






系列文章目录
目标跟踪算法个人理解-KeepTrack篇
目标跟踪算法个人理解-GRM篇
文章目录
前言
生成范式跟踪有两篇SeqTrack和ARTrack。ARTrack刚刚开源,后续也会总结一下这个工作。
一、SeqTrack简介
文章全名:SeqTrack: Sequence to Sequence Learning for Visual Object Tracking
原文地址:https://arxiv.org/abs/2304.14394
代码地址:https://github.com/microsoft/videox
项目配置:同OSTrack配置基本一致
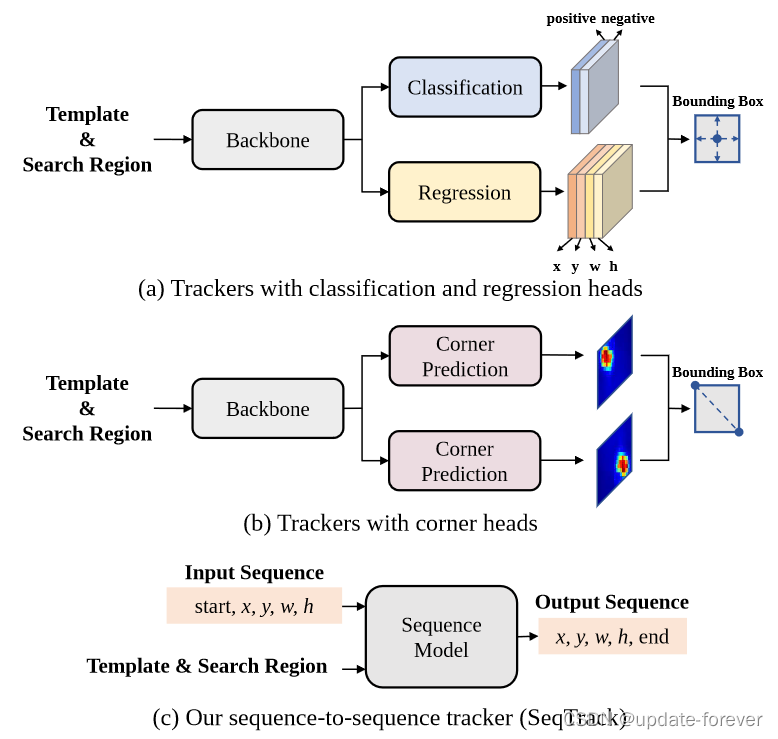
OSTrack基础上的改进算法,将视觉跟踪建模为一个序列生成问题,以自回归的方式预测目标边界框。