






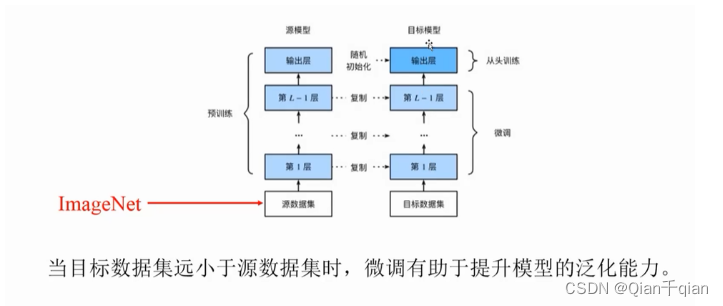
预训练
可行性:预训练好的网络参数,尤其是底层的网络参数,若抽取出特征跟具体任务越无关,越具备任务的通用性,所以一般用底层预训练好的参数初始化新任务网络参数。
迁移学习:把在大的通用的数据集A上训练的模型拿到小的,专有的数据集B上来用就是迁移学习。
使用预训练网络具有两种方法:
-
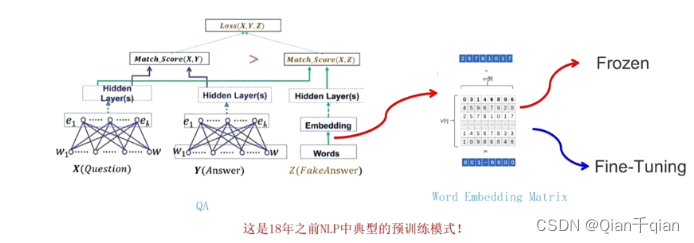
特征提取(feature extraction)或者叫冻结:就是将之前的网络学到的提取特征的层直接拿过来用。(例如CNN中的卷积层和池化层)然后 重新训练全连接层。

-
微调(fine-tuning):对于用于特征提取的冻结的模型基,微调是将顶部的几层“解冻”,并将解冻的几层和新增加的部分(全连接分类器)联合训练。使用原来的参数值,使用较小的learning rate(原来的参数已经很不错了,不想过大的调整,一般是从0开始训练的learning rate的 1 10 \frac{1}{10} 101左右)进行训练调整。
使用预训练模型时,一般使用fine-tuning的较多。
解决的问题:如果有一个功能很强大的模型,比如ResNet或者VGG16,但是数据集很小,很容易出现过拟合,怎么解决?使用预训练模型。即使是数据集很大,也可以使用预训练语言模型,节省训练时间,节省成本。
语言模型
一般要完成两个任务:
- P(“判断这个词的词性”),P(“判断这个词的磁性”)
- “判断这个词的_________”
统计语言模型
用统计的方法解决语言模型问题(以上两个问题)
用条件概率的链式法则(概率论)解决了第一个问题
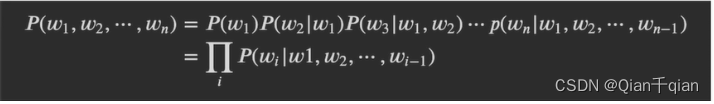
P{“词性”|“判断”,“这个”,“词”,“的”}
P{“火星”|“判断”,“这个”,“词”,“的”}
判断两个概率的大小
缺点:计算量大
P{“词性”|“判断”,“这个”,“词”,“的”,……}概率公式就会很长,计算起来就会很麻烦
解决方法:n元统计语言模型
n元统计语言模型
P{“词性”|“这个”,“词”,“的”} P{“火星”|“这个”,“词”,“的”}
P{“词性”|“词”,“的”,} P{“火星”|“词”,“的”}
P{“词性”|“的”,} P{“火星”|“的”}
