










“
火灾监测在工业、家庭和公共场所的安全防护中具有重要意义。借助深度学习和计算机视觉技术,火灾检测的自动化水平显著提升。本文将向您详细介绍如何使用YOLO11对超过13500+标注图片进行模型训练,并基于PYQT5开发一款具备图像、视频和实时摄像头检测功能的可视化软件。当检测到火灾时,系统会自动发出报警提示。文章还将分享数据标注、格式转换、模型训练、软件编写等关键环节,帮助您快速上手并构建自己的火灾检测系统。无论您是深度学习新手,还是希望构建定制化火灾监测系统的开发者,这篇文章都将为您提供清晰的操作指南和实用的技巧。”
火灾烟雾检测
数据标注部分,具体可参考:
【深度学习】YOLOV8数据标注及模型训练方法整体流程介绍及演示
【菜品识别专栏】菜品目标检测数据集标注及处理(Yolov10)
01 提供数据集及软件源码
关注原文,原文中回复关键字 “源码” 获取如下打包内容
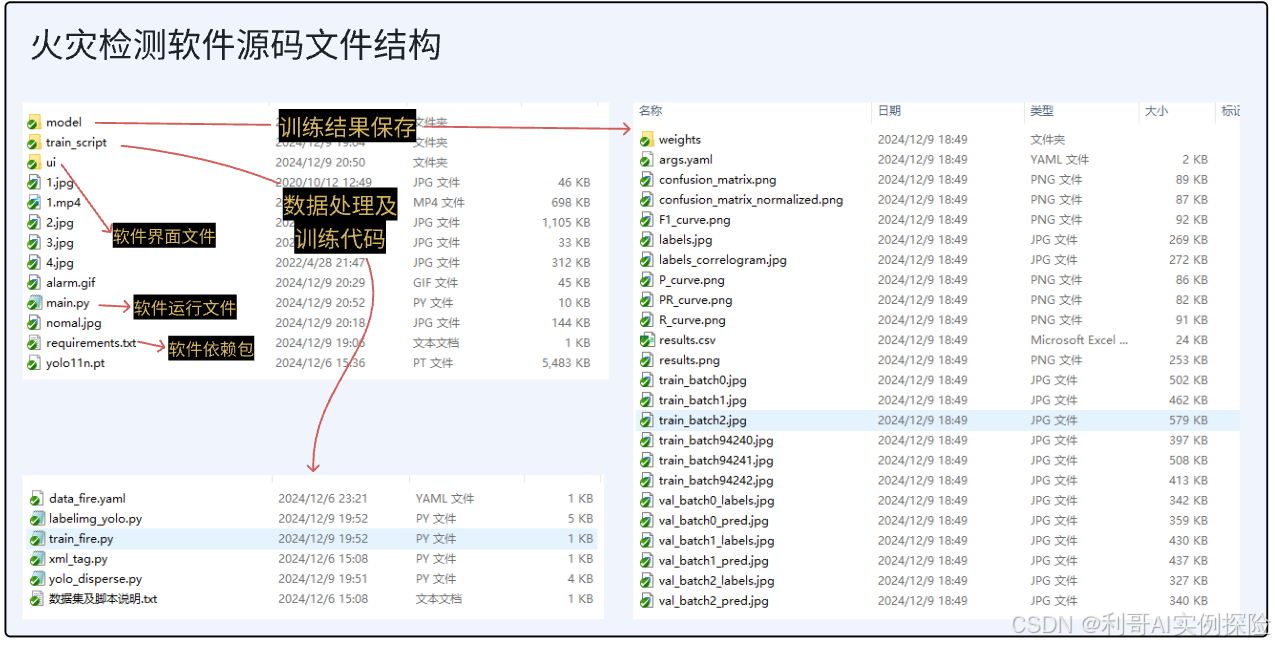
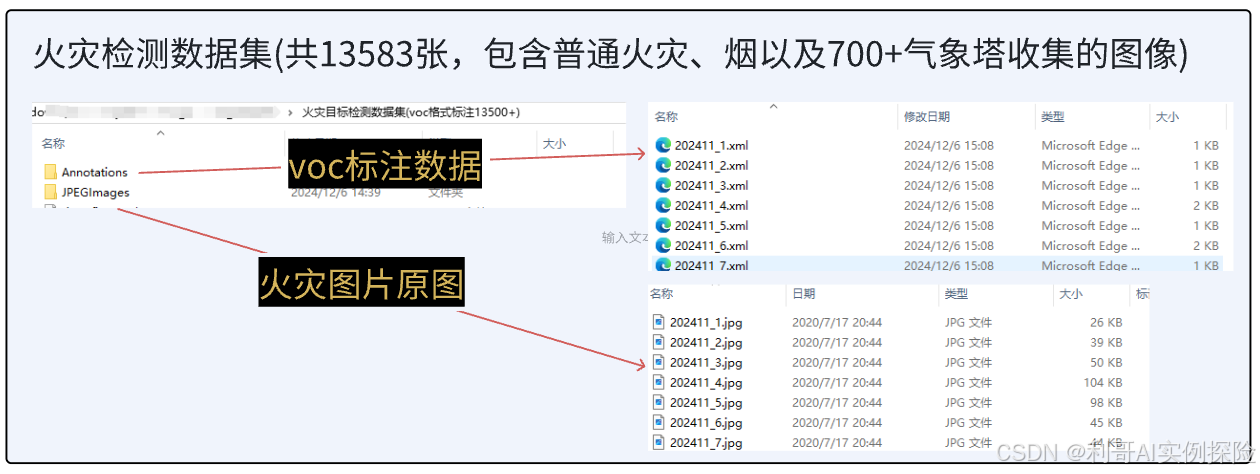
