









论文地址:https://arxiv.org/abs/1904.11486
GitHub:https://github.com/adobe/antialiased-cnns/blob/master/antialiased_cnns
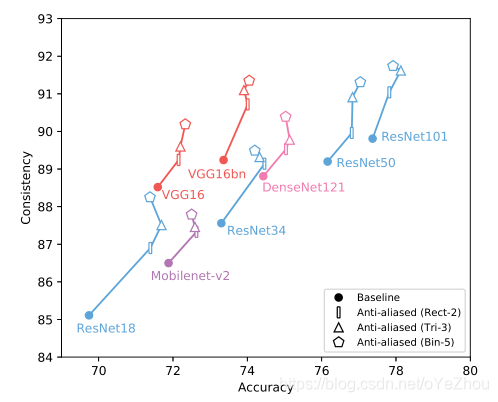
1、动机
作者发现,CNNs是不具备平移不变性的,因为当输入发生微小的平移或者变换的时候,输出会产生剧烈变化,如下图1中黑色线条所示:
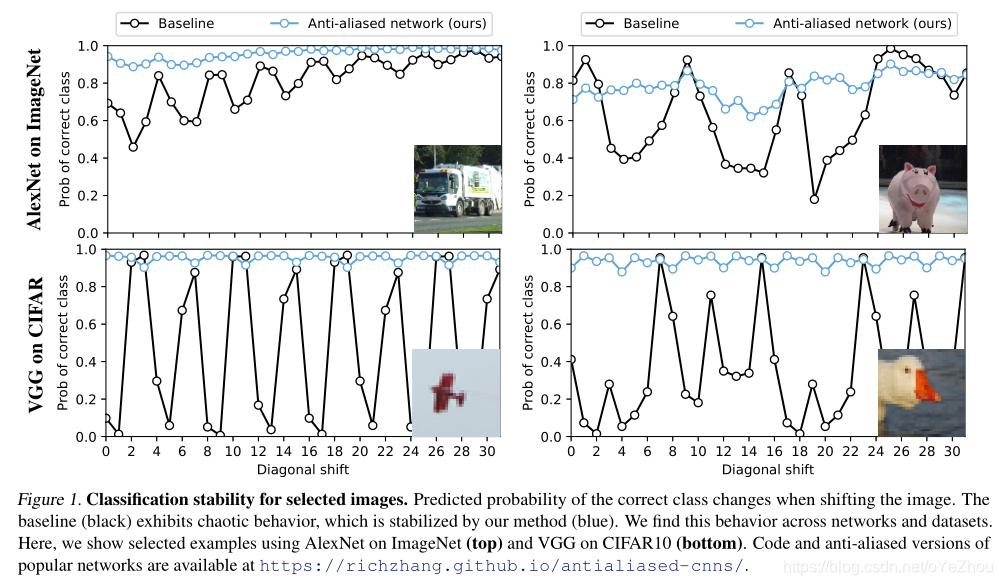
作者分析,这是由于带有下采样的操作(如步长>2的卷积、池化)所带来的,因为这些下采样方法忽略了信号处理领域的一个常识:在对信号下采样之前,需要使用低通滤波来抗混叠。但是,直接将低通滤波器插入到网络中,会带来性能下降。
于是,作者将低通滤波器与现有方法相融合,提出了BlurPool方法。
2、方法
2.1、平移不变性和平移等变性
对于一个函数,如果输出随着输入一同发生平移,则改函数具备平移等变性:
(1)
如果输入发生平移,而输出不变,则说明改函数具备平移不变性:
(2)
很多时候,公式(1)和(2)只在平移量为N的整数倍时才成立,此时,称之为“周期平移不变性/等变性”。
2.2、BlurPool和现有方法的融合
所提出的BlurPool方法能够集成到现有的一些操作中,如MaxPooling、Strided-Convolution、AveragePooling,各集成方法如图2所示:
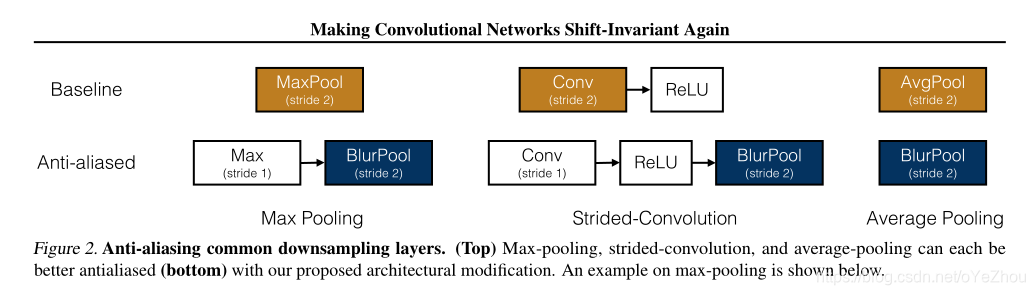
- 对于MaxPooling,可将其分解为两个部分:步长为1的Max和步长为2的BlurPool;
- 同理,步长为2的Conv+ReLU可以分解为:步长为1的Conv+ReLU+步长为2的BlurPool;
- 同理,AvgPool可等价于步长为2的BlurPool。
以MaxPooling为例,其分解前后示意如图3所示:
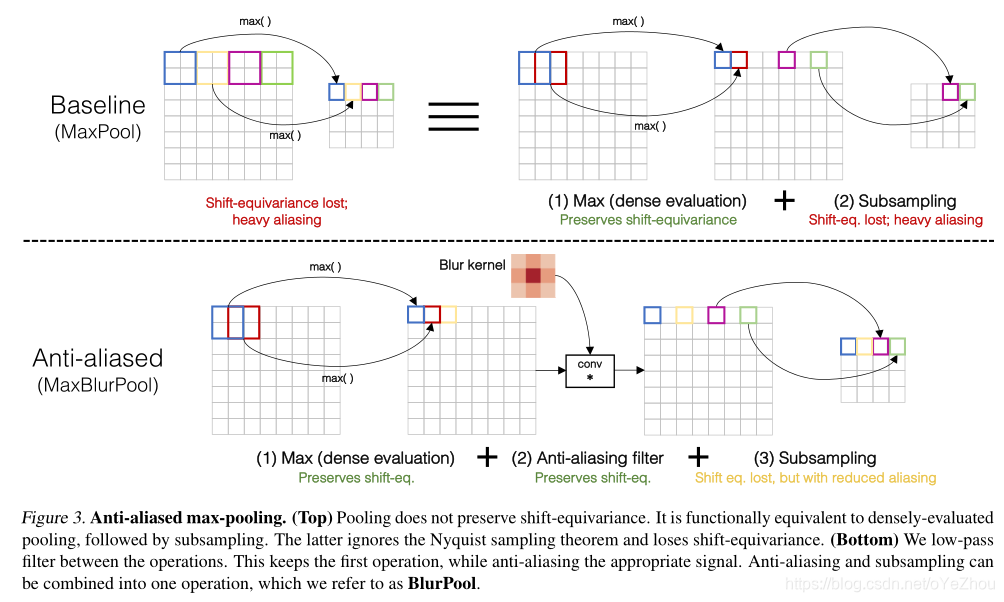
不过值得一提的是,BlurPool并没有解决平移不变性的丢失,不过可以在很大程度上进行缓解,也即如上图3Bottom部分所示。
3、Pytorch实现
import torch
import torch.nn.parallel
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
class BlurPool(nn.Module):
def __init__(self, channels, pad_type='reflect', filt_size=4, stride=2, pad_off=0):
super(BlurPool, self).__init__()
self.filt_size = filt_size
self.pad_off = pad_off
self.pad_sizes = [int(1. * (filt_size - 1) / 2), int(np.ceil(1. * (filt_size - 1) / 2)),
int(1. * (filt_size - 1) / 2), int(np.ceil(1. * (filt_size - 1) / 2))]
