









paper:https://arxiv.org/abs/2012.11879
github:GitHub - cfzd/FcaNet: FcaNet: Frequency Channel Attention Networks
目录
1. 动机
注意力机制,尤其是通道注意力,在CV领域取得了巨大成功。大部分研究都集中在如何设计更高效的通道注意力机制,却忽略了一个基本问题,也即:他们都是使用全局平均池化(GAP)来作为预处理方法。尽管GAP十分简单高效,但他的捕获的信息也确实不足。那么,有没有更好的预处理方式呢?
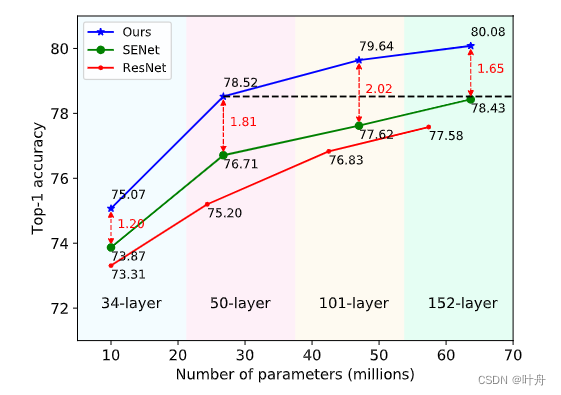
这篇文章提供了一个新的视角:从频域对注意力进行重新思考,并从数学上证明了GAP就是频域特征分解的一个特例。基于此,作者将通道注意力机制的预处理泛化到了频域,并基于多光谱通道注意力构建了FcaNet。这种方法将SENet-50在ImageNet上的top-1准确率提升了1.8%。
2. 方法
2.1. 回顾通道注意力和离散余弦变换(DCT)
通道注意力:
在CNN中常用通道注意力来对不同通道的特征进行加权。对于输入,通道注意力模块可表示为:

其中就是注意力向量,这种一维的向量和原始输入X对应通道相乘,即可产生注意力的效果:
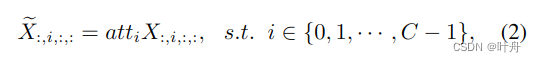
离散余弦变换(DCT):
对于一维信号,其DCT公式表示为:
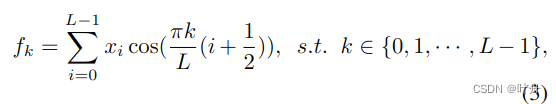
对于二维信号,则其2d DCT就是:
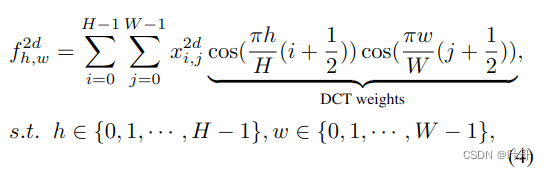
相应的,逆2D DCT可表示为:
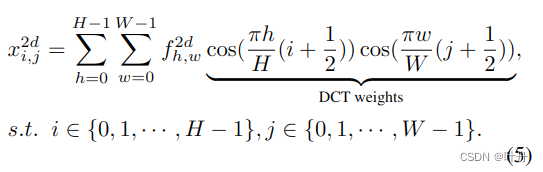
从通道注意力和DCT可以总结两点:
- 1)通道注意力使用GAP进行数据预处理;
- 2)DCT可以看做输入的加权和,上述DCT公式中的cos部分可以当做权重。
对于GAP,它是对输入的feature map每个通道求全局平均,其实可以看作一种最简单频谱。也正是因为简单,其所包含的信息也是不足的,因此本文探索了更复杂的频谱,来代替GAP。
2.2. 多光谱通道注意力
通道注意力的理论分析:
上面已经讨论过,DCT可以看作输入的加权和,而GAP是2D DCT的一个特例。因此提出以下定理:
定理一:GAP 是 2D DCT 的一个特例,其结果与 2D DCT 的最低频率分量成正比。
证明:
假设公式4中的h和w都为0,则有:
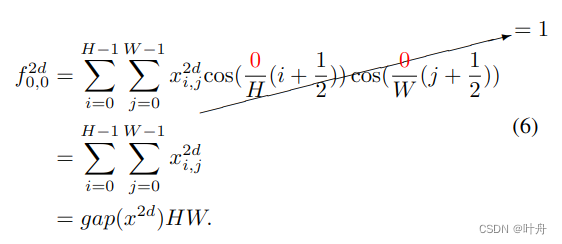
在公式6中,表示2D DCT的最低频率分量,且与GAP成正比。至此,定理一得证。
既然GAP是2D DCT的一个特例,那么是否可以考虑再加入其他分量呢?作者正是这样想的,所以接下来讨论了一下融合其他频率分量的可能性。
简单起见,使用B来表示2D DCT的基函数:
