






系列文章目录
目标跟踪算法个人理解-KeepTrack篇
目标跟踪算法个人理解-GRM篇
目标跟踪算法个人理解-SeqTrack篇
前言
今年的SOT算法个人感觉最有新意的就是这篇了,一次很好的贴合SOT具有的序列决策本质的算法研究。同时也跟seqtrack一样,使用了生成范式进行输出预测。但仔细看二者的文章会发现artrack在解码部分使用了历史序列信息来辅助当前帧的序列生成,而seqtrack只是将输出头由分类头、box回归头什么的改成了生成式回归头,没有使用历史序列信息(SOT经典方法:搜索帧模板帧通过“对比”来找目标)。
感觉artrack是在真正探索如何使用序列级别的信息。
简介
文章全名:Autoregressive Visual Tracking
原文地址:CVF Open Access
代码地址:https://github.com/MIV-XJTU/ARTrack
项目配置:照着代码里的ARTrack_env_cuda122.yaml文件装吧,一装一个不吭声。本人最后一个一个手动装的…

本文提出了一个用于视觉目标跟踪的自回归框架ARTrack。将跟踪作为一个坐标序列解释任务来处理这种时间自回归方法通过对轨迹序列变化进行建模,以保持对目标的跨帧跟踪,优于现有只考虑每帧定位精度的基于模板匹配的跟踪器。无需任何定位头和后处理。
整体结构就两个,backbone和pix_head。前者是提取特征的Encoder,后者Autoregressive Decoder进行解码自回归预测坐标index(上图)。重点在解码器上,backbone就是VIT。
Tracking as Sequence Interpretation

将Yt预测转为一个序列坐标解释任务,公式化为一个条件概率,与过去N帧构成的command token,搜索图像和模板图像有关。特别地,当N = 0时,方程( 1 )退化为每帧模型P( Yt | C , Z , Xt),该模型不受过去信息的限制。引入的序列预测回归任务可以解释为,当前帧中估计的目标状态受到相邻前一(N)帧目标状态的影响,同时也会影响后续帧。
3.1 Sequence Construction from Object Trajectory
Tokenization
将连续坐标离散化称为tokenization,也就是将位置信息表示成
[
x
min
t
,
y
min
t
,
x
max
t
,
y
max
t
]
[x_{\min}^t,y_{\min}^t,x_{\max}^t,y_{\max}^t]
[xmint,ymint,xmaxt,ymaxt],其中每一个都是[ 1 , nbins]之间的整数。然后我们使用量化的词项索引一个可学习的词汇,以得到坐标对应的token。这使得模型可以用离散的令牌来描述对象的位置,也使得语言模型中现成的解码器可以用于坐标回归。

Trajectory coordinate mapping
在局部搜索跟踪范式下的相关处理。文中将前 N 帧的全局坐标缓存,并在搜索区域坐标系中进行映射。
Representation range of vocabulary
词汇表的表示范围可以根据搜索区域的大小来设置,但是由于快速的物体运动,之前的轨迹序列有时可能会超出搜索区域的边界。因此作者扩大了搜索区域范围。扩展为(-0.5, 1.5],可以理解为将搜索区域的坐标边界扩大了一倍。图中原始范围是 0 到 400,在坐标映射时的边界为-200 到 600.搜索区域图像没有扩大,但在回归坐标时使用的坐标系范围其实是大于搜索区域的,以应对物体超出搜索区域边界的情况。这部分看代码就很好理解了。

3.2 Network Architecture
编码器是 ViT,解码器是 transformer decoder。
编码器中,搜索帧模板帧拼起来送进去得特征。与 ostrack 几乎一样。
解码器:
编码器底部输入为历史坐标 token(时空提示) 和一个 cmd 命令token(开始令牌),侧边输入图像编码特征进行交叉注意力操作。
底部坐标自注意力是带因果 mask 的,以遵循时间顺序(当前帧坐标不受后续帧坐标的影响)
图 b 是将解码器的自注意力和互注意力解耦开
原文:为了提高跟踪效率,我们研究了一种通过修改解码器层来改变解码器的方法。具体来说,将自注意力层和交叉注意力层进行解耦和单独堆叠。通过这种方式,我们可以并行计算视觉特征的交叉注意力。