抛弃了设计复杂的头网络,采用encoder-decoder transformer architecture,编码器用ViT提取视觉特征(≈OSTrack),而解码器用因果转换器自回归生成一个边界框值序列。
二、方法
不讲废话了直接看第三章的方法。
不过相关方法那里作者把跟踪方法总结的很到位,也为自己做的生成式跟踪做了很好的铺垫和介绍。可以仔细读一下,把引到的一些文章学习一下。
1.Overview
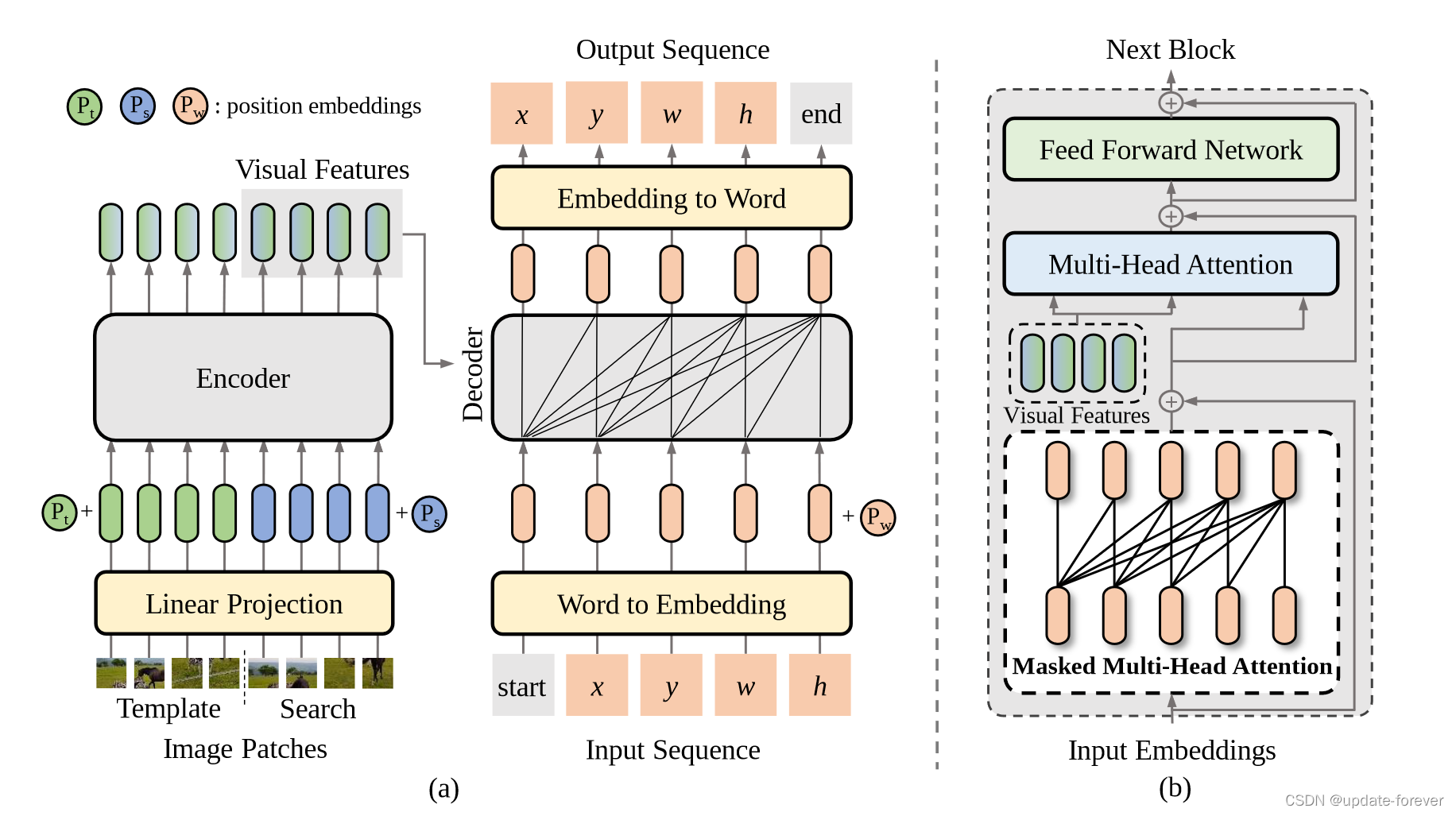
SeqTrack的架构,a:左边编码器拿的ViT,右边解码器用的transformer里的。编码器提取视觉特征,解码器利用特征自回归生成边界框序列。b:解码器结构,最下层输入目标序列,先自注意力再与视觉特征做注意力,自回归输出生成目标序列。
- 解码时加入一个因果注意力掩码(NLP那边用的差不多,防止偷看后边的果)