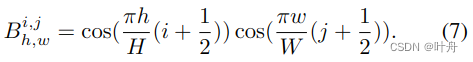
则公式5中的2D DCT可以改写为:
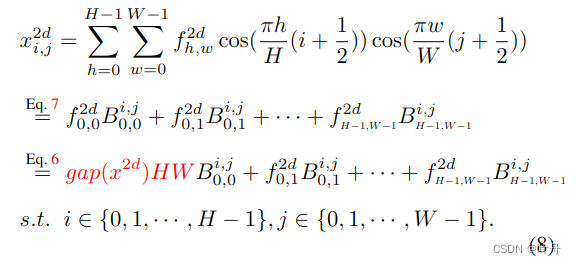
从上述公式8可以看出,公式1所表示的通道注意力只是DCT中的一个分量,而其余的分量则被舍弃了:
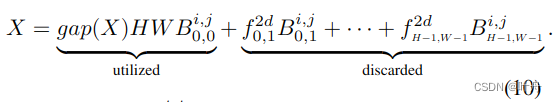
其中是一个恒定的比例因子,可以在注意力机制中被忽略。
自然地,可以想到把其他的频率分量也考虑进来,是不是就可以获取信息更丰富的通道注意力了呢?这就是下面要讲的多光谱注意力模块。
多光谱注意力模块:
首先,将输入X沿着通道分为多个部分,表示为,其中
, C 可以被n整除。对于每个部分,分配相应的 2D DCT 频率分量,2D DCT 结果可以用作通道注意力的预处理结果。如此则有:
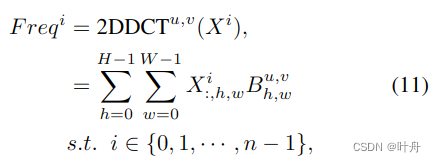
其中[u, v]为xi对应的频率分量2D指数 ,而则是预处理后的C'维的向量。整体预处理的向量可以通过拼接得到:
![]()
其中的Freq则是获得的多光谱向量。整体的多光谱通道注意力就可以写为:
![]()
从式12和13,可以看到提出的方法包括了 GAP 的原始方法,并从最低频率分量推广到具有多个频率源。如此,解决了原始方法不足的问题。总体框架如图2所示:
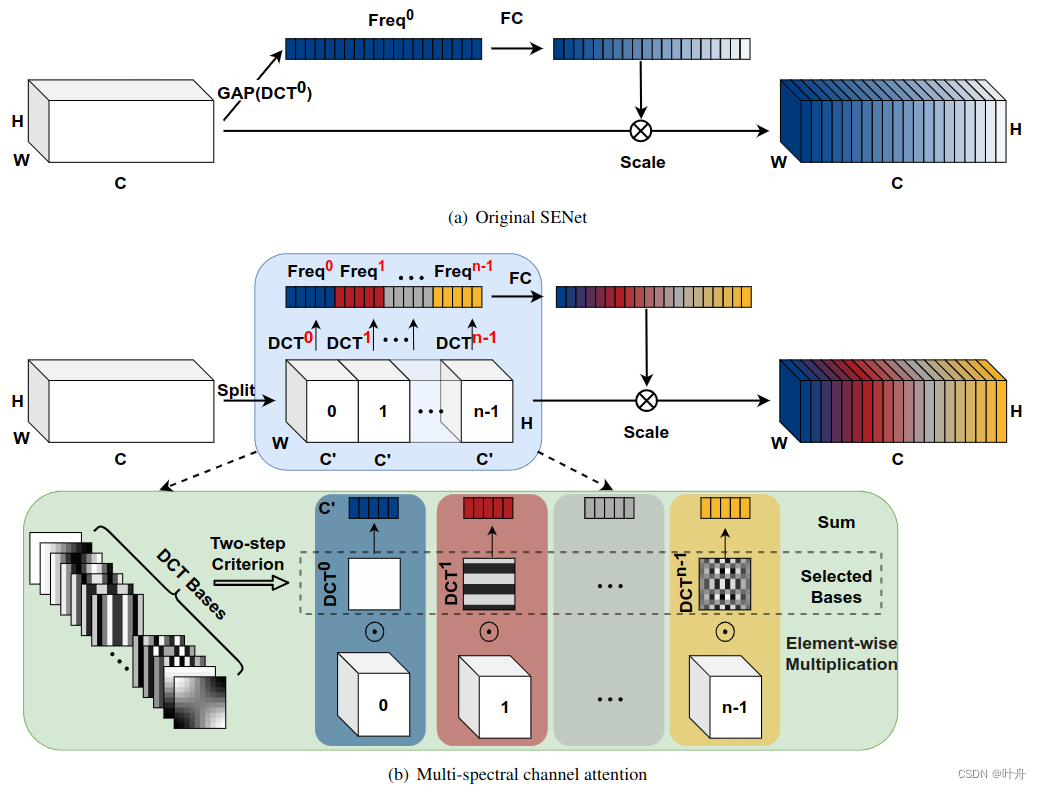
选择频率分量的标准:
如何为X的每个部分选择合适的频率分量[u,v]是一个重要问题。对于空间大小为 H × W 的每个通道,我们可以得到 2D DCT 之后的 HW 频率分量。在这种情况下,这些频率分量的组合总数为 CHW。例如,ResNet-50 主干的 C 可能等于 2048。测试所有组合是昂贵的。因此,我们提出了一种启发式两步标准来选择多光谱注意模块中的频率分量。
主要思想是首先确定每个频率分量的重要性,然后确定将不同数量的频率分量一起使用的效果。首先,我们分别检查通道注意中每个频率分量的结果。然后,我们根据结果选择 Topk 最高性能频率分量。这样,就可以满足多光谱通道注意力。
2.3. 讨论
多光谱框架是如何嵌入更多的信息的:
上面已经证明GAP只是2D DCT的一个特例,其只考虑最低的频率分量,而丢弃了其他频率分量;而进一步考虑利用起来其他频率分量能够丰富通道注意力的的信息量。那么,这些多光谱的频率分量为什么能够嵌入更多信息呢?
这里,作者给出了一个思想实验:
众所周知,深度网络是冗余的。对于两个冗余通道,使用GAP可以获取相同的信息,但在所提出的多光谱框架中,却可以获取更多不同的信息,因为不同的频率分量包含的信息不同。这样一来,所提出的多光谱框架可以在通道注意机制中嵌入更多的信息。
这部分我的个人理解是:两个通道里面的feature map中的每个像素值大概率是不同的,直接GAP是有可能获取相似的值的(也就是所谓的两个通道冗余了),但如果对这两个通道使用不同的频率分量进行信息提取,那它们的结果就很可能不一样了(也就是不冗余了);所以这种多光谱框架其实就是从原先看似冗余的通道之间建模了一丝细微的差别出来,从而丰富了或者说细化了通道注意力的信息提取能力。