3.3 Training and Inference
Training
采用了一个结构化的目标,通过一个softmax交叉熵损失函数来最大化令牌序列的对数似然

同时引入了SIoU损失,以更好地衡量预测框和真实框之间的空间相关性。

Inference
从历史坐标中解码当前帧坐标,开始前 n 帧不足历史长度的直接复制模板帧坐标,后续逐渐替换。
for i in range(self.save_all - 1):
self.store_result.append(info['init_bbox'].copy()) # 历史坐标序列
强推lai 佬的帖子,对 artrack 的训练流程写的很清晰。代码讲的也很透彻。
原帖地址:here
做跟踪的同学也可以加 SOT 交流群332123933(里边大佬很多)
三、实验
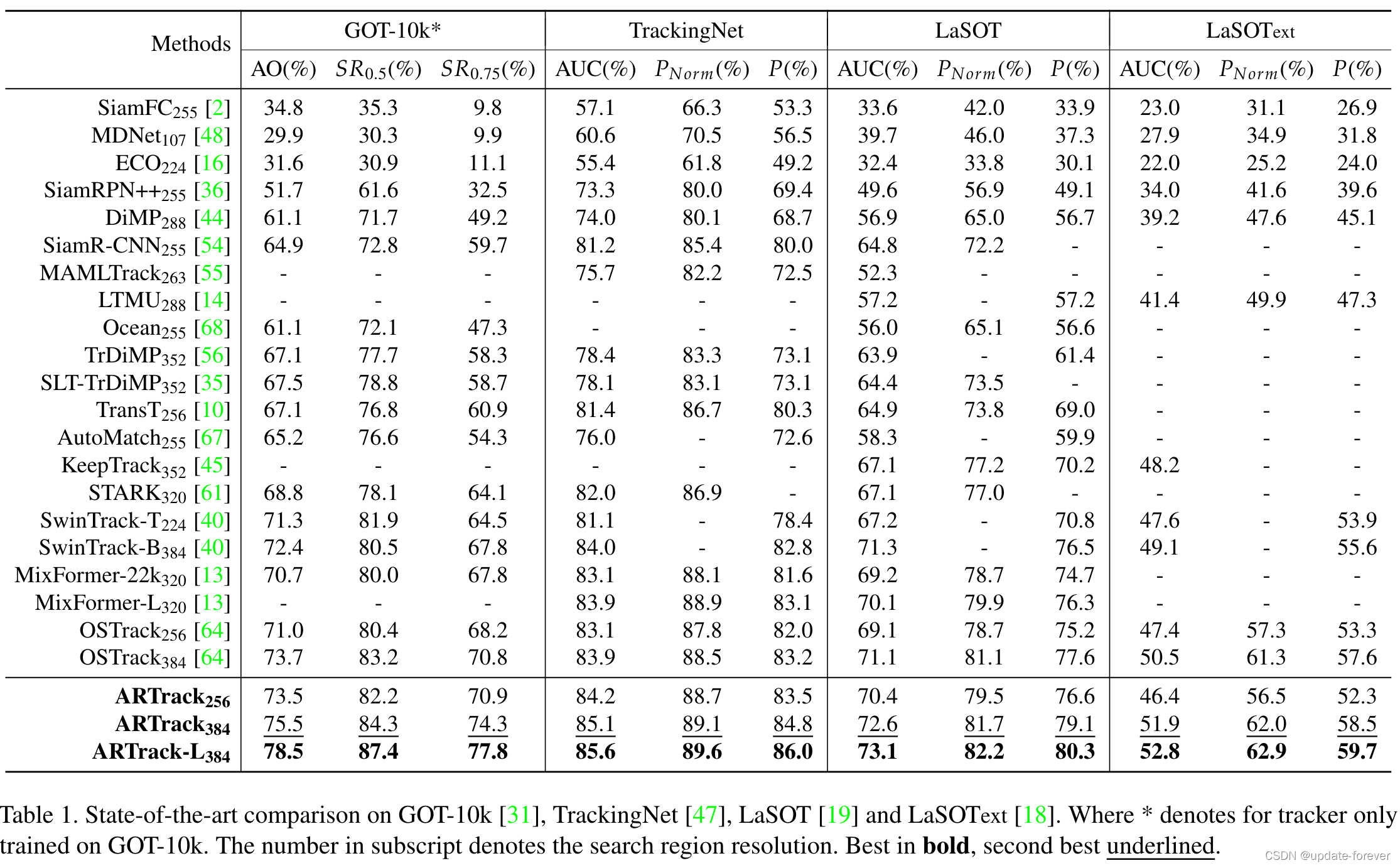
State-of-the-art comparisons on four large-scale benchmarks
在几个经典数据集上的表现,此时 MixViT应该是还没出来
Rank On Paper With Code
目前(8 月份)在paper with code上排第三:

可视化分析
为了更好地理解提出的时间自回归模型,依次预测坐标token的同时生成注意力图。为了测试模型的鲁棒性,使用了现实世界跟踪中遇到的复杂场景,如运动模糊、旋转、角度变化、相机运动等,如图所示。
在每个场景中,跟踪器在预测每个坐标时都会关注合适的端点,展示了模型的精确定位能力。很 work

当面对遮挡和相似物体等更具有挑战性的场景时,采用逐帧模板匹配的方式是不合理的。前者中的目标可能会变得不可见,而后者中各种相似物体的存在会使跟踪器产生混淆。为了克服这些问题,该方法在视觉特征不具有判别性的情况下,利用历史运动轨迹来生成合理的预测。
可以看到,artrack 的关注点在这两种情况下没有被其他物体所分散或干扰,这也表明了历史时序信息对跟踪稳定性具有很重要的作用,如何更好的利用时序信息是未来值得进一步考虑的点。
(单纯靠外观匹配的范式肯定不是跟踪的最优解,如何让算法拥有识别能力和运动轨迹分析能力,并在此基础上做到全图全局跟踪是值得探索的。个人想法)

五、总结
原话中的关键:
更重要的是,我们提出了时空提示来模拟轨迹传播运动线索的序列演化,以获得更一致的跟踪结果。
在未来的研究中,我们希望该框架可以推广到其他视频任务中。(视频理解,视频标题,视频问答。在如何更好的利用时序信息上的一种通用范式探索?)

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