02 数据处理脚本解析
数据处理脚本:
xml_tag.py:将所有标注文件xml标签,统一改为fire
labelimg_yolo.py:将voc xml标注的数据集,统一转换成yolo训练格式,会形成labels目录
yolo_disperse.py:将数据集以8:1:1的比例,随机分为训练集、测试集和验证集
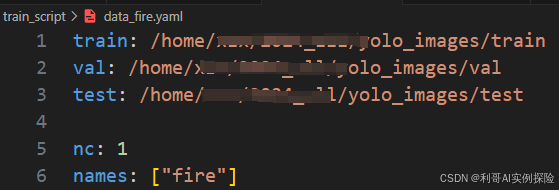
数据处理完成后,进行数据文件配置
data_fire.yaml:训练数据的配置文件
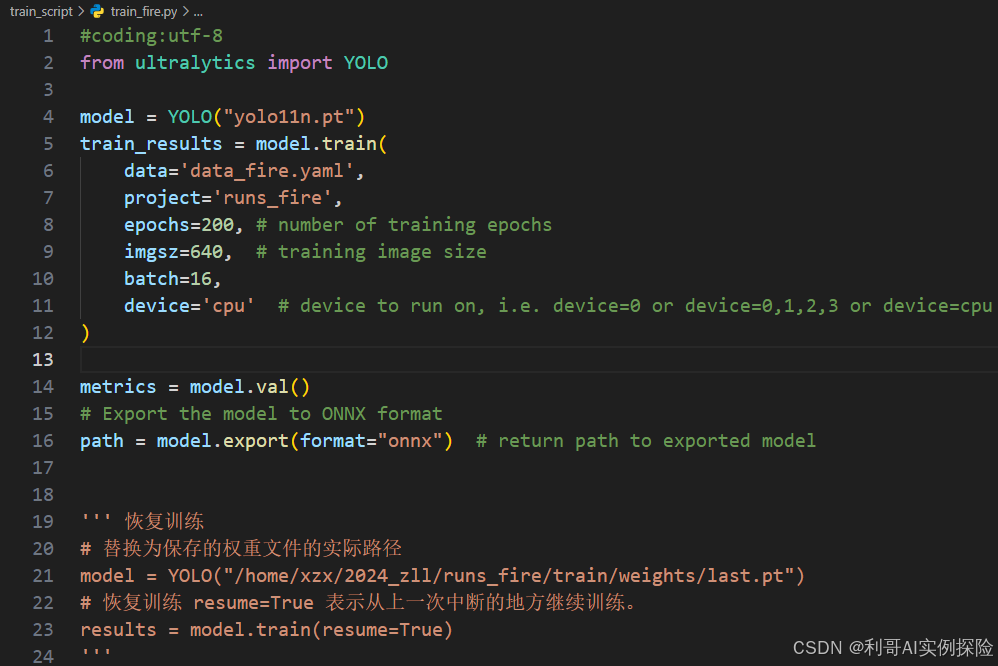
train_fire.py:训练的文件及参数配置,运行即可启动训练。
03 训练结果评估

混淆矩阵,混淆矩阵以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。其中矩阵的行表示真实值,矩阵的列表示预测值。
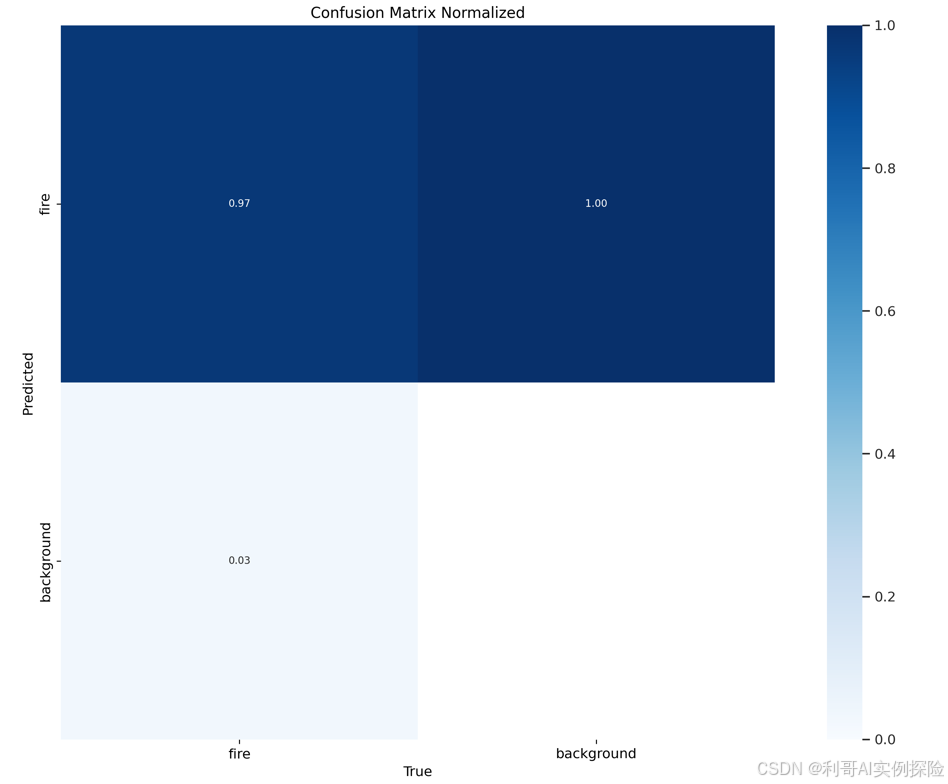