把n个词,取后2个词(2元)或者3个词(3元)
平滑策略:防止出现 0 0 \frac{0}{0} 00的情况
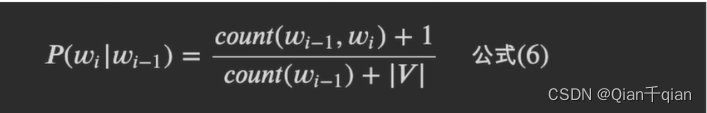
神经网络语言模型
用神经网络的方法解决语言模型问题(两个问题)

假设有4个单词w1、w2、w3、w4(独热码)
w1*Q=c1,
w2*Q=c2,
w3*Q=c3,
w4*Q=c4,
c = [c1, c2, c3, c4]
softmax(U(tanh(WC+b1))+b2) = [0.1, 0.1, 0.2, 0.2, 0.4] = "第5个词语"
Q是一个随机矩阵,是一个参数(可学习)
-
独热编码(one-hot编码)略
缺点:无法使用余弦相似度来计算词语之间的联系
-
词向量(神经网络语言模型的副产品)
任何一个词-》独热编码-》w1*Q=c1(判断这个词的词向量)
词向量:使用一个向量来表示一个单词。
优点:可以控制Q的大小,来控制c1的维度(减小了存储空间),解决了相似度的问题
Word2Vec模型
该模型是一个神经网络语言模型,但是主要目的是得到词向量
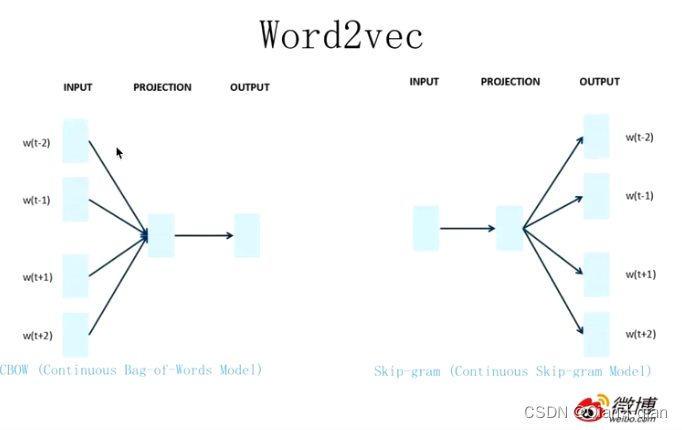
该模型又分为两种模型:
-
CBOW
给出一个词的上下文,预测这个词。
“我是最___的小千子”
“帅”
-
Skip-gram
给出一个词,得到这个词的上下文
“帅”
“我是最__的小千子”
NNLM和Word2Vec的区别:NNLM重点是预测下一个词,Word2Vec重点是得到一个Q矩阵。
缺点:词向量不能进行多意
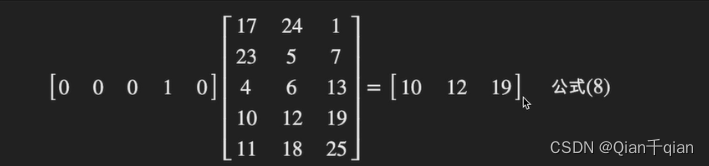
“苹果”对应一个独热码,但是根据上下文的不同,它可能是吃的苹果,也可能是苹果手机,但是只对应了一个词向量。
预训练语言模型的下游任务改造
预训练语言模型出来了(给出一句话,我们先使用独热编码(一一对应的表查询),再使用Word2Vec预训练好的Q矩阵直接得到词向量,然后进行接下来的任务)。这里也有两种方法:
- 冻结:不改变Q矩阵
- 微调:随着任务的改变,改变Q矩阵
无论是之后讲的ELMO、Transformer、Bert都是对上有任务的改造,就是如何获取词向量进行了改造,使得得到的词向量所包含的信息越来越丰富,越来越强大。
ELMo模型
解决了多义词问题!
