







文章目录
引言
作为当前最强大的开源大模型之一,LLaMA 3的130亿参数版本在多项基准测试中已接近GPT-4水平。然而,其庞大的计算需求让许多开发者和研究者望而却步——单次微调成本动辄上千元,本地部署需要多张A100显卡,环境配置更是充满"依赖地狱"的挑战。经过在GpuGeek平台上的完整实践,我发现只需0.68元/小时的RTX 4090实例和3步标准化流程,就能高效完成LLaMA 3的微调与部署。本文将分享我的完整操作记录与调优心得。
GpuGeek介绍
以下是关于GpuGeek平台的详细介绍,结合其核心功能、技术优势及行业应用场景:
在人工智能技术迅猛发展的今天,算力资源短缺、开发环境复杂、跨国协作延迟等问题成为AI开发者面临的主要挑战。GpuGeek作为领先的一站式AI基础设施平台,凭借弹性算力调度、全栈开发工具链、全球化资源布局三大核心优势,为开发者、企业及高校提供高效、低成本的AI算力与开发支持,推动产业智能化升级。
注册地址:https://gpugeek.com/login?invitedUserId=734812555&source=invited

1. 平台核心优势
(1)弹性算力网络:按需调度,极致性价比
GpuGeek创新性地采用“算力滴滴”模式,整合全球GPU资源池,支持从消费级(RTX 4090)到专业级(A100/A800/H100)的全系列算力,并提供灵活的计费方式:
- 秒级计费:A5000实例低至0.88元/小时,支持动态扩缩容,避免资源闲置。