F1曲线:查准率和召回率的调和平均数,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,其中1是最好,0是最差。置信度阈值较高的时候,置信度高的样本才能被认为是真,类别检测的越准确,即精准率较大。
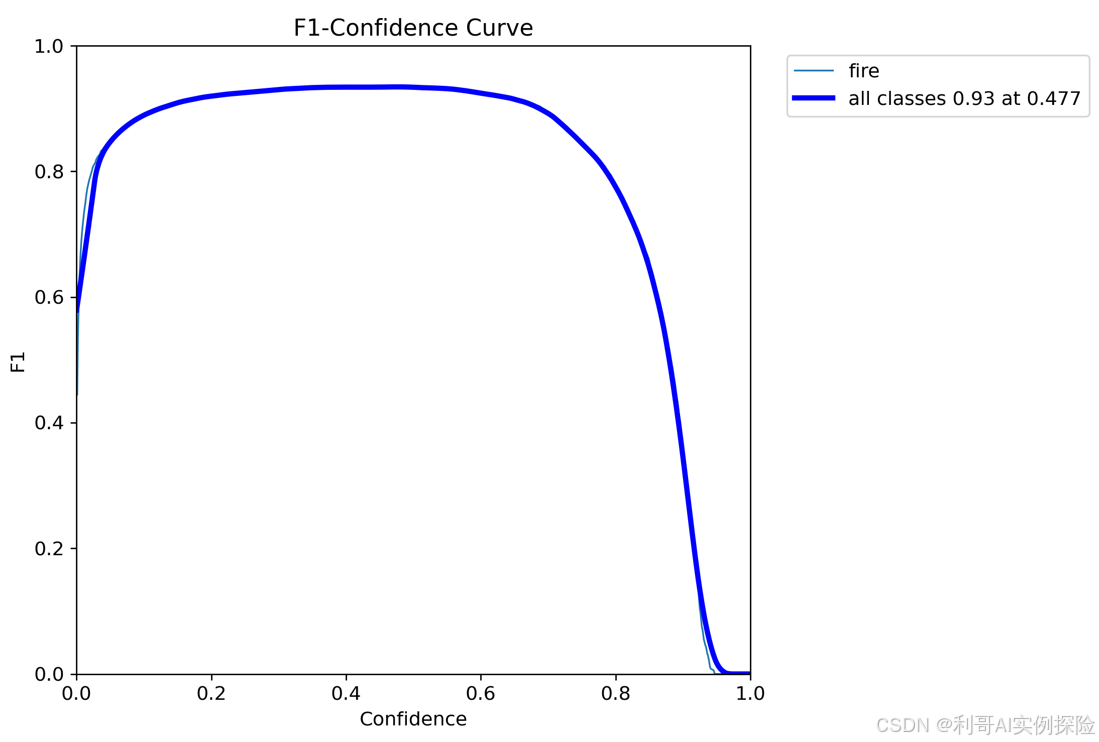
单一类准确率,置信度阈值 - 准确率曲线图,准确率precision和置信度confidence的关系图。
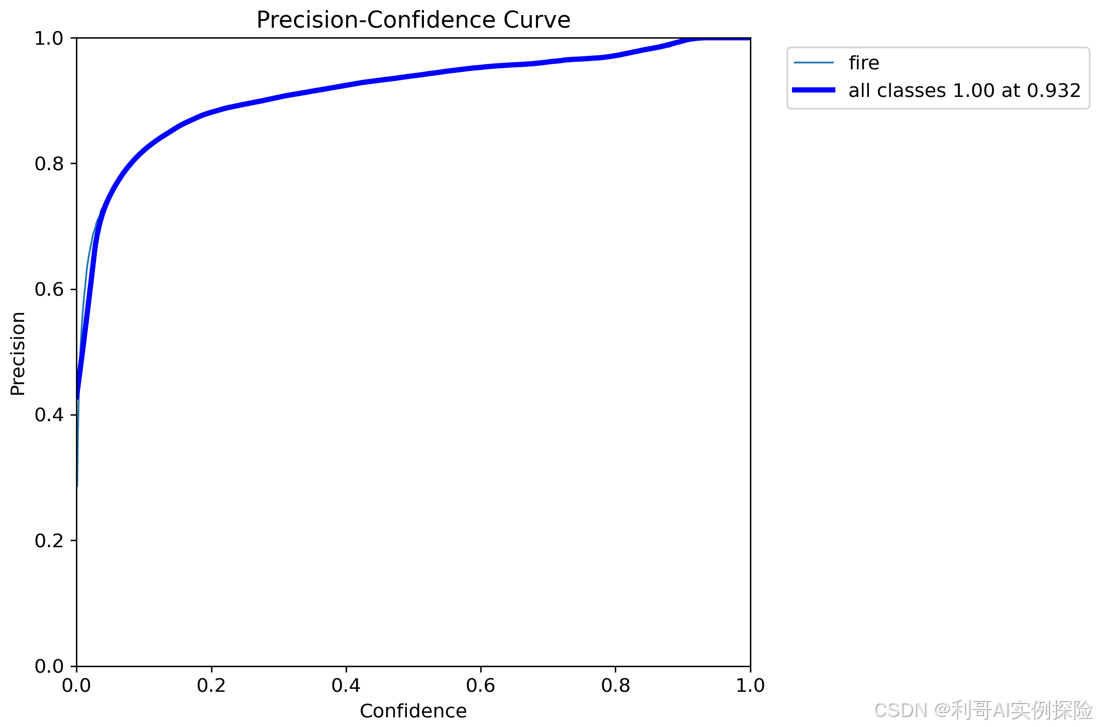
PR曲线体现精确率和召回率的关系。mAP是Mean Average Precision 的缩写,即 均值平均精度
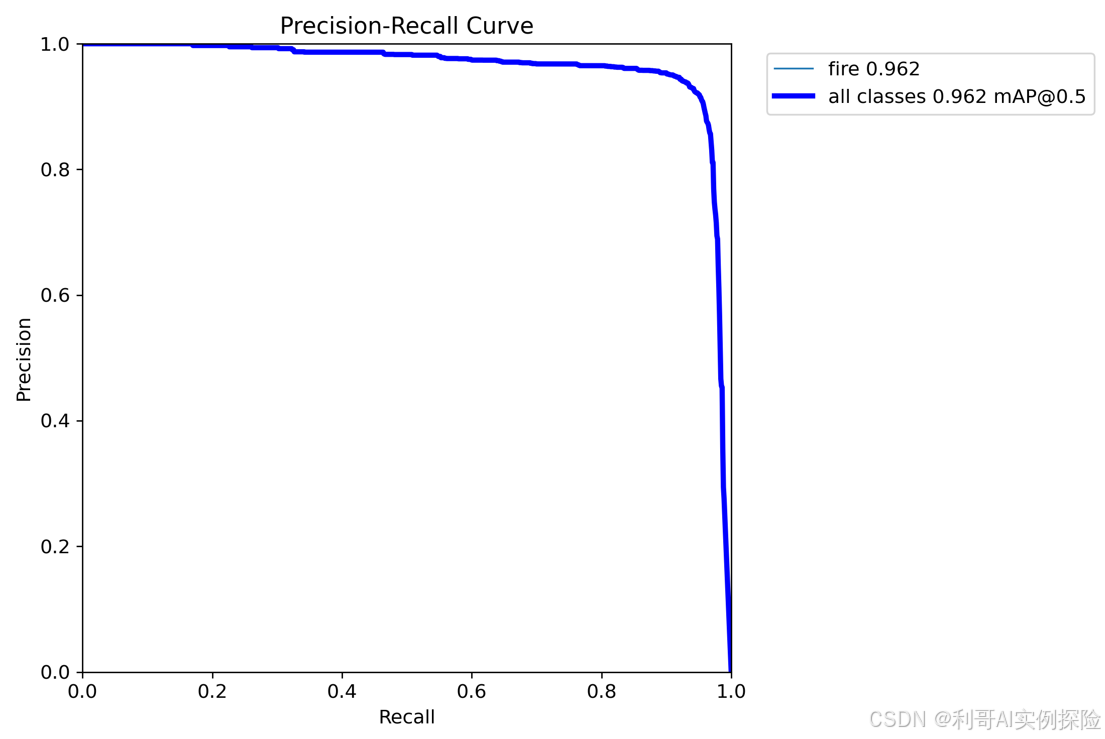
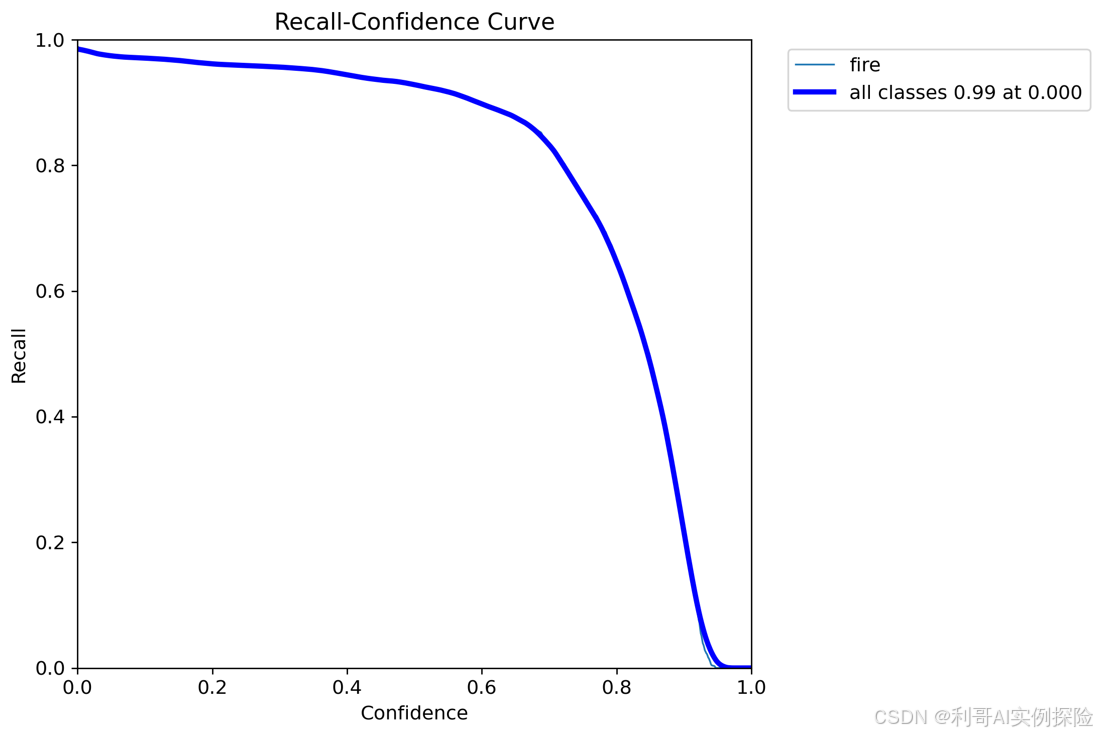