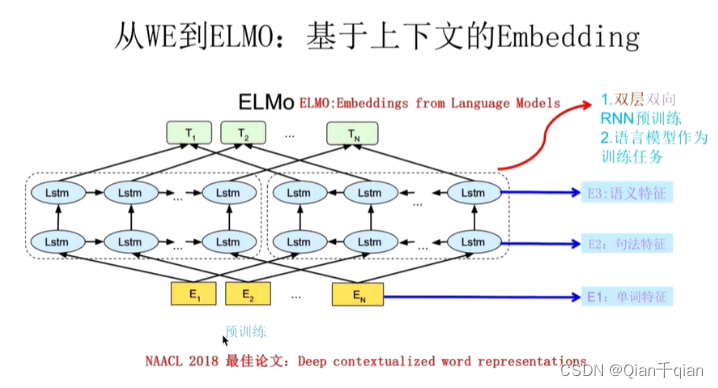
使用双向LSTM,将上下文的信息嵌入到词向量中。
缺点:无法并行计算
Attention(注意力机制)
注意力机制:我们会把我们的焦点聚焦在比较重要的事物上。
我(查询对象Q),这张图(被查询对象V)
重要度计算=相似度计算

Q, K = k 1 , k 2 ⋯ k n K=k_1, k_2 \cdots k_n K=k1,k2⋯kn,我们一般使用点乘的方式,计算Q和K里的每一个事务的相似度,就可以拿到Q和 k 1 k_1 k1, k 2 k_2 k2, k 3 k_3 k3的相似值 s 1 s_1 s1, s 2 s_2 s2, s 3 s_3 s3
做一层 s o f t m a x ( s 1 , s 2 , ⋯ , s n ) softmax(s_1, s_2, \cdots, s_n) softmax(s1,s2,⋯,sn)就可以得到概率:( a 1 , a 2 , ⋯ , a n a_1, a_2, \cdots, a_n a1,a2,⋯,an),就可以找到哪个对Q而言更重要。
还要进行一个汇总,Q查询结束后,Q就是去了价值,最终还是要拿到这张图片的(只不过这张图片多了一些对我更重要或者更不重要的信息),所以再使用得到的概率对原图加权。
( a 1 , a 2 , ⋯ , a n ) ∗ + ( v 1 , v 2 , ⋯ , v n ) = ( a 1 ∗ v 1 + a 2 ∗ v 2 + ⋯ + a n ∗ v n ) (a_1,a_2,\cdots, a_n)*+(v_1,v_2,\cdots, v_n) = (a_1*v_1+a_2*v_2+\cdots+a_n*v_n) (a1,a2,⋯,an)∗+(v1,v2,⋯,vn)=(a1∗v1+a2∗v2+⋯+an∗vn)
这个新的V就算出了Q对该K的注意力值。一般来说 k n = = v n k_n == v_n kn==vn
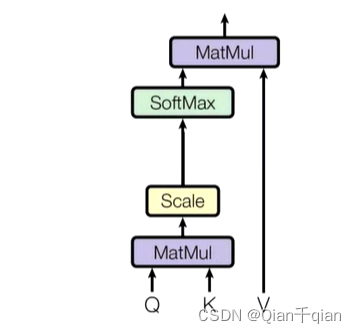
QK相乘求相似度,做一个scale(做softmax的时候避免出现极端情况),然后做softmax得到概率,再和V相乘。
Self-Attention(自注意力机制)
关键点在于,K ≈ \approx ≈V ≈ \approx ≈Q来源于同一个X,这三者是同源的。
-