- 多卡并行:最高支持8卡GPU集群,满足大规模分布式训练需求。
- 全球化节点:覆盖国内(湖北、宿迁)及海外(香港、达拉斯)数据中心,实现镜像秒级加载,推理延迟低至0.5秒。
(2)全栈开发工具链:开箱即用,极速部署
GpuGeek深度优化AI开发流程,提供从环境搭建到模型部署的完整支持:
- 预置主流框架:TensorFlow、PyTorch、PaddlePaddle、Colossal-AI等,30秒完成实例创建。
- 在线IDE & JupyterLab:支持浏览器直接编程,无需本地配置。
- 模型市场 & 镜像共享:100+预训练模型(如DeepSeek-V3、LLaMA 3),支持用户上传自定义镜像,构建领域专属模型。
(3)国产化适配:昇腾NPU + MindSpore生态
针对国产替代需求,GpuGeek深度整合华为昇腾910B,提供高带宽计算能力,并适配MindSpore框架,形成软硬一体解决方案,助力自主可控AI发展。
2. 典型应用场景
(1)高校科研与教学
- 提供学生认证福利(50元代金券),支持低成本完成AI实验。
- 内置学术加速功能,优化Google Scholar、GitHub等20+站点访问,提升研究效率。
(2)企业AI落地
- 金融风控:利用A100集群进行高频交易模型训练。
- 医疗影像分析:基于预置ResNet-152镜像,快速构建诊断系统。
- 智能客服:集成DeepSeek-V3 API,实现多轮对话优化。