- 使用了两个特殊的标记:start和end。开始令牌告诉模型开始生成,而结束令牌则表示生成的完成。训练时,解码器的输入序列为 [ s t a r t , x , y , w , h ] [ start , x , y , w , h] [start,x,y,w,h],目标序列为 [ x , y , w , h , e n d ] [ x , y , w , h , end] [x,y,w,h,end]。(NLP里的)
2.Image and Sequence Representation
Image Representation
编码器输入模板和搜索图像。现有的跟踪器中模板图像的分辨率通常小于搜索图像的分辨率,SeqTrack使用相同的尺寸,发现在模板中添加更多的背景有助于提高跟踪性能(为什么其他工作里使用小尺寸模板图像都解释的是为了减少背景干扰,这玩意感觉一人一个说法?)。
t
p
,
s
p
∈
R
N
×
P
2
×
3
t_p, s_p\in\mathbb{R}^{N\times P^2\times3}
tp,sp∈RN×P2×3

Sequence Representation
边界框转换为离散序列
[
x
,
y
,
w
,
h
]
[ x , y , w , h]
[x,y,w,h],将每个连续坐标统一离散为[ 1 , nbins]之间的整数。使用共享词汇表V(4000),V中的每个单词对应一个可学习的嵌入,在训练过程中进行优化。(transformer那篇文章里说的可能更详细)

最终使用一个带softmax的多层感知器,根据输出嵌入对V中的单词进行采样来将嵌入映射回单词。
3.Model Architecture
照着架构提一下需要注意的地方:
3.1 编码器
- 去掉了分类用的cls token。
- 在最后一层附加一个线性投影来对齐编码器和解码器的特征维度。
self.bottleneck = nn.Linear(encoder.num_channels, hidden_dim)