复杂度分析:
从参数数量和计算成本两个方面分析了此方法的复杂性。对于参数数量,与基线 SENet 相比,我们的方法没有额外的参数,因为 2D DCT 的权重是预先计算的常数。对于计算成本,我们的方法的额外成本可以忽略不计,可以被视为具有与SENet相同的计算成本。使用 ResNet-34、ResNet-50、ResNet101 和 ResNet-152 主干,与 SENet 相比,我们的方法的相对计算成本分别提高了 0.04%、0.13%、0.11% 和 0.11%。
只需一行代码改动:
所提出的多光谱框架的另一个重要特性是,它可以通过现有的通道注意实现轻松实现。如前面所述,2D DCT可以看作是输入的加权和。这样,我们的方法的实现可以简单地通过元素乘法和求和来实现。实现如图3所示:

3. 实验结果
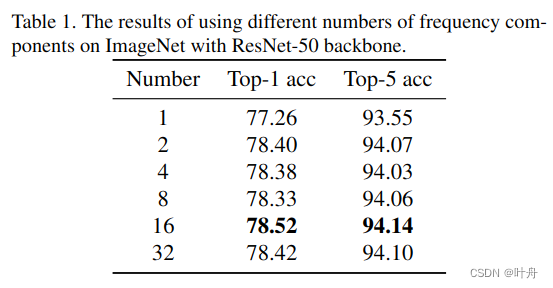
使用不同数量的频率分量,得到效果如下表,可以看出16个分量效果最好。
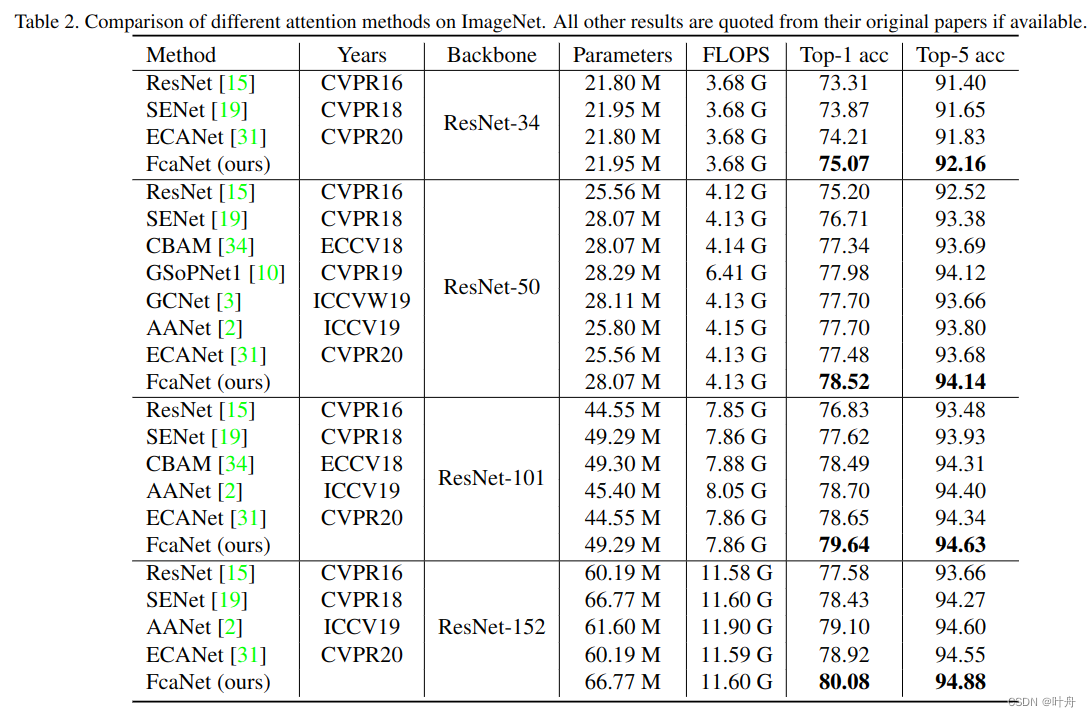
在ImageNet上,FacNet明显优于其他方法:
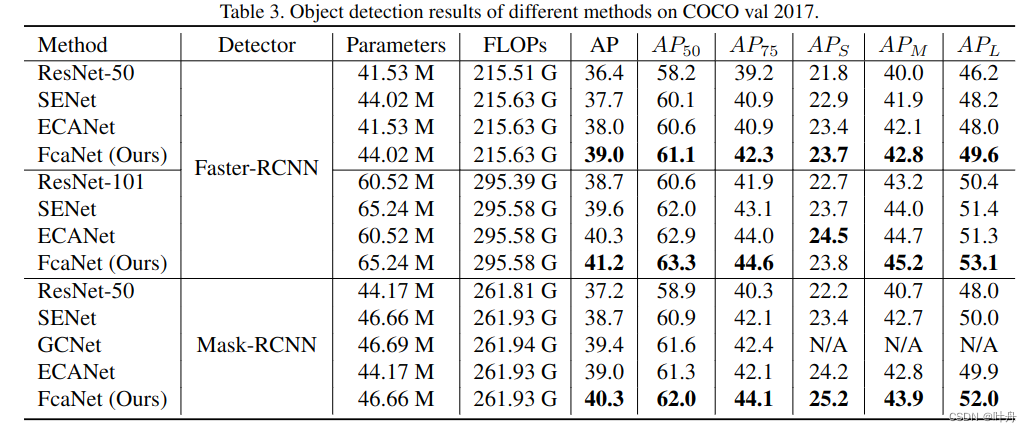
在COCO上,也有优异表现:
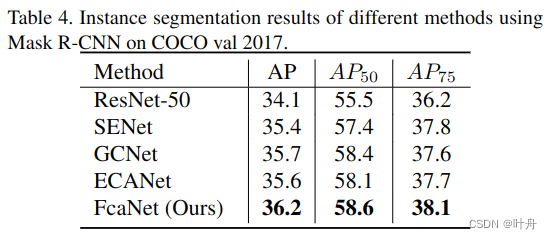
实例分割同样毫不示弱:
4. 总结
本文针对SE通道注意力中使用GAP作为预处理存在的问题,即其获取的信息太过简单,提出了从频域分析获取更丰富信息的多光谱通道注意力方法,并提出了带有多光谱通道注意力的FcaNet网络,从频域泛化了已有的通道注意力。同时,在多光谱框架中探索了频率分量的不同组合,并提出了频率分量选择的两步标准。实验表明,在相同的参数量和相同计算量上,可以获取比SENet更优的效果。与其他通道注意方法相比,还在图像分类、目标检测和实例分割方面取得了最先进的性能。此外,FcaNet 简单而有效,可以基于现有的通道注意方法仅使用一行代码更改来实现。
5. 代码
虽然文章提供了SE和所提出多光谱通道注意力的对比,不过实际实现略有不同。从github上可以找到其代码(具体参考https://github.com/cfzd/FcaNet/blob/master/model/layer.py):
class MultiSpectralAttentionLayer(torch.nn.Module):
def __init__(self, channel, dct_h, dct_w, reduction = 16, freq_sel_method = 'top16'):
super(MultiSpectralAttentionLayer, self).__init__()
self.reduction = reduction