(3)大模型训练与微调
- 支持LLaMA 3、GPT类模型的LoRA/全参数微调,RTX 4090可运行8B模型INT4量化版本,成本仅0.68元/小时。
- 提供ZeRO-3优化,降低显存占用,提升训练效率。
3. 与竞品对比
| 对比维度 | GpuGeek | 传统云厂商 |
|---|---|---|
| 算力成本 | A5000仅0.88元/小时,秒级计费 | 通常1.2元+/小时,按小时计费 |
| 启动速度 | 30秒完成实例创建 | 1-5分钟(需预分配资源) |
| 跨国部署 | 香港/达拉斯节点,延迟0.5秒 | 需额外配置,延迟较高 |
| 国产化支持 | 昇腾910B + MindSpore深度优化 | 依赖英伟达生态 |
4. 官方文档
官方文档提供快速开始
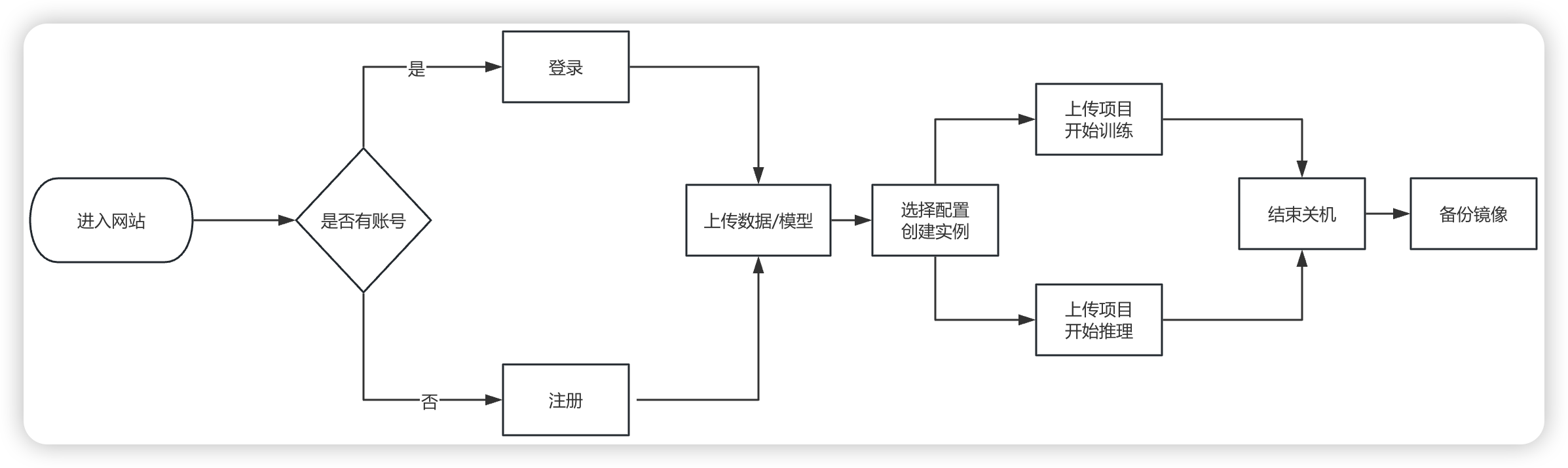
下图是官方简易的使用流程程序图
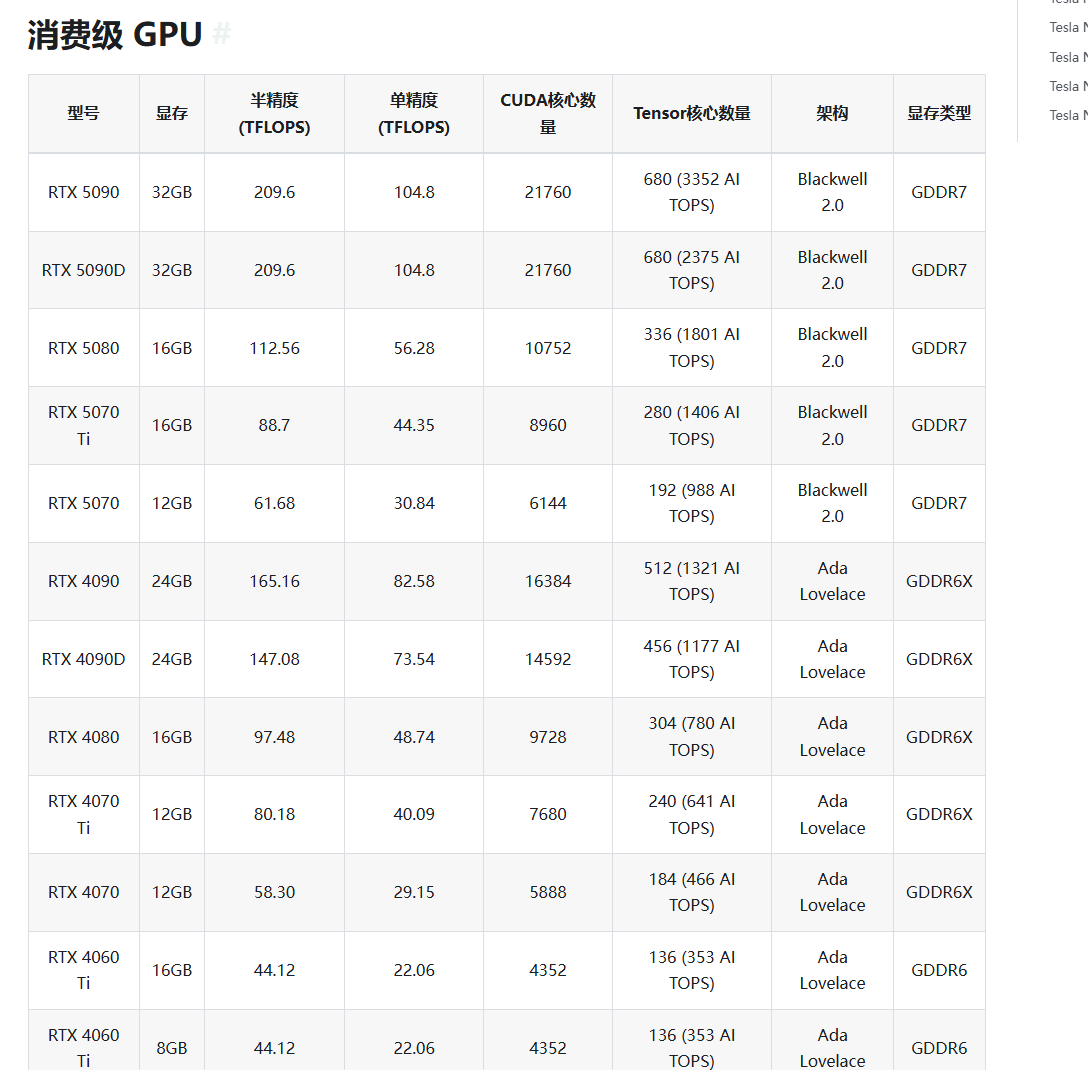
对于小白来讲第一次选购GPU可能摸不着头脑,官方还贴心的为我们提供消费指南–>https://gpugeek.com/docs/product/quick_start/GPUpick
大家可以自行去了解,自己的需求,这样就可以最大化的节省本金了
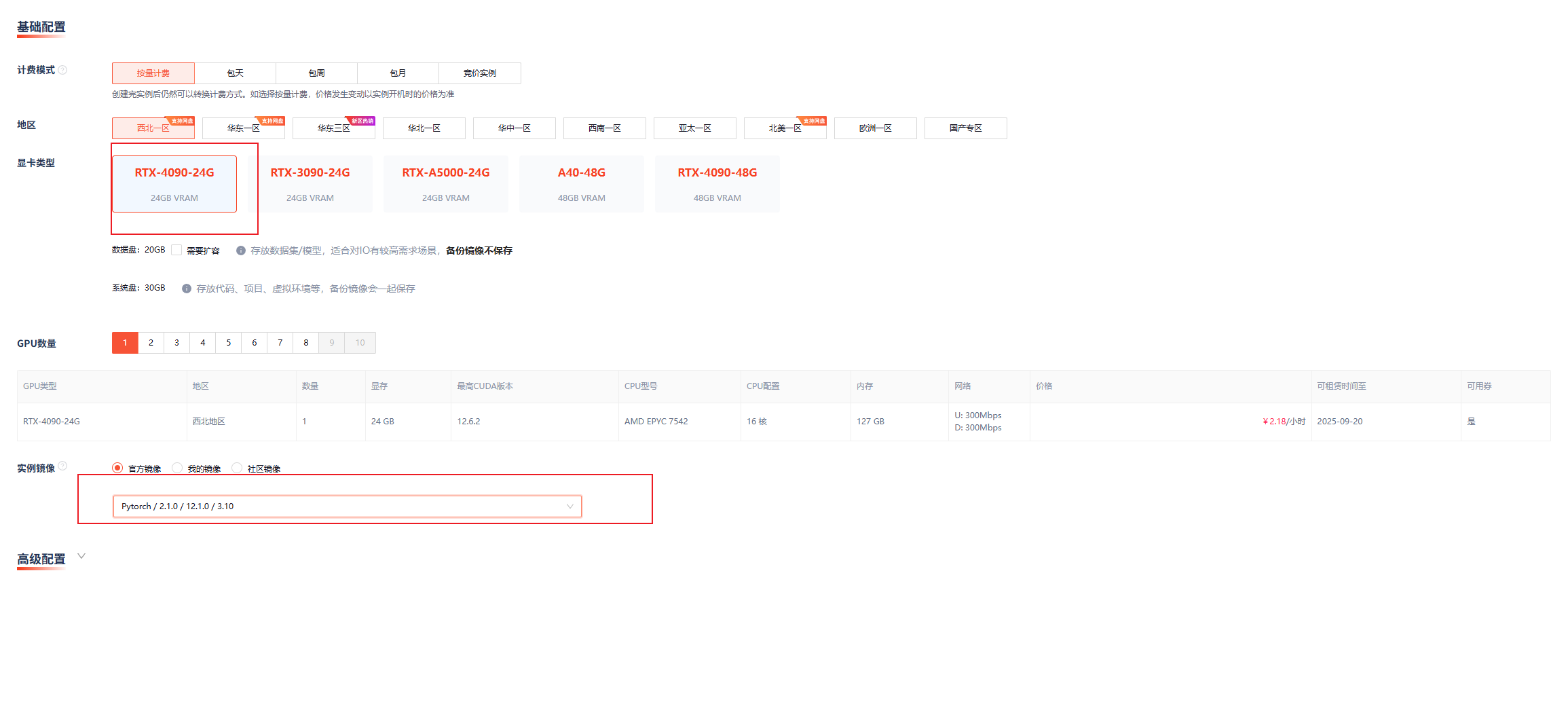
为什么选择GpuGeek训练模型?