- 只有搜索图像的特征被送入解码器。
代码中这里打个断点往上一级一级看就能明白具体解码过程(与OSTrack基本一致)

3.2 解码器
- 接收来自前一个block的词嵌入并利用一个因果关系掩码保证每个序列元素的输出只依赖于其前面的序列元素。
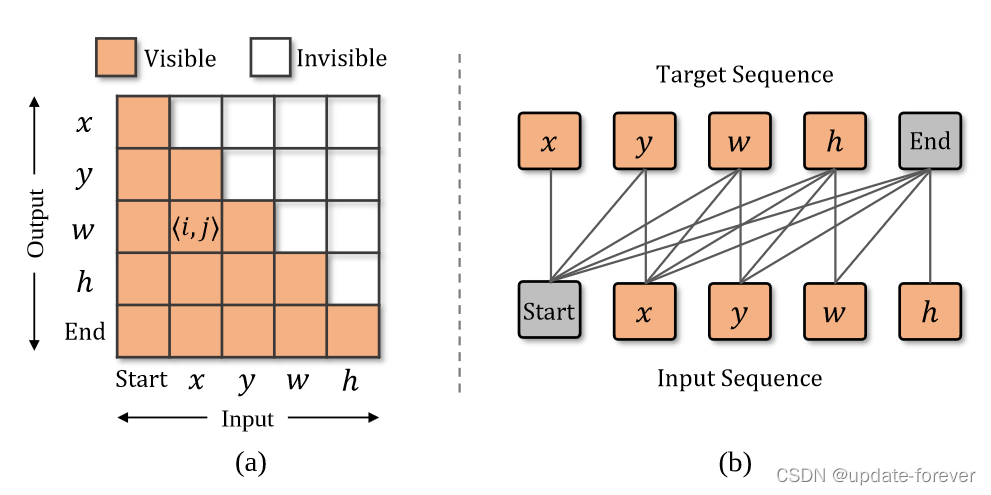
generate the causal mask: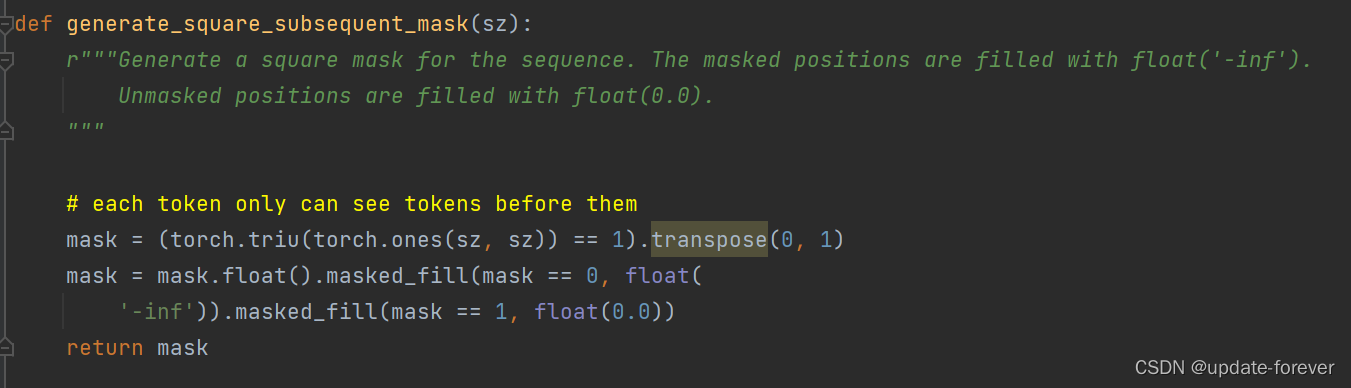
4.Training and Inference
4.1 训练
损失函数:通过交叉熵损失最大化target tokens在前一个子序列和输入视频帧上的对数似然。
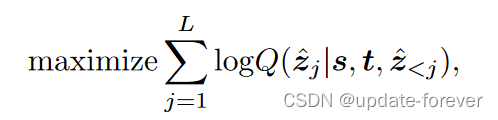
4.2 推理