self.dct_h = dct_h
self.dct_w = dct_w
mapper_x, mapper_y = get_freq_indices(freq_sel_method)
self.num_split = len(mapper_x)
mapper_x = [temp_x * (dct_h // 7) for temp_x in mapper_x]
mapper_y = [temp_y * (dct_w // 7) for temp_y in mapper_y]
# make the frequencies in different sizes are identical to a 7x7 frequency space
# eg, (2,2) in 14x14 is identical to (1,1) in 7x7
self.dct_layer = MultiSpectralDCTLayer(dct_h, dct_w, mapper_x, mapper_y, channel)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
n,c,h,w = x.shape
x_pooled = x
if h != self.dct_h or w != self.dct_w:
x_pooled = torch.nn.functional.adaptive_avg_pool2d(x, (self.dct_h, self.dct_w))
# If you have concerns about one-line-change, don't worry. :)
# In the ImageNet models, this line will never be triggered.
# This is for compatibility in instance segmentation and object detection.
y = self.dct_layer(x_pooled)
y = self.fc(y).view(n, c, 1, 1)
return x * y.expand_as(x)其中的self.dct_layer(也即是所谓的只需改动一行代码)定义如下:
class MultiSpectralDCTLayer(nn.Module):
"""
Generate dct filters
"""
def __init__(self, height, width, mapper_x, mapper_y, channel):
super(MultiSpectralDCTLayer, self).__init__()
assert len(mapper_x) == len(mapper_y)
assert channel % len(mapper_x) == 0
self.num_freq = len(mapper_x)