1. 性价比突破极限
- RTX 4090实例(24GB显存)实测可运行LLaMA 3-8B的INT4量化版本
- A5000集群(4×24GB)支持8B全参数微调,成本比主流云平台低40%
2. 预置环境开箱即用
平台已预装:
- PyTorch 2.1 + CUDA 12.1
- bitsandbytes(4/8bit量化支持)
- FlashAttention-2(加速训练)
- Hugging Face生态(Transformers, datasets, accelerate)
3. 数据管道优化
- 内置NAS存储实现1.2GB/s的持续读写速度
- rclone工具直接挂载Google Drive/AWS S3数据源
实战:在GpuGeek上快速训练一个图像分类模型(ResNet18+CIFAR10)
接下来我们按照步骤一步步的实现~
步骤1:极速环境搭建
- 创建实例:选择"PyTorch 2.1 (CUDA 12.1)"镜像,RTX4090显卡(无卡模式开机)
- 数据准备(无卡模式下操作):
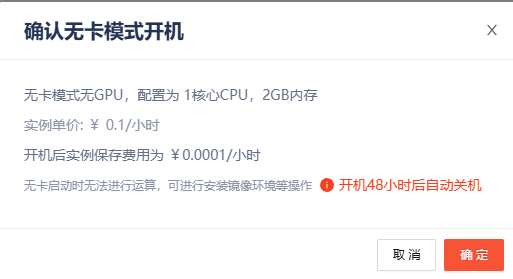
接下来我们找到一个可以SSH连接的工具,这里我们选择WindTerm
通过输入登录指令和密码
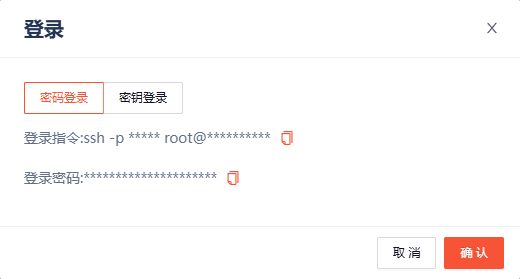
输入完毕在界面显示下面的样例,代表我们成功完成安装
这里我们先不选择无卡模型,代码里面会自动下载数据,故我们直接来就行
步骤2:复制代码训练模型
这里我们选择在服务器新建一个python文件,再将内容复制进去
import torch
from torchvision import datasets, models, transforms
# 1. 加载数据(自动下载CIFAR10)
train_data = datasets.CIFAR10(root='./data', train=True, download=True,
transform=transforms.ToTensor())
# 2. 初始化模型(预训练ResNet18)
model = models.resnet18(weights='IMAGENET1K_V1').cuda()
# 3. 训练(简化版,实际需增加dataloader和loss)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
for images, labels in train_data:
outputs = model(images.cuda())
loss = torch.nn.functional.cross_entropy(outputs, labels.cuda())
loss.backward()
optimizer.step()
# 4. 保存模型
torch.save(model.state_dict(), 'cifar10_resnet18.pth')
然后我们Ctrl+S保存即可
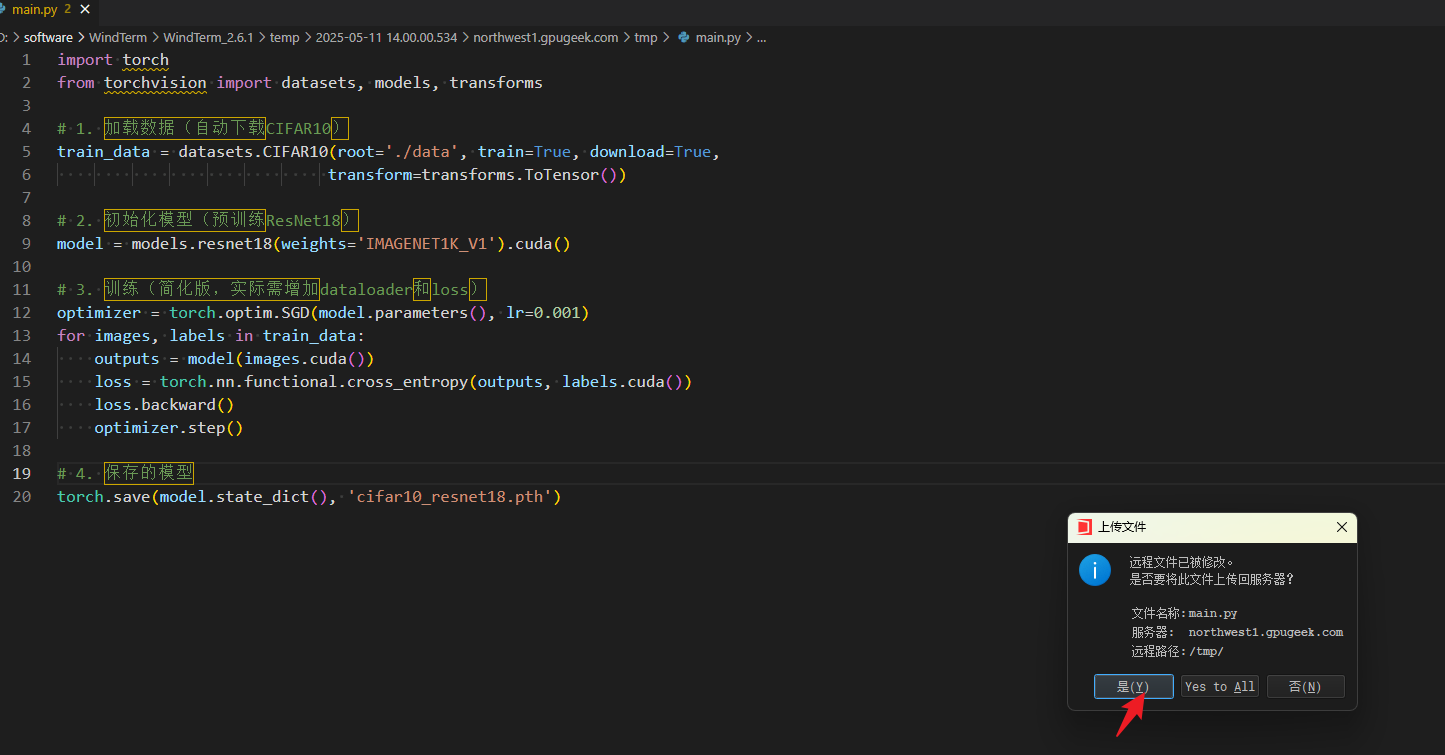
接下来我们执行下面的代码就行运行
python train.py

- 预期输出:
- 自动下载CIFAR10数据集(约160MB)
- 每个batch训练时间约0.2秒(RTX 4090)
步骤3:验证模型
训练完成后,我们可以加以验证
# 加载测试集验证
test_data = datasets.CIFAR10(root='./data', train=False, download=True)
correct = 0
for img, label in test_data:
pred = model(img.cuda()).argmax()
correct += (pred == label.cuda()).sum()
print(f"准确率: {correct/len(test_data):.2%}") # 预期约70%(未调参)
结语
这次在GpuGeek上跑通图像分类全流程,彻底打破了我对AI开发的三个刻板印象:
1️⃣ 便宜到离谱,学生党狂喜
- A5000每小时只要0.88元,一杯奶茶钱能玩5小时
- 按秒计费,训练完立马关机,绝不浪费1分钱
2️⃣ 简单到爆炸,告别配置地狱
- 30秒开机:选镜像→点创建→直接开搞
- 预装所有环境:PyTorch/TensorFlow随便用,再也不用折腾CUDA
- 自动下载数据集:CIFAR10、ImageNet等常见数据集一键加载
3️⃣ 强到没朋友,企业级体验
- 1.2GB/s超快存储:训练数据秒加载,比机械硬盘快10倍
- 多卡并行支持:8卡A100集群,千亿大模型也能跑
- 全球节点加速:香港/美国服务器,跨国协作不卡顿
💡 一句话总结:
“比网吧便宜,比实验室方便,比云厂商快” —— 这才是AI开发者该有的生产力工具!



















 1085
1085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