引入在线模板更新和窗口惩罚,在推理过程中融合先验知识,进一步提高了模型精度和鲁棒性
- 使用generated tokens的似然来自动选择可靠的动态模板。
- 引入了一种新的窗口惩罚策略
当前搜索区域中心点的离散坐标为[ n_bins / 2 , n_bins / 2],即为上一帧目标中心点位置。在生成x和y时,我们根据整数(即词)与nbins / 2的差来惩罚V中整数(即词)的可能性。差值越大惩罚越大。
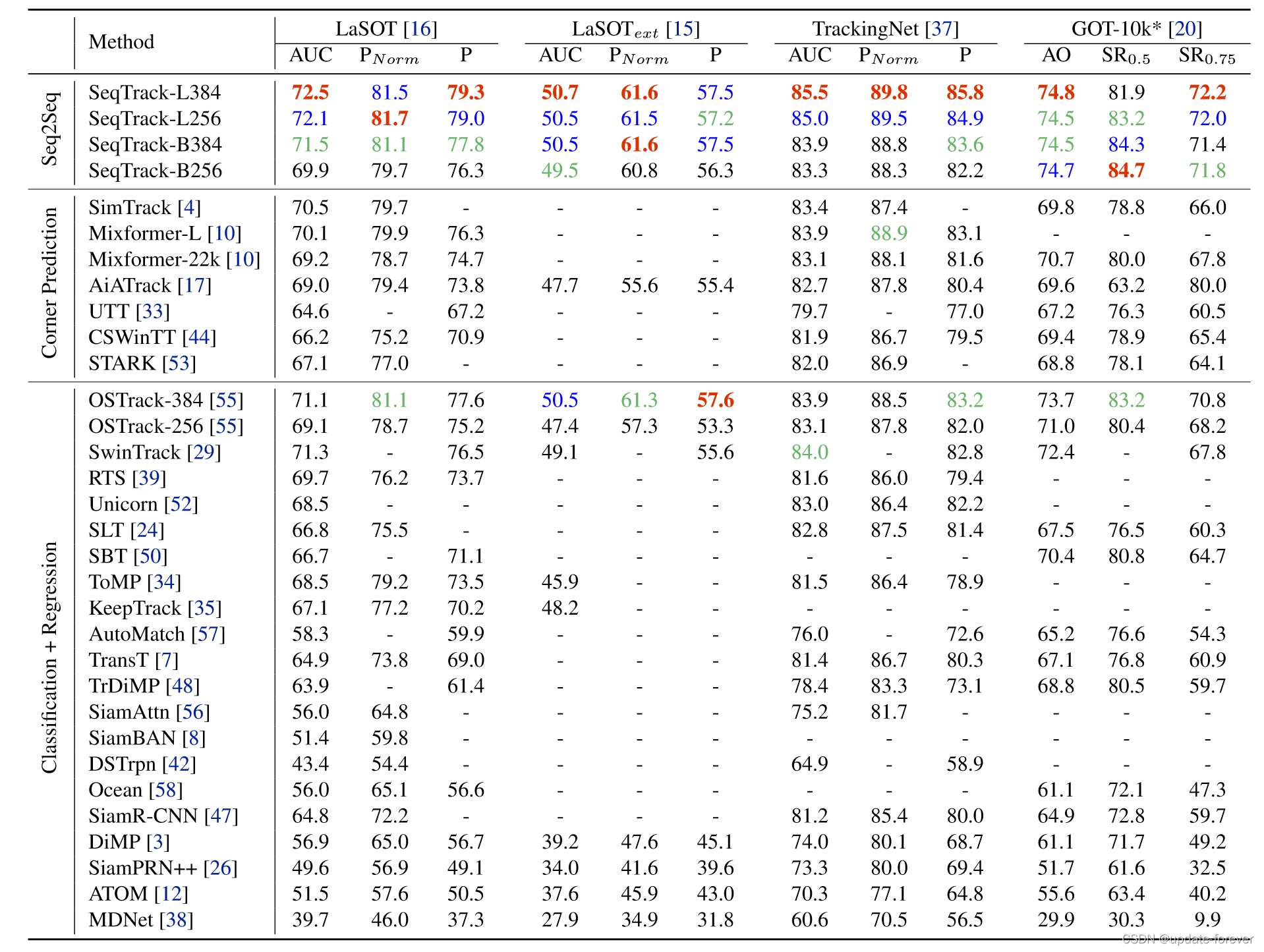
三、实验
State-of-the-art comparisons on four large-scale benchmarks
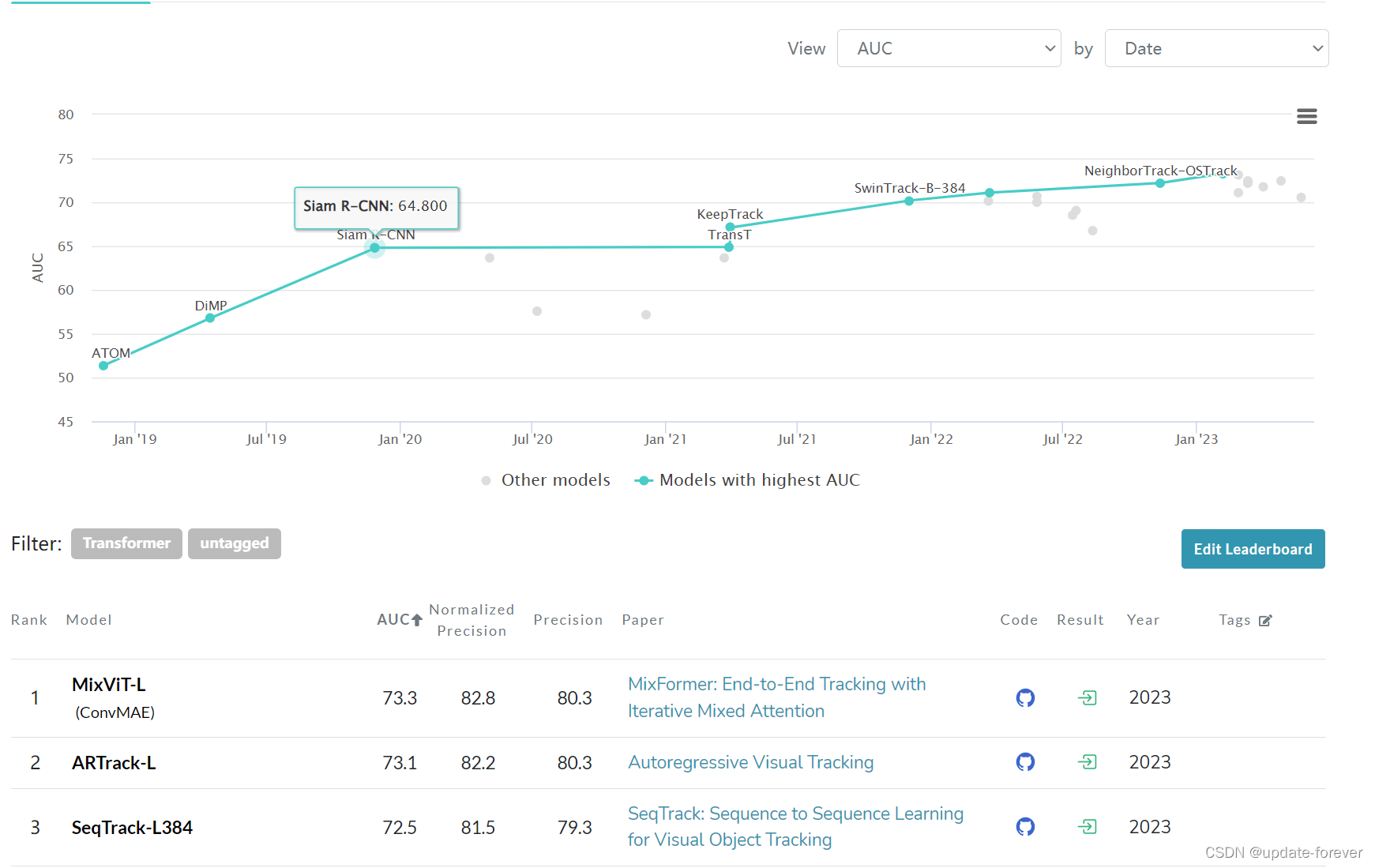
Rank On Paper With Code
目前在paper with code上排第三:
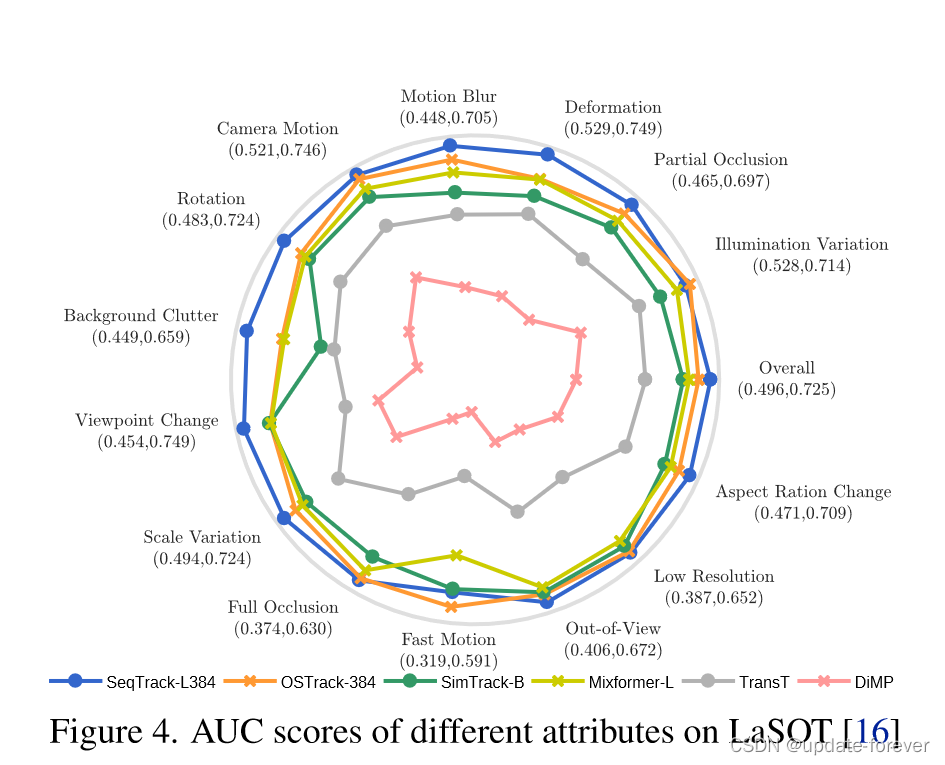