# fixed DCT init
self.register_buffer('weight', self.get_dct_filter(height, width, mapper_x, mapper_y, channel))
# fixed random init
# self.register_buffer('weight', torch.rand(channel, height, width))
# learnable DCT init
# self.register_parameter('weight', self.get_dct_filter(height, width, mapper_x, mapper_y, channel))
# learnable random init
# self.register_parameter('weight', torch.rand(channel, height, width))
# num_freq, h, w
def forward(self, x):
assert len(x.shape) == 4, 'x must been 4 dimensions, but got ' + str(len(x.shape))
# n, c, h, w = x.shape
x = x * self.weight
result = torch.sum(x, dim=[2,3])
return result
def build_filter(self, pos, freq, POS):
result = math.cos(math.pi * freq * (pos + 0.5) / POS) / math.sqrt(POS)
if freq == 0:
return result
else:
return result * math.sqrt(2)
def get_dct_filter(self, tile_size_x, tile_size_y, mapper_x, mapper_y, channel):
dct_filter = torch.zeros(channel, tile_size_x, tile_size_y)
c_part = channel // len(mapper_x)
for i, (u_x, v_y) in enumerate(zip(mapper_x, mapper_y)):
for t_x in range(tile_size_x):
for t_y in range(tile_size_y):
dct_filter[i * c_part: (i+1)*c_part, t_x, t_y] = self.build_filter(t_x, u_x, tile_size_x) * self.build_filter(t_y, v_y, tile_size_y)
return dct_filter

















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