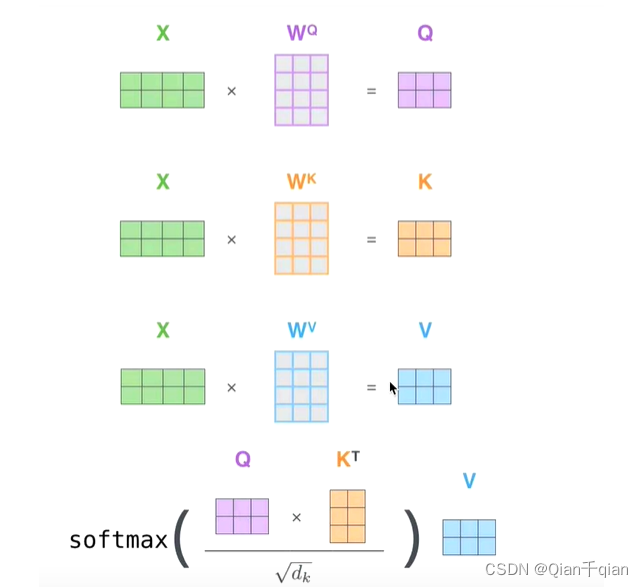
获取Q、K、V并不是KQV,而是通过三个参数: W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv
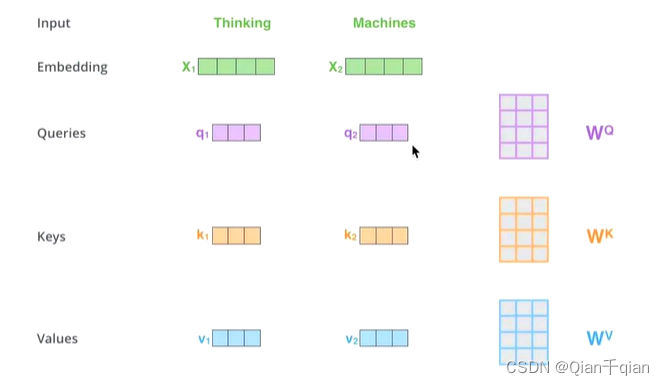
-
Q、K相乘
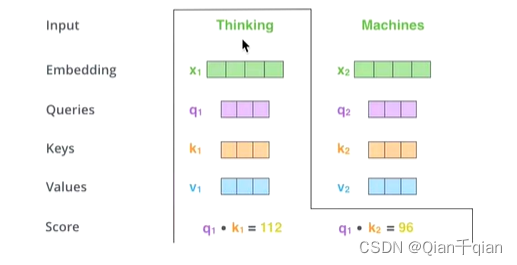
- Scale+softmax

- 结果和V相乘
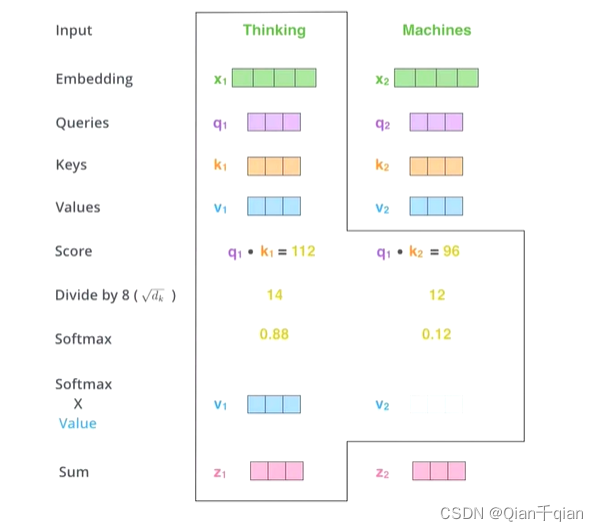
Z 1 Z_1 Z1表示的是thinking的新的向量表示,并且包含了真个句子中的所有单词对thinking这个单词哪个更重要的信息
矩阵表示:
缺点:没有位置信息
与RNN或者LSTM之间的比较
无法做长序列,梯度消失或者梯度爆炸
LSTM通过各种门,选择性地记忆之前的信息,梯度消失问题得到解决
self-Attention解决了长序列问题,可以做并行
self-Attention得到的新的词向量具有句法特征和语义特征(表征更完善)
缺点:计算量大,如果是长文本的话就寄了
Masked Self-Attention
生成模型->生成单词,一个一个生成
当做生成任务的时候,我们想对生成的单词做注意力计算,但是生成的句子是一个单词一个单词生成的。
I have a dream.
I
I have
I have a
I have a dream
I hame a dream <EOS>
掩码后:

Multi-Head Self-Attention(多头自注意力机制)
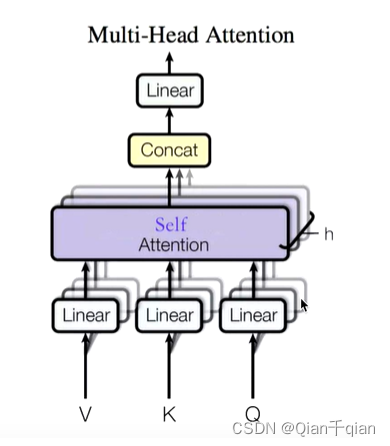
头的个数用h表示,一般h=8,通常使用8头。
对于X,将其分为8块,得到Z0~Z7

再将Z0~Z7拼接起来,再做一次线性变换(改变维度)得到Z

流程图:
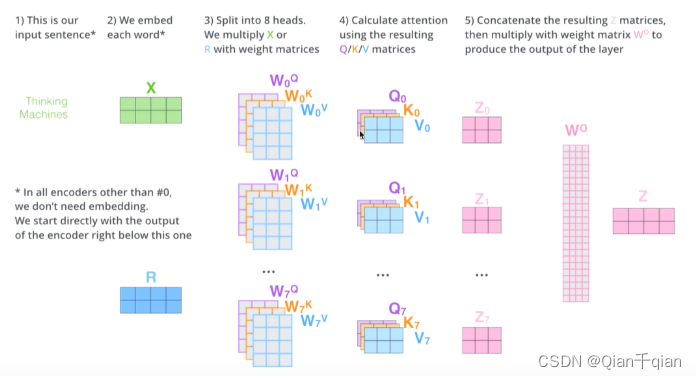
缺点:开销大、可以并行意味着没有位置关系(打乱一句话,这句话里的每个词的词向量依然不会变)
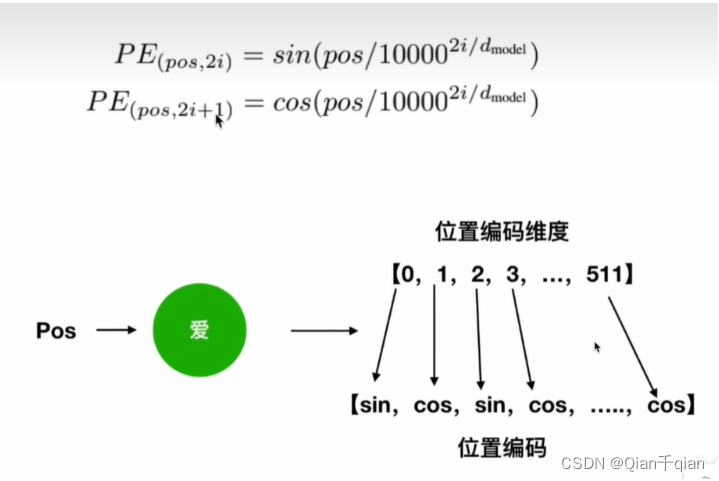
Positional Encoding(位置编码)
Transformer模型
seq2seq(序列到序列)–>编码器到解码器