置信度阈值 - 召回率曲线图,召回率recall和置信度confidence之间的关系,recall(真实为positive的准确率),即正样本有多少被找出来了(召回了多少)。当置信度越小的时候,类别检测的越全面(不容易被漏掉,但容易误判)。
有关训练结果评估,更多内容,可关注另外一篇文章:
【深度学习】深度学习模型训练结果分析及效果评估以及Yolo训练结果解释
04 推理及软件逻辑处理
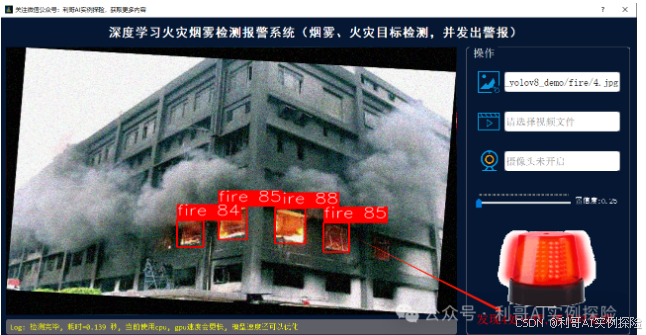
模型加载及推理源码逻辑:
from ultralytics import YOLO
model = YOLO("model/weights/best.pt", task='detect')
# 目标检测及结果解析
def detect_draw(self, img):
results = self.model(img, conf=self.conf, iou=self.iou)
names = results[0].names
boxes = results[0].boxes.xyxy.tolist()
classes = results[0].boxes.cls.tolist()
