







 超级会员免费看
超级会员免费看

Embedding models · Ollama Blog

嵌入模型
2024年4月8日
Ollama 支持嵌入模型,使得构建结合文本提示与现有文档或其他数据的检索增强生成(RAG)应用成为可能。
什么是嵌入模型?
嵌入模型是专门训练以生成向量嵌入的模型:这些是代表给定文本序列语义含义的长数组:
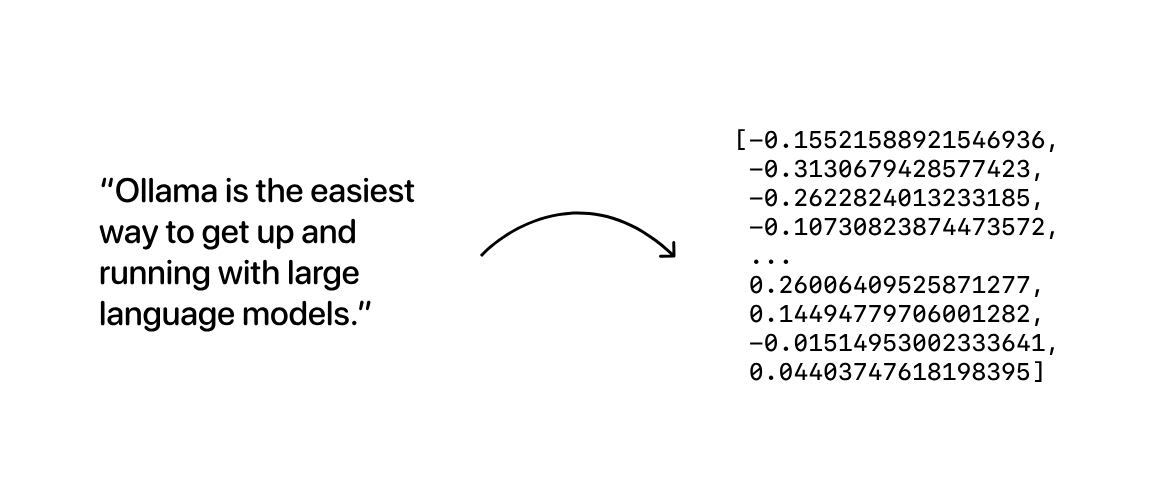
生成的向量嵌入数组可以存储在数据库中,该数据库会进行比较以搜索语义相似的数据。
示例嵌入模型
| Model | Parameter Size | |
|---|---|---|
mxbai-e |
Embedding models · Ollama Blog
2024年4月8日
Ollama 支持嵌入模型,使得构建结合文本提示与现有文档或其他数据的检索增强生成(RAG)应用成为可能。
嵌入模型是专门训练以生成向量嵌入的模型:这些是代表给定文本序列语义含义的长数组:
生成的向量嵌入数组可以存储在数据库中,该数据库会进行比较以搜索语义相似的数据。
| Model | Parameter Size | |
|---|---|---|
mxbai-e |
 2647
3423
2647
3423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文























