







Embedding 模型的主要任务是将文本转换为数值向量表示。这些向量可以用于计算文本之间的相似度、进行信息检索和聚类分析。
Embedding 模型的输出是数值向量。计算机在理解词句含义的时候,是不具备能力的,计算机只能看到一段 01010111 这样的结果。然而,人类看到的词句,是赋予了内部的含义,还带了大量的普世认知。
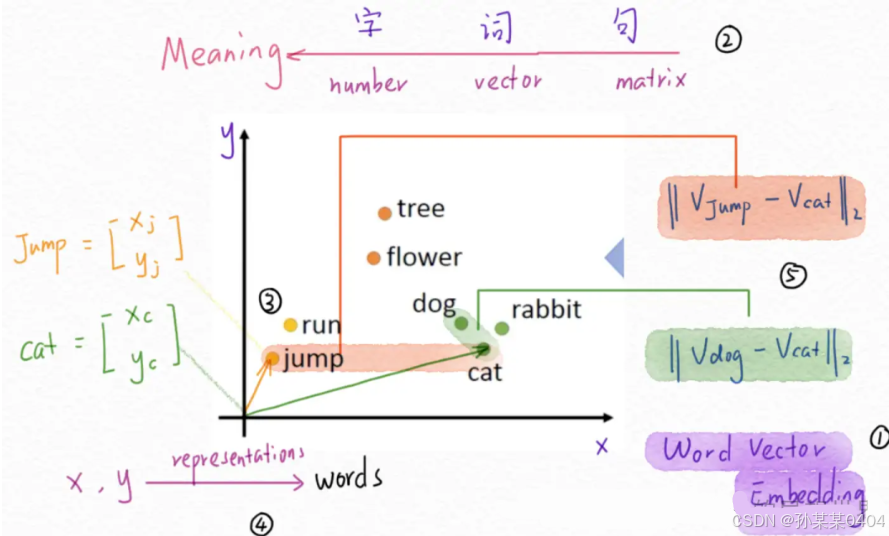
当我们人类理解 猫 vs 狗 和 狗 vs 花的差异的时候,能自然的理解,觉得猫和狗是更加相近的物种;而狗和花,一个是动物,另一个是植物,偏差会更多。
那么,如何让计算机能理解这些词背后的含义呢。所使用的技术就是 Embedding。一句话简单说,embedding 就是把计算机无法理解的字词,转换成一个向量矩阵。
比较相似,或者含意比较接近的词向量之间的距离,是更加接近的。比如 dog 和 cat,dog 和 rabbit; 然而,flower 和 dog,就会隔得比较远。
Embedding 模型广泛应用于文本相似度计算、信息检索、聚类和推荐系统。
在大模型知识库领域中,单独设置 Embedding 模型可以降低系统资源占用和响应延迟,特别是在大规模知识库构建和信息检索中,可以极大程度提升经济型和效率。一般的应用包含以下几个部分:
典型应用流程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1642
1642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