confidences = results[0].boxes.conf.tolist()
array_data = []
for box, cls, conf in zip(boxes, classes, confidences):
x1, y1, x2, y2 = box
tag = names[int(cls)]
score = int(round(conf,2)*100)
array_data.append({'x1': int(x1), 'y1': int(y1), 'x2': int(x2), 'y2': int(y2), 'tag': tag, 'score': score})
return array_data
# 向图片上画识别结果
def draw_rect_msg(sef, img, array_data):
for data in array_data:
x1 = int(data['x1'])
y1 = int(data['y1'])
x2 = int(data['x2'])
y2 = int(data['y2'])
tag = data['tag']
score = data['score']
# (0, 255, 0): BGR thickness定义矩形框的粗细
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 0, 255), thickness=2)
text = f'{tag} {score}'
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1
thickness = 1
# 计算文本的宽度和高度
(text_width, text_height), baseline = cv2.getTextSize(text, font, font_scale, thickness)
# 定义红色矩形的左上角和右下角坐标 (注意让矩形包裹文本)
top_left = (x1, y1 - text_height - baseline)
bottom_right = (x1 + text_width, y1)
# 画红色矩形作为背景
cv2.rectangle(img, top_left, bottom_right, (0, 0, 255), -1) # 红色 (BGR: (0, 0, 255)), -1 表示填充
# 在红色矩形上绘制白色文本
cv2.putText(img, text, (x1, y1 - baseline), font, font_scale, (255, 255, 255), thickness, cv2.LINE_AA)
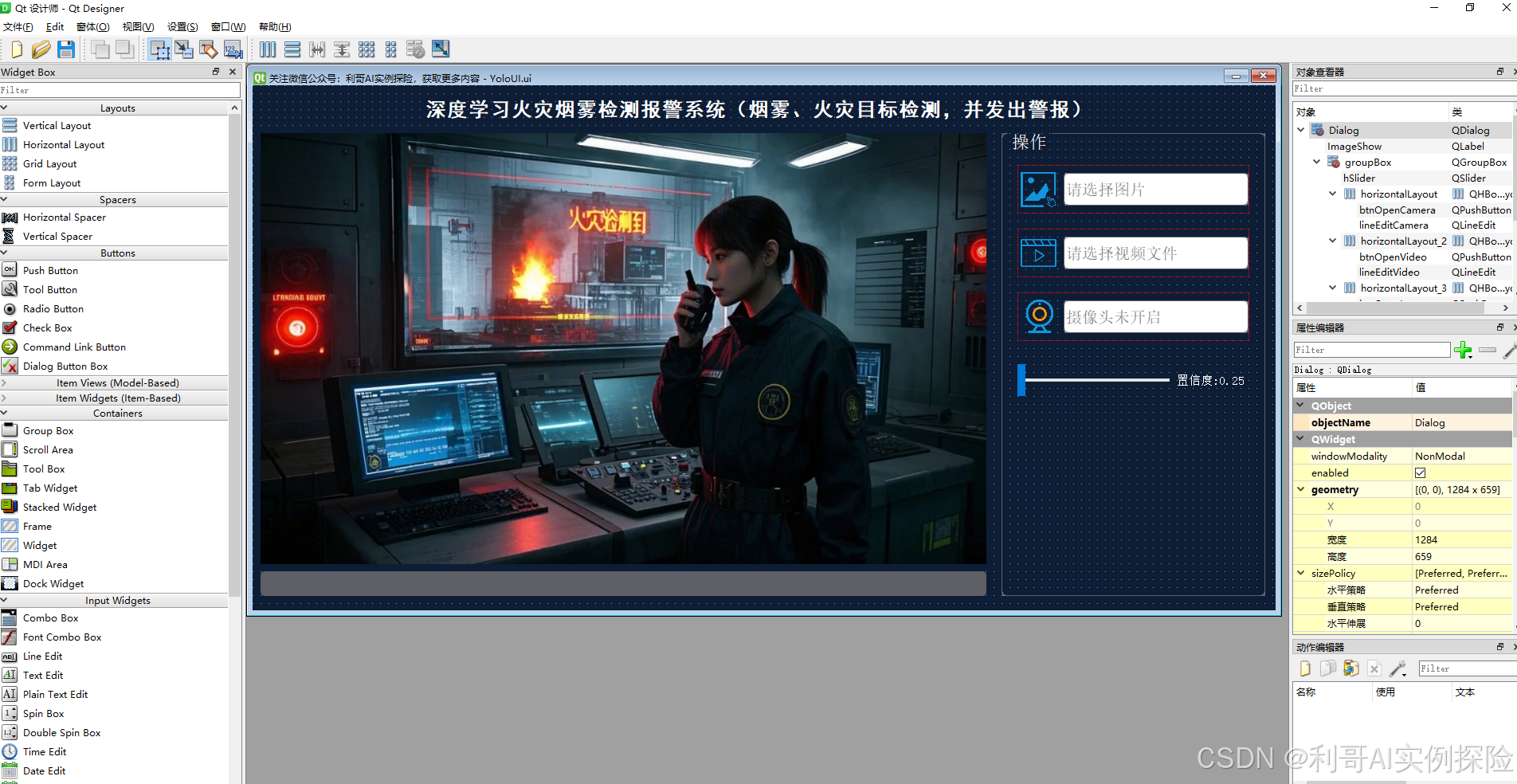
界面设计及展示:
为回馈大家的支持,原文链接中一些由本人编写的机器学习、深度学习系统源码,关注,发送消息 “源码”,会自动弹出源码下载链接,里面汇集了很多优质源码,基本都是免费分享,可放心下载。


















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