属性雷达图
消融实验
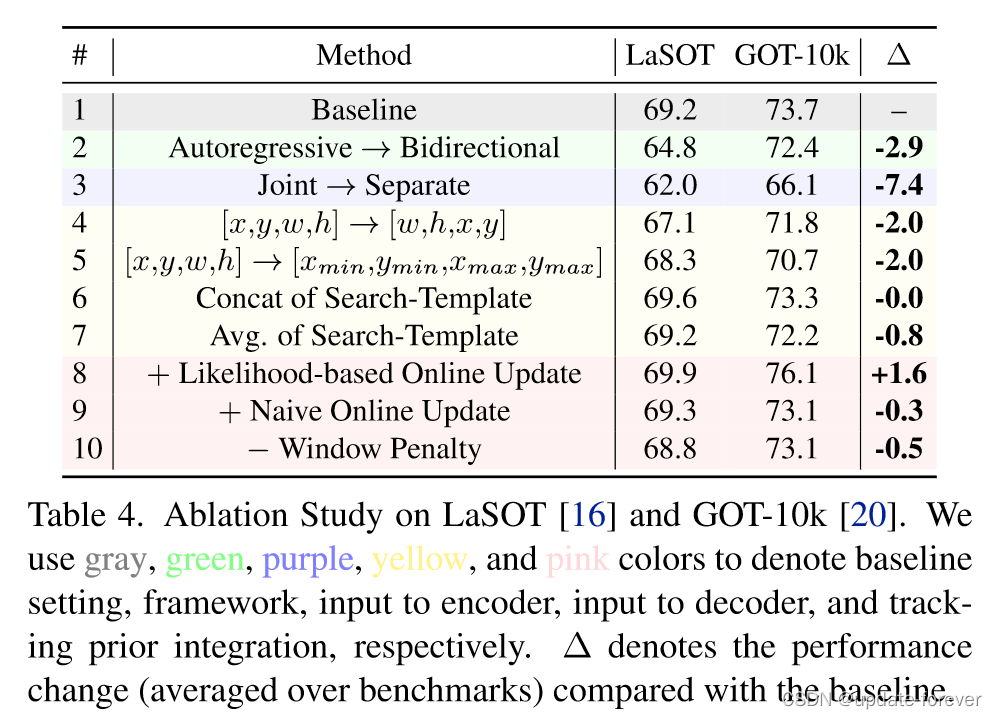
- 各种变体:
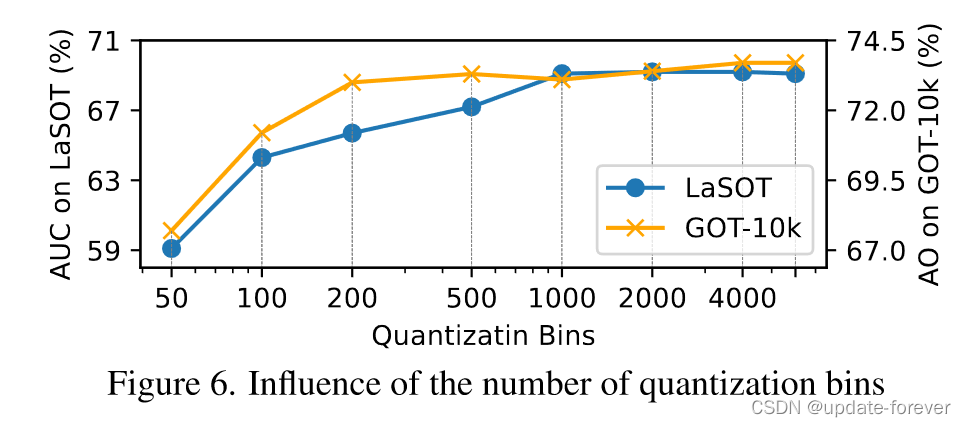
- 词汇表数量分析:
- 注意力可视化:

在生成第一个标记x时,注意力相对多样。在生成后续token时,注意力迅速集中在目标物体上,更集中在关键信息上,例如生成x和w时的人的手臂和斑马的尾巴,生成y和h时的脚。
四、code
- SeqTrack:(SeqTrack-L256为例)

encoder:(ViT)

decoder:(DETR)

五、总结
TODO:推理部分还没捋完,后续更新

















 3820
3820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