编码器:把输入变成一个词向量(Self-Attention)
解码器:得到编码器输出的词向量后,生成翻译的结果
编码器:
编码器主要有两个子层,Self-Attention和Feed Forward
子层的传输过程中都会有一个残差网络和归一化
FeedForward:前面的每一步都在做线性变换,线性变换的叠加永远都是线性变换,通过FeedForward中的Relu做一次非线性变换,提高表达能力。
总结一下:在做词向量,只不过这个词向量有更强的表达能力。
解码器:
解码器会接受编码器生成的词向量,然后通过这个词向量生成翻译的结果。只不过是一个下游任务。
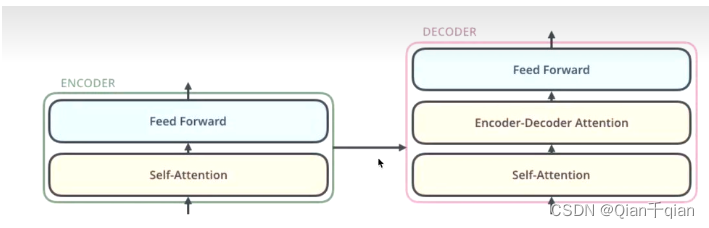
解码器的self-Attention在编码已经生成的单词,假如目标词“我是一个学生”–>masked Self-Attention
Encoder-Decoder Attention:一个数据来源于Encoder,另一个数据来源于Decoder,两者进行交叉注意力机制。编码器得到的词向量作为K、V,解码器已经生成的单词经过masked multi-head attention之后得到的结果作为Q。
-
Decoder为什么做Mask?
因为翻译是一个单词一个单词生成的,测试阶段没办法一次生成所有的单词,还未生成出来的位置只能用[Mask]标记。
-
为什么Encoder的结果作为K、V,Decoder的结果作为Q来做交叉注意力 ?
Q是查询变量,是已经生成的词,K=V是源语句,通过已经生成的词和源语句做自注意力,就是确定源语句中的哪些词对接下来的词的生成更有作用。
通过部分(生成的词)去全部(源语句)的里面找重点
解决了以前的 seq2seq框架的问题:lstm做编码器(得到词向量C),lstm做解码器做生成。
每生成一个词,都是通过C的全部信息去生成,很多信息对当前生成词没有意义,而且还有可能由于不停传递,可能埋没了对于生成词很重要的信息。
Bert模型
Bert模型是一个预训练模型,它和Transformer一样,是为了得到一个网络,这个网络能够得到蕴含更多信息的词向量,这个网络可以理解为是Encoder层,Bert通过使用两种训练方法,使得该Encoder层能够得到更加强大的词向量来代表源文中的词。因此,当我们有了这个很强大的Encoder,我们可以直接使用它来获得很强的词向量,进而使用该词向量运用到下游任务。
如何训练Bert?