self.pad_sizes = [pad_size + pad_off for pad_size in self.pad_sizes]
self.stride = stride
self.off = int((self.stride - 1) / 2.)
self.channels = channels
if self.filt_size == 1:
a = np.array([1., ])
elif self.filt_size == 2:
a = np.array([1., 1.])
elif self.filt_size == 3:
a = np.array([1., 2., 1.])
elif self.filt_size == 4:
a = np.array([1., 3., 3., 1.])
elif self.filt_size == 5:
a = np.array([1., 4., 6., 4., 1.])
elif self.filt_size == 6:
a = np.array([1., 5., 10., 10., 5., 1.])
elif self.filt_size == 7:
a = np.array([1., 6., 15., 20., 15., 6., 1.])
filt = torch.Tensor(a[:, None] * a[None, :])
filt = filt / torch.sum(filt)
self.register_buffer('filt', filt[None, None, :, :].repeat((self.channels, 1, 1, 1)))
self.pad = get_pad_layer(pad_type)(self.pad_sizes)
def forward(self, inp):
if self.filt_size == 1:
if self.pad_off == 0:
return inp[:, :, ::self.stride, ::self.stride]
else:
return self.pad(inp)[:, :, ::self.stride, ::self.stride]
else:
return F.conv2d(self.pad(inp), self.filt, stride=self.stride, groups=inp.shape[1])
def get_pad_layer(pad_type):
if pad_type in ['refl', 'reflect']:
PadLayer = nn.ReflectionPad2d
elif pad_type in ['repl', 'replicate']:
PadLayer = nn.ReplicationPad2d
elif pad_type == 'zero':
PadLayer = nn.ZeroPad2d
else:
print('Pad type [%s] not recognized' % pad_type)
return PadLayer


















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











