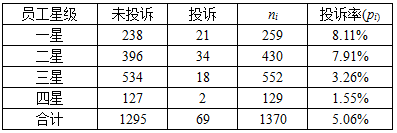
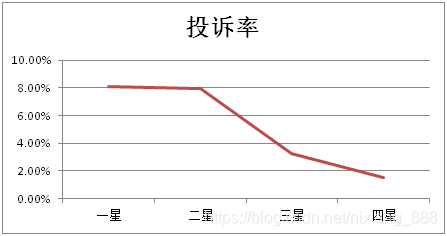
Cochran-Armitage趋势检验是一种线性趋势检验,但线性不是指比率的变化呈线性变化,而是指经过logistic变换(见下式)后呈现出线性变化趋势。
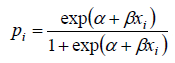
计算过程
1. 首先建立假设
- 原假设当然只有一种,即
H0:p1=p2=…=pk
- 备择假设有三种:
单侧(上升趋势) Ha:p1<p2<…<pk
单侧(下降趋势) Ha:p1>p2>…>pk
双侧 Ha:p1<p2<…<pk 或 p1>p2>…>pk
在线性趋势检验中,需要运用到有序分类变量在卡方检验中没有用到的顺序信息,这就面临着如何对有序分类变量赋值的问题。在列联表中,有很多有序分类变量是属于主观评价的顺序,如本文的例子。有序分类变量的相邻等级之间的距离是否相等我们并不清楚,换一句话说就是我们不知道有序分类变量的分布。有人提出了三种赋值方法:
-
等距赋值:即不管相邻等级之间的距离有什么不同,都给它们赋予相同的距离,如本例的四个等级可以为1、2、3、4,也可以是1、3、5、7,也可以是0.1、0.2、0.3、0.4,这些赋值最终的分析结果都是一样的。
-
均秩赋值:即按照每个等级的平均秩次来赋值,如本例的四个等级可以赋值为x1=(1+n1)/2=130,x2=n1+(1+n2)/2=274.5,x3=n1+n2+(1+n3)=965.5,x4=n1+n2+n3+(1+n4)/2=1306。
-
MERT法:采用极大极小效率原理进行赋值的一种方法,比较复杂,本文不做展开。
-
南方医科大学的何春拉等运用Monte-Carlo方法进行了模拟试验,对各种赋值方法在不同参数组合下的I类错误和检验效能进行了对比分析,
其结论是:“综合模拟结果和应用的便利性,有序分类数据的Cochran-Armitage趋势检验采用等距赋值更值得提倡”。
2. 统计量计算
为了方便起见,在本文的例子中对变量赋值为1、2、3、4。
设
- yi 为所关注的事件的发生频数,本例为投诉数;
- ni 为各等级的样本量;
- xi 为各等级的赋值,
我们可以得到:
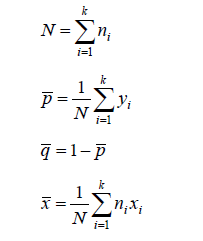
本例中可以算得N=1370,p均值=0.0547,q均值=0.9453,x均值=2.4022。
采用正态近似,运用下式计算检验统计量:
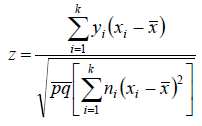
根据此公式计算本例的z-统计量,先计算其中的求和部分:
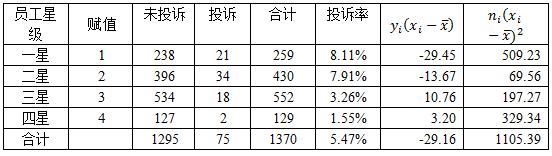
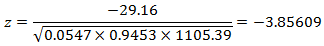
本例的备择假设为前面所列的下降趋势,p(z<-3.85609)=0.0000576,小于0.05,因此我们拒绝原假设,投诉率随着员工星级的提高而下降。
非等距示例
在有些实验中,是在连续因子取几个水平,考察不同水平下结果的变化。这是试验设计中常用的方法。如果输出结果为离散变量,如成品率、成活率等等,希望考察这些得率随着因子水平的变化所呈现出的变化趋势时,可以采用本文介绍的方法。
在分析时,可以直接将因子水平的数值带入公式计算,而不需要另外赋值。
例2:(随便编的数据)某产品的合格率可能与反应温度有密切关系,为此取温度的不同水平做试验,得到的合格率如下表,现需要判断合格率是否随着试验温度的上升而提高。
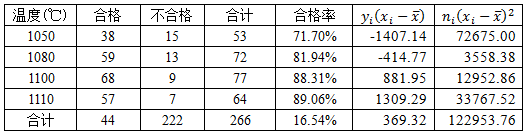
本例采用上升趋势的假设。
利用表中的数据可以算得N=266,p均值=0.1654,q均值=0.8346,x均值=1087.03。
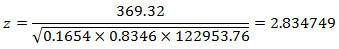
p(z>2.834749)=0.00229,小于0.05,因此我们拒绝原假设,合格率随温度的上升而提高。

















 3211
3211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