训练方法
方法1:句子中有15%的词汇被mask掉,交给模型去预测被mask的部分。
方法2:判断两个句子是否相邻。有什么用?相邻两句话往往有关联,这样做可以让词向量包含这种关联。可以训练self-Attention正确找到这种关联。
输入
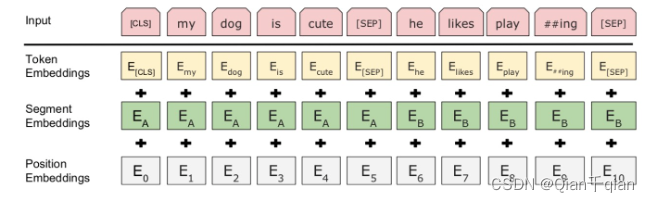
input = token emb + segment emb + position emb三个部分组成
-
Token Embeddings:
输入文本在送入该层之前先进行分词处理,首先加入两个特殊的token:[CLS](句子起始位置)和[SEP](句子与句子之前,以及结尾的位置)。并且这个分词方法有些不一样,他会将组合词拆分为简单词,这样词典中就可以存储更少的词语。然后输入就会抓换为
[CLS] my dog is cute [SEP] he likes play ##ing [SEP]这样,七个词就转换为了11个token,然后该层将这句话中的每一个词都转化为一个相同维度的向量(长度为768),则这句话就转换成了[11, 768]大小的矩阵或者[1, 11, 768]大小(batch_size)
-
Segment Embeddings
用来区别两种句子,前一个句子的每个token都用0表示,后一个句子的每个token都用1表示。如:
[CLS] my dog is cute [SEP] he likes play ##ing [SEP] 表示为 00000011111这也是一个[11, 768]维的向量
-
Position Embeddings
Transformer中使用的是公式法,Bert中是通过训练得到的。Bert一次最长能够处理512个词向量的句子表示,通过让Bert在各个位置上学习一个向量来将顺序的信息编码进来,这意味着该层最终是一个表,512个位置上,每个位置对应一个长度为768的向量。两个不同的句子,位置相同的词,在该层能得到相同的向量。
预训练任务(Pre-training Task)
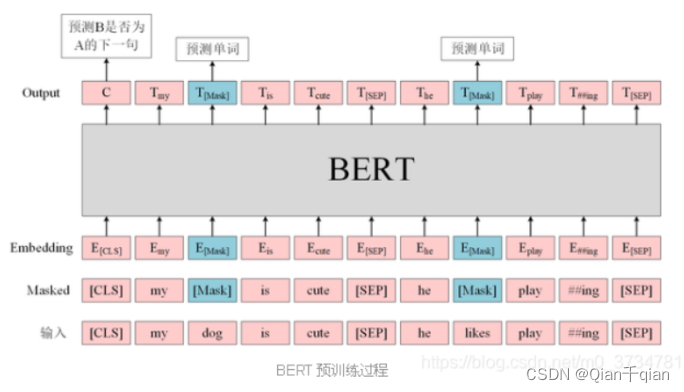
Task1:Masked LM
在将单词序列输入Bert之前,15%的单词被[Mask]这样一个token替换(遮盖)。然后模型基于该位置的上下文来预测被[mask]掉的单词。
在encoder的输出层接一个全连接层,该层的输出层长度为词表的长度,然后用softmax来找到最终预测的词。
Task2:Next Sentence Prediction
Task1只有词语上下文之间的关系,没有句子与句子之间的关系,为了获取句子间的信息,Bert使用了任务2:将两个句子拼接起来,预测原始文本中句子B是否排在句子A之后。而输入层的三个embedding,是为了帮助模型区分两个句子。
在输出的第一个token:[CLS]'上接一个全连接层,该层的输出长度为2,再用softmax计算IsNextSequence的概率。
训练的时候,两个任务是一起训练的。
微调(Fine-tunning)
不同的下游任务,只需要对Bert不同位置的词向量进行处理即可,直接将不同位置的输出直接输入到下游模型中。具体如下:
- 情感分析等单句分类任务,可以直接输入单个句子(不需要[SEP]分隔),将[CLS]的输出直接输入到分类器进行分类。
- 句子关系判断任务,需要[SEP]分隔,然后将[CLS]输入到分类器中。
- 问答任务,将问题和答案拼接输入到Bert模型,然后将答案位置的输出向量进行二分类并在句子方向上进行sortmax(预测开始和结束位置)
- 命名实体识别任务,对每个位置的输出进行分类,如果将每个位置的输出作为特征输入到CRF将取得更好的效果。(存疑)
- 对于常规分类任务,需要在Transformer的输出之上加一个分类层。
参考:bilibili:去钓鱼的程序猿(up主)















 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









